






目录
3.2 量子最近邻(Quantum k-Nearest Neighbors)
第一章 引言
人工智能(AI)技术在过去十余年取得飞速发展,尤其以深度学习为代表的机器学习模型在计算机视觉、自然语言处理、医疗健康和金融分析等领域屡创佳绩。然而,这些模型的训练和推理对计算资源的需求呈爆炸式增长。摩尔定律驱动的传统芯片性能提升正逐步逼近物理极限,高端GPU集群训练数百亿参数的模型需要耗费巨额时间和算力,仅有少数科技巨头能够承担如此代价。计算瓶颈使得AI领域亟需寻找新型计算范式来突破性能壁垒并加速创新。量子计算(Quantum Computing)的兴起为此带来了曙光。量子计算以其独特的量子力学机制(如叠加、纠缠等)能够以全新方式处理信息,被寄望于显著提升对复杂问题的求解效率。早在上世纪80年代,物理学家费曼(Richard Feynman)就提出用量子系统模拟自然过程的设想,并由此催生了量子计算的概念。2019年谷歌公司实现了首次“量子优越性”演示,利用一台53量子比特的超导量子处理器在特定问题上超越了当时最强超级计算机的性能,引发全球关注。一系列量子算法也展现出相对于经典算法的潜在突破:例如Shor算法能在多项式时间内完成大整数分解,而经典算法对此问题尚无高效解法;Grover算法可将无结构数据库搜索的时间复杂度从O(N)平方级加速至O(√N)。
随着量子硬件和算法的进步,“量子人工智能”(Quantum AI)作为量子计算与人工智能的交叉融合领域,正迅速崛起成为学术界和产业界的新热点。通过将数据映射到量子态空间并利用量子并行性,量子AI系统有望以更高效的方式完成模式识别、最优化等AI任务,在某些场景下获得超出经典AI的性能提升。这种范式融合不仅有助于突破经典计算的算力天花板,也为探索更接近自然原理的智能计算开辟了道路。各国科研机构与科技公司纷纷布局量子AI:如IBM、谷歌等投入巨资研发更大规模的量子芯片和相应的软件生态;初创企业和高校研究者也积极探索量子机器学习算法的新可能性。当下,尽管真正实用的量子AI尚处于萌芽阶段,但其巨大的潜在价值已经显现。本文旨在系统综述2025年前后量子人工智能领域的发展现状、核心理论与应用前景,内容涵盖量子计算与机器学习的基础知识、量子机器学习算法与量子神经网络结构、量子优化方法及典型应用,并结合国内外主要技术力量的布局解析量子AI相较经典AI的优势与挑战,最后展望量子硬件的限制与未来突破方向。希望通过本综述帮助读者全面理解量子AI这一交叉领域的理论进展与应用潜力。
第二章 基础知识
本章将介绍量子计算与人工智能的基本原理,并阐释二者融合的机理基础,为后续讨论量子AI方法打下理论背景。
2.1 量子计算基础概念:比特、量子比特与量子态
经典计算机的基本信息单元是比特(bit),每个比特在某一时刻只能取0或1两个离散状态。与此对应,量子计算的基本单元是量子比特(qubit),其状态由量子态向量表示,可以是基态、激发态
,也可以是二者的任意叠加,即$$|\psi\rangle = \alpha|0\rangle + \beta|1\rangle,$$其中
、
为复振幅,满足归一化条件
$$|\alpha|^2+|\beta|^2=1.$$
这种叠加原理(Superposition)意味着一个n比特经典寄存器在任意时刻仅能表示一个 n 位二进制数,而n个量子比特则可处于种基态组合的线性叠加态中,蕴含指数级并行的状态空间。此外,多个粒子的量子态可以出现经典所不具备的量子纠缠(Entanglement)性质:纠缠态中各量子比特的状态相互依赖,不可分割,即使远隔距离也能通过测量立即影响彼此。爱因斯坦曾将纠缠称作“鬼魅般的超距作用”,其非局域相关性为量子计算提供了超越经典的重要资源。
为了操纵量子比特的状态,需要使用量子门(Quantum Gate)。量子门是作用于一个或多个量子比特的可逆线性变换,通常由酉矩阵表示,常见的单比特门包括X门(翻转态0↦1)、H门(Hadamard门,将基态制备为等幅叠加态)等,两比特门如CNOT门可以实现比特间的纠缠。图2-1形象比较了经典比特和量子比特的状态表示。
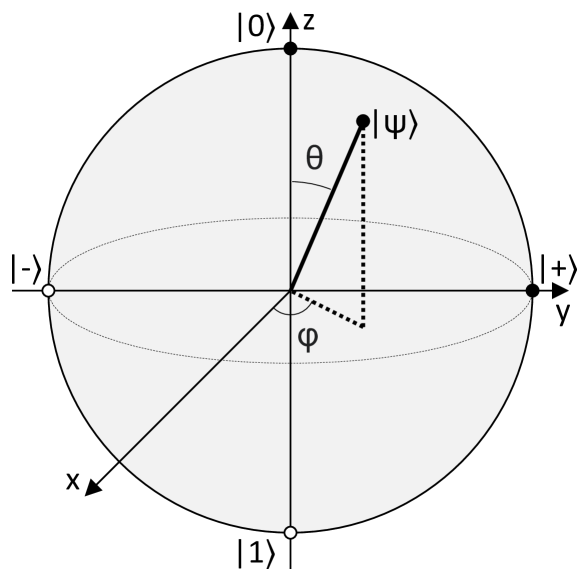
图2-1 经典比特与量子比特状态示意。左图:经典比特只能在0或1确定状态;右图:量子比特可处于的叠加态,其在布洛赫球面上表示为一点。(布洛赫球是单量子比特纯态的几何表示,球面上每点对应一个态矢,图中
、
为球坐标)
一系列量子门按一定顺序连接即可构成量子线路(Quantum Circuit),类似于经典电路将逻辑门串联以实现特定算法。量子线路中量子比特作为信息载体沿时间轴演化,经由门操作改变状态,最终在末端通过量子测量(Measurement)读出经典信息。测量会使量子态“坍缩”到某一基态,由量子力学的Max Born规则给出各结果出现的概率。需要注意的是,量子测量的结果本质上具有随机性,重复同样实验会产生概率分布符合量子态叠加系数的平方。这种随机性使量子计算不同于确定性的经典计算,需要多次测量取平均来获得期望值等信息。
量子计算的强大源于叠加和纠缠带来的并行性和空间结构,但其实现也面对巨大挑战。量子相干性(Coherence)要求量子比特在演化过程中与外界环境隔离,以防止信息丢失。然而实际硬件中,量子比特极易受环境扰动发生退相干(Decoherence),导致叠加态维持时间有限。此外,量子门操作和读出均有一定错误率,量子噪声是构建大型量子计算机的主要障碍。目前的量子硬件处于“噪声中等规模量子”(NISQ)时代,一般只能操纵数十到数百个物理量子比特,且无法实现完善的量子纠错(Quantum Error Correction)。因此NISQ设备能执行的电路深度有限,需要设计特殊的混合量子-经典算法来减轻硬件限制。这也是本章接下来介绍的量子机器学习等算法采取的基本策略。
2.2 人工智能与机器学习基础
人工智能的核心范畴之一是机器学习(Machine Learning),它研究让计算机通过数据学习规律,从而对未知数据做出预测或决策。经典机器学习包括监督学习(分类、回归)、无监督学习(聚类、降维)和强化学习等分支。近年来,深度学习(Deep Learning)蓬勃发展,其代表模型为多层人工神经网络(Artificial Neural Network)。深度神经网络由仿生学启发的多层“神经元”连接构成,通过大量样本数据训练调整网络中数以百万计的参数(权重和偏置),能够自动提取高维数据的深层特征并逼近复杂的非线性映射。例如卷积神经网络(CNN)在图像识别中能够逐层抽取边缘、纹理、形状等特征,达到超越传统算法的精度;循环神经网络(RNN)及其变种(LSTM、Transformer等)可以有效捕捉时间序列或自然语言中的长程依赖模式。深度学习模型通常采用梯度下降类优化算法进行训练,通过反向传播调整参数使损失函数下降,从而逼近给定训练数据的目标输出。值得注意的是,深度学习的突破在很大程度上得益于计算硬件的进步——特别是GPU等并行加速器使矩阵运算大幅提速。可以说,算力与数据是深度学习成功的关键支撑。然而,正如前文提及,随着模型和数据规模的不断扩大,经典硬件能提供的算力增长正逐渐跟不上AI模型的需求增速。因此,将全新的量子计算引入AI领域,有望为持续提升智能模型能力注入新的动力。
2.3 量子与AI的交叉机理
将量子计算应用于人工智能,首先需要解决如何将经典数据表示为量子态的问题。这通常通过量子特征映射(Quantum Feature Mapping)或量子数据编码(Quantum Data Encoding)来实现,即设计适当的量子线路将输入向量映射到多比特量子态,使得数据的关键信息以振幅或相位的形式存储于量子态空间。常见的编码方式包括:基态嵌入(将数据二进制编码到计算基态的0/1序列中),振幅编码(用数据值作为振幅系数填充归一化的量子态,可实现指数维度压缩但需要归一电路),角度编码(将特征值映射为旋转门的角度)等。不同编码方式在所需量子比特数和电路深度上有所差异,例如振幅编码一次即可加载维数据但需要复杂幅值初始化手段,而角度编码每个特征对应单独量子比特的一次旋转,简洁但可能需要更多比特。选择恰当的量子编码对于量子机器学习模型的表达能力至关重要。
在成功将数据映射到量子态空间后,量子计算可以提供独特的算力优势。其中一个主要思路是利用量子核方法。在经典机器学习中,支持向量机(SVM)等模型通过核函数将输入映射到高维特征空间,以在线性分类器中实现非线性判别。对应地,量子支持向量机(QSVM)使用量子特征映射由量子电路隐式地生成一个可能为经典计算难以高效表示的特征空间,再由量子计算器直接估计核矩阵,从而完成分类或回归任务。Havlíček等人2019年的研究首次证明了利用超导量子计算机实现这种量子增强型特征空间分类的可行性。量子核方法已在一些小规模数据集上展现性能媲美甚至略优于经典方法的迹象。例如,有研究用15比特超导量子处理器对乳腺癌良恶性肿瘤数据集进行分类,量子核SVM在部分配置下达到约0.93的AUC(曲线下面积),与经典SVM的0.89相当甚至略有提升(详见第三章相关讨论)。
除了核方法,另一个重要交叉方向是参数化量子电路学习,亦称量子神经网络(Quantum Neural Network, QNN)。其理念是构造含有可调参数的量子线路(例如旋转门的角度),让这些参数扮演类似经典神经网络权重的角色,通过优化参数使量子线路输出期望的结果。这种量子线路通常与经典优化算法结合:量子电路执行前向计算生成测量结果,经典计算机根据测量值评估损失并调整参数,反复迭代逼近最优。Mitarai等人在2018年提出了量子电路学习(Quantum Circuit Learning, QCL)框架,证明低深度的参数化量子电路在理论上具备逼近任意非线性函数的能力,并通过混合优化在当时可用的近邻量子设备上成功训练模型。这类变分量子算法的泛型结构与VQE(变分量子特征值求解)和QAOA(量子近似优化算法)一脉相承,也是下一章将详细讨论的重点。概括而言,量子与AI的交叉机制建立在:(1) 用量子态丰富的表示能力编码AI问题;(2) 利用量子叠加和纠缠进行并行信息处理;(3) 通过变分优化等手段训练量子模型逼近目标输出。随着量子硬件的进步和算法的改良,这种融合有望逐步展示出其相对于经典方法的独特优势。
第三章 量子机器学习方法
量子机器学习(Quantum Machine Learning, QML)指利用量子计算技术改进或实现机器学习任务的方法。本章选取几种具有代表性的量子机器学习算法,包括量子支持向量机、量子近邻算法和量子主成分分析等,介绍其基本原理和研究进展。
3.1 量子支持向量机(QSVM)
支持向量机是经典机器学习中强大的监督学习方法,依赖核技巧在高维特征空间中寻找最大间隔分类超平面。量子支持向量机通过量子核函数将数据映射到由量子态张成的特征空间,并利用量子计算机高效地计算核矩阵。其典型实现流程是:首先选择一套参数将输入x编码到量子态
中;然后通过量子电路计算不同样本态的重叠
,这一内积的平方即对应核函数
。量子电路可以在Hilbert空间中产生复杂的非线性映射,使得一些在经典SVM中难以分离的模式在量子特征空间中变得线性可分。Havlíček等使用超导量子处理器实现了2种量子核,并成功将QSVM用于小型数据分类任务。这类量子核SVM在低维医学和科学数据集上已展示出与经典SVM相当的性能,并有潜力在特定结构数据上实现加速或精度提升。表3-1给出一项研究中QSVM与经典SVM在两个实例数据集上的分类结果对比。可以看到,量子模型已能取得可竞争的准确率,这为QML迈向实用化提供了信心。
表3-1 不同算法在典型数据集上的分类AUC表现
| 数据集(特征维数) | 量子SVM(sqKSVM) | 量子SVM变体(qKSVM) | 量子分类器(qDC) | 经典SVM(cSVM) | 经典kNN(ckNN) |
|---|---|---|---|---|---|
| 骨髓移植生存预测(16维) | 0.66 | 0.69 | 0.64 | 0.71 | 0.64 |
| 乳腺癌良恶性分类(16维) | 0.88 | 0.93 | 0.90 | 0.89 | 0.93 |
注:表中指标为交叉验证下的AUC值(越接近1越好),量子算法在IBM Melbourne 15比特超导量子机上执行,经典算法在同等训练集上评估。乳腺癌数据可见量子SVM核方法达到0.93,略优于经典SVM的0.89,而骨髓移植数据两者相当。这表明在某些任务上量子算法已具备与经典方法竞争的能力。
需要指出的是,当前QSVM的优势多停留在理论或小规模实验上,实现对经典SVM的全面超越尚需更大规模无噪声量子资源。但QSVM作为量子机器学习的“杀手级应用”之一,其继续发展前景被普遍看好。例如,有研究提出变分量子SVM(VQ-SVM)框架,通过在量子电路中优化核矩阵的特定参数以减小噪声影响并提升泛化能力。随着量子设备的成熟,QSVM有望在生物信息、物理实验数据分析等领域展现出独特价值。
3.2 量子最近邻(Quantum k-Nearest Neighbors)
k近邻(kNN)算法是一种直观的非参数模型,通过比较距离来预测新样本类别。量子版本的kNN试图利用量子并行计算和幅度放大等技术加速相似度计算和近邻搜索。基本思路是在量子计算机中准备包含训练样本和待分类样本的叠加态,通过量子幅度估计或Grover搜索等算法直接定位距离最近的k个邻居。从理论上,若能高效实现数据的量子存取和距离计算,量子kNN可将基于线性扫描的距离计算速度从O(N)降低到级别。例如,研究者提出利用量子态内积计算样本间相似度,并通过幅度放大技术对比距离。也有方案将训练集编码为量子存储结构,通过量子游走遍历寻找近邻。然而,实际实现量子kNN仍面临数据加载和量子存储等瓶颈。目前文献多在模拟环境下测试小规模量子kNN,对真实量子硬件的实验很有限。尽管如此,一些初步结果表明量子kNN在图像分类等任务上有潜力达到与经典kNN相当的准确率,同时在理论上保有速度优势。一项图像分类实验显示,量子kNN在MNIST手写数字数据的子集中达到约95%的识别率,与经典kNN相当,但由于采用并行的量子距离计算,算法复杂度有降低趋势。这类探索证明了量子近邻搜索的可行性,也凸显了量子随机存取存储器(QRAM)等配套技术的重要性——只有解决数据高效读入,量子kNN的理论加速才能真正转化为实际效果。
3.3 量子主成分分析(Quantum PCA)
主成分分析(PCA)用于从高维数据中提取方差最大的正交方向,以降维和数据压缩。量子版本的PCA由Lloyd等提出:给定数据的协方差矩阵,利用量子相位估计算法可以在
时间内估计其特征值和特征向量(即主成分),较经典PCA的
时间复杂度有指数级加速潜力。其基本流程是:首先构造归一化的量子混合态
$$\rho = \frac{1}{N}\sum_{i=1}^N|x_i\rangle\langle x_i|,$$
其中为归一化数据点;然后通过量子相位估计对单一的
求本征分解,可得到
的本征值(与协方差矩阵特征值相关)和对应本征态即主成分方向。量子PCA能高效地提取数据主成分信息,对于高维数据压缩具有吸引力。然而,它要求能够制备上述混合态
并施加其指数演化算符,这在NISQ条件下依然困难。此外,量子PCA得到的是特征向量的量子态拷贝,如何有效提取出具体数值也有挑战。一些改进方案尝试结合变分方法近似地找到前几个主成分方向,以减少对量子相位估计的依赖。有模拟实验表明,变分量子PCA在小数据集上能正确识别主要成分方向。尽管目前规模有限,量子PCA仍被视为在大数据降维分析中可能取得指数级提速的典型算法之一,其未来的实现有赖于更强的量子线路容错能力和大规模量子态制备技术的发展。
总的来说,量子机器学习方法的研究方兴未艾。除上述算法外,量子聚类、量子贝叶斯分类、量子生成模型(如量子GAN)、量子增强强化学习等各方向均有报道。当前,这些量子算法多数还局限于理论分析或小规模验证,其在实际任务中的效果往往受限于噪声和规模。但可以预见,随着量子硬件性能提升和算法改进,一旦进入容错量子计算时代,这些量子机器学习算法有可能在某些特定任务上表现出对经典算法的显著优势。
第四章 量子神经网络架构及其训练
4.1 量子神经网络的概念
量子神经网络(Quantum Neural Network, QNN)试图将深度学习的神经网络架构引入量子计算领域,构建可训练的量子电路来模拟神经网络的行为。广义上,任何含可调参数且通过训练优化的量子电路都可称为量子神经网络。根据实现形式的不同,QNN大致可分为两类:一类是变分量子电路(Variational Quantum Circuit)模型,直接用参数化量子门阵列作为模型,由经典优化器训练参数;另一类是量子模拟经典网络的模型,试图定义“量子神经元”或“量子层”来模拟经典网络的结构,例如量子感知机、量子卷积层等。
目前主流的QNN研究多聚焦于变分量子电路模型。其基本结构一般包含三部分:数据编码层、多个包含可调参数的量子门的层(类似神经网络的隐藏层),以及测量输出层。数据编码层负责将输入x映射为初始量子态(如第二章介绍的各种编码方式)。随后,参数化的量子门阵列
作用于该初始态,将其演化为输出态
。最后对输出态进行测量,得到可用于定义损失函数的期望值或概率分布。例如,可测量某一算符M的期望
作为模型对输入x的预测。训练时,通过多次量子电路运行得到损失函数关于参数的梯度信息,利用经典优化方法(如梯度下降、进化算法等)迭代更新参数
,直至收敛。
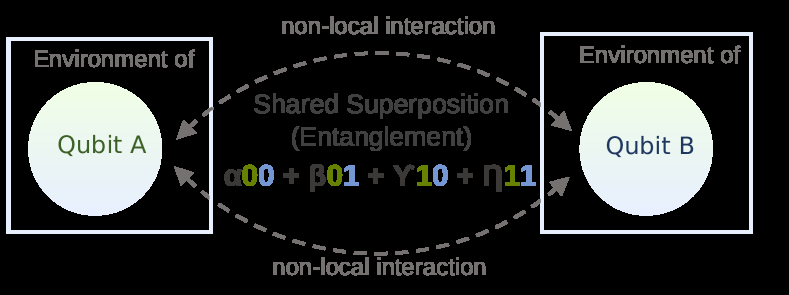
图4-1 两比特纠缠作用机制示意图(量子神经网络常利用纠缠门在比特间引入关联)。左、右两框分别表示量子比特A和B所在的环境,虚线椭圆代表非局域纠缠产生的共享叠加态,对任意一比特操作会影响另一比特。纠缠机制赋予QNN处理多体关联的天然优势,但实现高质量纠缠也对硬件稳定性提出了高要求。
上述训练框架类似于经典神经网络的反向传播,只是这里损失关于参数的梯度需通过量子电路估计。幸运的是,对于许多参数化量子电路,存在有效的参数偏移法来计算梯度,只需运行两次稍作偏移的电路即可得到精确梯度,从而无需复杂的量子线路微分技术。这使得在当前NISQ硬件上训练小规模QNN成为可能。
4.2 量子神经网络的典型架构
不同任务需要设计不同结构的QNN。借鉴经典深度学习,研究者提出了多种针对性的量子网络架构。例如,量子卷积神经网络(QCNN)将参数化量子电路与逐层测量相结合,实现类似经典CNN的局部感受野和参数共享结构,可用于对量子态或图像数据的分类。Cong等人在2019年设计的QCNN用于辨识量子相变,展现出比经典CNN更高的噪声鲁棒性。又如,量子循环网络尝试利用量子叠加实现并行的时间序列处理,或用量子存储单元代替LSTM的记忆单元。目前这方面研究还处于初级探索。
另一值得关注的架构是量子玻尔兹曼机(QBM)及量子受限玻尔兹曼机(QRBM)。玻尔兹曼机是经典生成模型,通过能量极小化学习数据分布。D-Wave量子退火机非常适合求解伊辛模型的基态,因此可用来训练受限玻尔兹曼机的权重。Amin等在2018年利用量子退火实现了小规模QBM训练,生成模型在简单数据上表现出比经典随机梯度下降更快的收敛。虽然量子退火不属于门模型量子计算,但其在优化抽样上的特长可以视为特殊的QNN架构,有望应用于生成模型和概率图模型领域。近期也有工作将门模型QNN与经典玻尔兹曼机结合,提出量子混合玻尔兹曼机以改进训练效果。
4.3 QNN的训练难点与对策
量子神经网络在训练过程中也暴露出一些独有的挑战。一是著名的平原问题(Barren Plateau):当电路深度或比特数较大时,损失函数关于参数的梯度期望值可能指数级逼近零,导致训练停滞。这是由于高维量子参数空间中随机初始化时大概率落入“平坦”区域,使得经典优化器无法指引方向。目前的应对思路包括使用有物理动机的浅层电路初始点、分块训练局部电路、借助代理模型预测梯度等。二是噪声的影响:量子门和读出误差会扭曲梯度估计,使训练过程更不稳定。一些研究提出结合量子误差缓解技术,以及在训练目标中显式加入噪声模型的思路,提升QNN训练鲁棒性。三是过参数化:与经典网络类似,QNN参数过多也可能过拟合训练数据,如何选择适当的电路深度与结构以实现良好泛化也是研究课题。
尽管有上述困难,已有多个实验验证了QNN在小规模任务上的可行性。例如,杜克大学的团队在离子阱量子计算机上训练了6比特的QNN,实现对简单手写数字的分类,测试准确率超过90%。另有研究在IBM超导量子机上训练4比特QNN用于二分类,获得与对应的浅层经典网络相当的表现。这些成果证明了QNN的可训练性和潜在实用价值。可以预见,随着硬件升级和训练策略改进,QNN规模将逐步扩大,有望在语音识别、强化学习等需要大状态空间建模的领域展现独特优势。
第五章 量子优化方法在AI中的应用
许多AI问题可以形式化为优化问题,例如机器学习模型训练本质上是损失函数的最小化,组合优化在任务分配、路径规划中广泛存在。量子计算提供了一系列新颖的优化算法,有望加速或改善AI相关的优化过程。本章介绍两类重要的量子优化方法:量子近似优化算法(QAOA)和变分量子特征值求解(VQE),并讨论它们在AI中的潜在应用。
5.1 量子近似优化算法(QAOA)
QAOA由Farhi等在2014年提出,旨在利用量子计算求解典型的NP-hard组合优化问题。其思想来源于量子退火和扰动理论:通过交替应用问题哈密顿量和混合哈密顿量的指数演化若干轮次(通常称为$p$层),产生一族参数化量子态,然后使用经典优化器调整参数
使得态的期望目标函数值最小。以Max-Cut问题为例,QAOA首先构造代表图割大小的伊辛哈密顿量
及均匀叠加初始态
,然后交替施加
和
(其中
通常取所有比特的X磁场
)p轮,最后测量得到近似解。对于足够大的p,QAOA理论上可逼近最优解;即使p较小,其输出态往往已经给出质量良好的近似解。QAOA具备天然适配NISQ设备的优势:电路浅、门序结构简单(交替的乘积形式)且容易结合经典反馈。近年来QAOA成为量子组合优化研究的焦点,也被用于AI领域相关的问题。例如,在机器学习中的特征选择、聚类等问题可表述为某种离散优化,此时可尝试用QAOA求解。在图神经网络的一项研究中,学者将节点划分问题通过QAOA优化求解,取得了比经典启发式更优的解。又如在强化学习中,有工作尝试用QAOA寻找最优策略,初步结果表明在小规模环境下量子策略优于经典策略。在硬件实践方面,QAOA已被运行在多种量子处理器上用于求解玩具问题。总体而言,QAOA为将量子计算优势引入AI优化任务提供了一个通用框架,未来随着设备能力增长,其在更复杂AI问题上的表现值得期待。
5.2 变分量子特征值求解(VQE)
VQE最初作为量子化学领域的重要算法,用于计算分子哈密顿量的基态能量。它也是一种量子-经典混合优化方法,与QAOA形式类似但目标不同:QAOA关心组合优化的离散变量,而VQE针对连续变量的量子态能量优化。VQE通过选取一个带参数的ansatz量子态(通常由某种带有物理启发的电路生成,如UCC单元等),然后用量子电路估计
作为代价函数,并由经典优化器调节参数
使代价(能量)下降。由于基态能量是能谱中的最小值,根据变分原理VQE最终输出的能量即为基态能量的一个上界。VQE框架可以推广到广义的参数优化问题。例如,将机器学习模型的损失函数对应的哈密顿量H映射到量子态的期望计算,则优化模型参数的问题就转化为了用VQE寻找某态的最低期望值问题。有研究提出QVAE(量子变分自动编码器)等模型,本质上就是在VQE框架下优化一个结合量子电路与经典网络的混合损失函数,以训练生成模型。又比如在神经网络训练中,若将损失函数表示为一系列观测值的加权和,也可以考虑构造相应哈密顿量,然后用VQE方法最小化它。当然,这种应用尚处概念验证阶段。相比QAOA主要关注离散组合问题,VQE更适合处理连续变量或需要高精度数值的优化,例如量子化学分子模拟以及某些金融风险评估(可建模为求哈密顿量最低值的问题)。目前,VQE已被广泛用于模拟小分子的基态能量,实验精度不断提高。经典模拟难以处理的中等分子(如~10量子比特对应的简化氮分子)已经能通过VQE在量子硬件上获得较为准确的基态能量估计,其误差在化学精度(约1 kcal/mol)量级内。尽管在AI中的应用还处于探索阶段,VQE展示的强大变分优化能力为解决某些AI优化难题提供了全新思路。
综上,量子优化算法通过将AI问题转换到量子态或哈密顿量优化的框架,提供了一条拓展AI算力的可行路径。在近期,QAOA更适合求解组合型的AI优化任务(如离散超参数优化、NP-hard结构搜索等),而VQE则为连续域优化和精细求解提供了工具。值得一提的是,量子退火技术作为模拟量子优化的硬件实现,也已被用于一些机器学习优化中并取得进展。例如大众公司利用D-Wave退火机实现实时交通流优化,在里斯本试点让公交线路拥堵时间大幅下降。这种成功案例证明了量子优化在实际场景中助力AI决策的潜力。展望未来,随着量子比特数和相干时间的提升,量子优化方法有望处理更复杂的AI训练与推理优化问题,为经典AI难以企及的性能提升打开大门。
第六章 国内外量子AI产业布局与案例
量子人工智能的迅速升温吸引了各国主要科技公司和研究机构的目光。本章将盘点国内外主要科技巨头和研究力量在量子AI方向的布局、案例与战略,包括Google、IBM、D-Wave等国际公司,以及百度、华为、阿里等中国机构的现状。
6.1 Google(谷歌)
谷歌在量子计算和AI两个领域均处于领军地位,自然将两者融合作为重点方向。谷歌早在2014年就成立了Quantum AI实验室,致力于超导量子计算硬件研制和量子算法开发。2019年谷歌利用53比特超导芯片Sycamore实现了量子优越性里程碑。在量子AI方面,谷歌的战略是“双管齐下”——一方面继续扩大量子硬件规模,开发容错量子计算所需的纠错技术,计划在2025年前后实现百万量子比特的逻辑量子计算原型;另一方面推出量子机器学习软件框架(如TensorFlow Quantum),方便研究者将量子电路嵌入现有AI模型中进行试验。谷歌的研究团队发表了一系列量子机器学习论文,例如量子卷积网络用于量子相分类、混合变分算法用于化学分子模拟等,展示了量子AI的潜力。值得关注的是,谷歌强调量子计算与经典高性能计算融合的策略,提出未来的云服务将把量子处理单元(QPU)作为加速器,通过API供AI任务调用。这与谷歌在传统AI中使用TPU加速深度学习的思路一脉相承。目前,谷歌量子AI团队也在尝试用AI优化量子控制和纠错方案,属于“AI for Quantum”的方向。例如,他们使用强化学习来设计更稳定的量子门序列,用深度神经网络辅助量子态断层重构等。总体而言,Google正将其在AI软件和量子硬件的优势相结合,目标是在未来实现具有实用价值的量子机器学习加速器。
6.2 IBM
IBM是量子计算产业化最积极的推动者之一,也非常重视量子计算和AI的结合。IBM于2016年推出了云上的IBM Quantum Experience平台,开放5比特量子机供公众使用。此后几年IBM量子处理器的比特数稳步提升:2019年发布27比特Falcon芯片,2020年65比特Hummingbird,2021年127比特Eagle,2022年433比特Osprey,2023年实现了1121比特的Condor,首次突破千比特大关。

图6-1 IBM 433比特“Osprey”量子处理器内部结构示意(分层剖面图)。Osprey芯片采用多层布线技术,将读出控制线分层安置以减少对量子比特的干扰,从而实现比前代127比特Eagle芯片高出3倍以上的集成度。IBM计划在2025年后继续扩展量子芯片规模,并同步提升量子体积等综合性能指标。
在量子AI方面,IBM主要通过提供丰富的软件工具和案例来推动生态发展。IBM开源了Qiskit框架,其中专门的Qiskit Machine Learning模块包含量子SVM、量子神经网络等实现,方便开发者调用。IBM还与多家科研机构合作探索量子机器学习应用,例如用变分量子电路预测化学反应速率、用量子优化算法解决金融投资组合问题等。IBM研究院发表的一些报告指出,在某些优化和仿真任务上,NISQ设备已经可以与经典算法性能相当。战略层面,IBM非常强调量子实用性(Quantum Utility)概念,认为应寻找那些在现有中等规模量子机上就能比经典实现有所裨益的AI问题。2023年,IBM宣布首次在100多比特量子处理器上执行的量子电路无法被经典超级计算机模拟——这被视为迈向实用量子计算的重要一步。此外,IBM积极构建产业合作网络,吸引金融、材料、物流等行业伙伴共同开发量子AI应用原型。例如,与摩根大通合作研究量子算法在期权定价中的应用,与奔驰公司探讨量子优化用于电池材料设计等等。总体而言,IBM通过硬件路线图+软件生态+行业合作的全方位布局,推动量子AI从实验室走向实际应用。
6.3 D-Wave
D-Wave是来自加拿大的量子计算公司,以其量子退火式计算机闻名。尽管D-Wave的量子退火不同于通用门模型,但在优化类问题上具有独特优势。D-Wave较早探索将量子退火用于机器学习模型训练。例如,早在2017年D-Wave与Google等合作尝试用量子退火训练玻尔兹曼机,用于生成手写数字图片。D-Wave当前最先进的退火机是5000+比特的Advantage系统,具有每比特15个连接的复杂耦合网络。许多组合优化问题(如图着色、旅行商问题)都可映射到退火机的伊辛模型上求解,机器学习中一些困难问题也可如此处理。例如,特征选择问题可视作在所有特征子集里寻找最优组合的离散优化,已有人将其转化为QUBO(二次无约束二进制优化)形式利用D-Wave求解,并在小数据集上获得与穷举相同的结果但速度大幅提升。D-Wave还提供了混合求解器,将经典算法与量子退火结合,解决诸如大规模图优化等问题。实际案例方面,大众公司与D-Wave合作于2019年演示了实时交通优化:利用D-Wave为里斯本市9辆公交车动态规划最优路线,成功减少了高峰期乘客的通勤时间。这是全球首例量子计算用于实际城市交通调度的案例,证明了D-Wave系统在特定AI应用中的实用性。D-Wave当前策略是一手继续改进退火硬件性能(如开发新的Advantage2系统提高耦合密度与降低噪声),一手推出兼容门模型的量子计算云服务,以满足更广泛的算法需求。值得注意的是,D-Wave也将AI视为重要市场,宣称其量子计算已在机器学习应用(包括图像分类、流量优化等)中展现出早期价值。未来,随着退火算法与机器学习的进一步融合,D-Wave有望在特定AI领域提供差异化的量子加速解决方案。
6.4 百度
百度是国内最早投入量子计算研发的互联网企业之一。2018年3月百度正式成立量子计算研究所,经过数年发展,已经构建起软硬件全栈布局。2022年8月,百度发布了首台自主研发的超导量子计算机“乾始”(Qian Shi),搭载10个超导量子比特,并同步推出一体化量子软件平台“量羲”(Liang Xi)。乾始的发布标志着百度打通了从量子硬件、控制系统到云端应用的完整链条,实现了量子计算的软硬件融合。据介绍,乾始量子机采用了底层量子芯片、量子控制与测量软件以及高层应用框架三层架构,百度计划下一步研制36比特芯片。在软件方面,百度先后推出了云端量子脉冲计算服务“量脉”、量子机器学习平台“量桨”(基于百度深度学习框架飞桨PaddlePaddle)、云原生量子计算平台“量易伏”等一系列自主平台工具,将量子计算与AI深度结合,降低开发者使用量子计算的门槛。百度的量子机器学习研究涵盖量子强化学习、量子线路架构搜索等方向,并与清华、中科院等学术单位合作发表多篇论文。应用案例方面,百度Quantum研究团队曾展示用量子机器学习算法进行简单图像分类、量子化学计算等演示,验证了其平台的可用性。百度还积极参与国家量子信息项目,是国内推动量子AI应用的重要力量。然而,2024年初有消息称百度计划调整量子研发布局,将量子计算业务相关的实验室和设备捐赠给北京量子信息科学研究院(BAQIS)。这一举措被视为百度在量子计算投入上的战略收缩,可能是出于聚焦核心AI业务和优化资源配置的考虑。尽管百度短期内缩减了量子硬件投入,但其在量子软件和量子AI算法上的积累仍在继续。未来不排除百度通过与国家研究机构合作等方式,继续在量子AI领域保持影响力。
6.5 华为
作为通信和ICT行业巨头,华为在量子技术方面的布局主要聚焦于量子通信、安全和计算基础研究。华为2017年起设立了“战略研究院量子实验室”,关注量子密钥分发、量子密码等安全领域,并有部分工作涉及量子计算硬件的预研。2020年华为发布量子计算模拟器HiQ,以及量子编程框架HiQ Programming Platform,支持开发者在经典计算资源上模拟量子算法https://thequantuminsider.com/2022/06/20/huawei-files-patent-for-quantum-chip-computer/#:~:text=It%E2%80%99s%20not%20the%20first%20time,system%2C%20method%2C%20and%20device%E2%80%9D%20patent。这被视为华为为积累量子软件经验所做的准备。2021年华为申请了一项“量子计算芯片和计算机”相关专利,提出通过多芯片模块提升量子芯片良率的设计思路。该方案将大规模量子处理器分割成较小子芯片,通过耦合结构连接,实现可扩展的模块化量子计算架构。这一专利显示华为在量子硬件设计上有所探索,意图克服当前单芯片集成规模受限的瓶颈。华为还参与了国内量子标准制定工作,牵头了量子安全通信、量子随机数等行业标准的制定。在量子AI方面,华为暂未公开专门的产品或平台,但可以预见其将关注量子计算对大数据分析、通信网络优化等与其主营业务相关的AI问题的帮助。例如,用量子优化算法改进通信网络路由、用量子机器学习增强信号处理等,都是潜在方向。总体来说,华为对量子计算采取了未雨绸缪的策略:通过研究专利和标准积极跟进行业演进,以便在量子技术成熟时迅速将其融入自身产品(如量子安全通信设备、云服务等)。鉴于华为在AI应用和芯片研发上的深厚实力,如果量子计算取得突破,华为有望将量子AI作为强化其ICT解决方案的新卖点。目前华为正静待量子计算的商业临界点,同时通过小规模研发保持技术储备。
6.6 阿里巴巴
阿里巴巴于2015年携手中科院成立了阿里云量子实验室(也称“阿里巴巴-中科院量子计算实验室”),是国内最早投入量子计算研究的企业之一。阿里量子实验室曾在超导量子芯片、量子云服务等方面开展工作,还对外开放了11比特量子计算云平台供开发者试用,成为全球最早提供云上量子计算服务的厂商之一。不过,2023年11月有报道指出,阿里巴巴决定关闭其量子计算实验室,将相关团队和设备整体捐赠给浙江大学。https://www.reuters.com/technology/alibabas-research-arm-shuts-quantum-computing-lab-amid-restructuring-2023-11-27/#:~:text=SHANGHAI%2C%20Nov%2027%20%28Reuters%29%20,the%20company%20said%20on%20Monday阿里达摩院发言人表示,未来将聚焦于核心AI研究,并对包括量子计算在内的非核心业务进行战略评估。2024年初,IEEE Spectrum分析称阿里和百度先后退出量子竞赛,可能意味着中国量子计算研发由大型科技公司转向由政府主导的科研机构为主。需要注意的是,阿里的退出并不代表其量子技术完全中止。事实上,阿里将实验室捐给高校,或许是希望借助学术力量延续研究。阿里云曾在2018年宣布研制量子加速器用于增强云计算能力,阿里安全团队也关注后量子加密算法,以应对未来量子计算对加密算法的威胁。综合来看,阿里的量子AI布局曾经走在国内前列,但现在策略调整为暂缓自研、观望合作。可以预期,若将来量子计算迎来实用拐点,阿里仍可能通过投资收购或合作迅速重返赛道,毕竟其在云计算和AI应用上拥有庞大市场,一旦量子技术成熟,能够很快找到应用场景实现商业价值。
6.7 其他力量与综合分析
除上述公司外,微软、英特尔、谷歌DeepMind、亚马逊等国外科技巨头,以及清华大学、中科大、本源量子等国内高校与初创企业也在积极探索量子AI。微软主攻拓扑量子计算,同时开发了Quantum ML工具;英特尔致力于硅自旋量子点硬件的同时,支持量子算法研究;DeepMind等AI公司也开始涉足量子强化学习、量子模拟器开发等方向。值得一提的是,中国的科大国盾、本源量子等初创在量子计算机研制上取得进展,如本源量子2023年发布72比特超导量子芯片“悟空”,显示出国内科研力量的雄厚。政策层面,各国政府纷纷将量子科技上升为国家战略,美国、欧盟、中国均有量子专项规划。在量子AI方向,政府资助的项目正推动产学研合作,例如欧盟的Quantum Flagship中就包含Quantum Machine Learning课题,中国的“量子计算机研制”国家项目也支持量子算法与应用探索。总体判断,量子AI的发展正处于科技巨头、初创团队和学术机构多元参与的格局:巨头提供资源和应用场景,初创专注技术攻关,学术机构贡献基础理论,三方协作推动量子AI逐步走向成熟。
第七章 量子AI对比经典AI:优势、差异与挑战
量子人工智能作为新兴交叉领域,人们自然关心它究竟能带来哪些超过经典AI的优势,又面临哪些特有挑战。本章从性能、复杂度、可扩展性等方面比较量子AI与经典AI,并分析当前量子AI发展的瓶颈。
7.1 算力与性能差异
量子AI相较经典AI最显著的潜在优势在于指数级并行计算能力。经典AI即使能并行化,也需要线性增加算力来处理更多数据或更高维特征;而量子AI利用n个量子比特即可同时表达种状态组合,在原理上适合处理维数灾难等问题。例如,经典神经网络若要表征
种模式可能需要指数级参数,而一个n比特量子态天然处于
维希尔伯特空间,可线性组合产生丰富的模式叠加。这意味着在某些复杂模式分类或高维数据分析任务中,量子模型或许能够更加紧凑地表示决策边界或数据分布。同时,量子纠缠提供了一种经典网络难以模拟的关联机制,可用于构造更高效的特征表达。例如,在某些需要捕捉全局相关性的任务(如分子属性预测),量子态的整体演化或比经典局部运算更有优势。然而,目前这些优势多停留在理论或小规模试验:受限于量子比特数量和噪声,现阶段量子AI模型的规模和精度大多尚未超越最先进的经典AI模型。实际比较中,小型量子模型(几十参数)往往只能达到与相应规模的经典模型相当的性能。只有在未来量子比特数大幅增加、纠错实现后,量子AI才有机会在复杂任务上表现出压倒性性能超越。例如,对于某些组合优化或结构搜索问题,量子算法理论上可在指数级更少的步骤内找到更优解,那时量子AI的优势将十分明显。
7.2 训练复杂度与数据高效性
量子AI的训练在复杂度上也与经典AI有所不同。一方面,参数空间维度:经典深度学习模型参数动辄千万以上,梯度下降每步复杂度和数据量线性相关,而量子电路参数相对较少(目前几十到几百个),这使每轮迭代需要的调整量较小。但是由于量子测量的随机性,评估梯度需要重复电路执行多次以降低噪声,增加了训练开销。另一方面,数据喂入是量子AI训练的瓶颈之一。经典AI可轻松读取海量数据,但量子AI必须将数据转换成量子态,这往往需要O(n)甚至O(n\log n)时间,对大样本训练而言可能成为瓶颈。例如,加载百万维特征的经典神经网络只是读取数组,而量子电路准备一个百万维叠加态需要复杂的门序列甚至特殊硬件(如QRAM)的支持。此外,量子态只可通过测量获取有限信息,训练时不能像经典那样自由读取中间激活值。必须通过设计观测算符来提取梯度等信息,这加大了训练复杂度。总的来说,在小规模下量子模型参数更少、并行性更高,可能较经典更“数据高效”——一些研究发现量子模型在小样本学习中表现出更强的表示能力,用较少数据达到同等精度。但在大数据训练下,量子AI是否能胜出仍未可知。要充分发挥量子并行性,需要突破数据读入与测量瓶颈,这是量子AI训练复杂度上的关键挑战。
7.3 模型可扩展性与泛化
经典AI模型可以通过增加神经元、层数等方式扩展,依赖的是成熟的GPU/TPU集群和分布式训练框架。而量子AI模型要扩展,面临量子硬件扩展这一更严峻问题。当前最先进的超导量子芯片实现了千比特左右(如IBM Condor 1121比特),但其有效纠错后的逻辑比特数远低于物理比特数。想象一个媲美经典神经网络的量子网络可能需要上万逻辑比特和长深度电路,实现起来极为困难。量子系统扩展还受到噪声指数累积的限制,没有纠错时电路一深就会淹没于噪声。这使得目前量子AI模型只能探索浅层、小规模结构,模型容量有限。另一方面,量子模型的泛化能力目前还缺乏系统研究。一种观点认为,量子模型由于在希尔伯特空间有更大的表示能力,可能更容易过拟合,需要谨慎正则化;也有人提出纠缠等机制赋予模型对全局模式的把握,反而有助于泛化。现有实验尚无定论。在无噪声理想情况下,量子模型与经典模型的函数逼近能力大致等价(任意量子电路可由经典网络模拟,反之亦然,只是效率不同)。因此,泛化能力更多取决于模型结构和训练策略,而非量子或经典身份。不过,噪声的存在在一定程度上相当于对量子模型施加了随机正则,这可能会影响泛化特性。有研究者观察到,适度的量子门噪声反而能避免量子电路过拟合训练数据,提高测试表现。这类似经典网络中加入噪声或dropout的正则效果。但噪声过强则会毁损模型表示能力,使训练陷入瓶颈。
7.4 当前量子AI的主要挑战
归纳而言,量子AI要真正超越经典AI,必须克服以下几项重大挑战:其一,硬件有限和噪声问题。没有足够规模和低噪声的量子硬件,量子AI的潜力无法充分发挥。当前NISQ设备很难执行大于百深度的电路,这限制了复杂模型的实现。为此,短期需发展更好的量子误差缓解技术,以及探索适应NISQ的算法结构(如浅层随机巡游电路等)。长期看,量子纠错的突破才是根本解决之道。一旦可构建稳定运行的大规模逻辑量子比特阵列,量子AI模型才能自由扩展。其二,软件与算法生态尚不成熟。经典AI领域有成熟的框架(如TensorFlow、PyTorch)和大量优化技巧,而量子AI的软件工具还在起步。虽然Qiskit、Pennylane等框架提供了基本组件,但离大规模易用还有差距。此外,量子AI算法本身也需要更多创新。例如,设计专为量子架构优化的网络结构、发明鲁棒的量子训练算法、找到适合量子求解的新AI问题等。其三,人才与知识断层。要驾驭量子AI,需要既懂量子物理又通晓机器学习的复合型人才。这方面人才稀缺,研究者往往擅长其中一端,对另一端理解不足,导致一些尝试未能达到预期效果。为此,学术界和产业界都开始重视交叉培养,如开设量子机器学习课程、举办研讨会等,以弥合知识差距。
尽管如此,我们有理由保持审慎的乐观。历史经验表明,新技术从概念到超越往往需要时间。例如经典神经网络在理论提出后沉寂几十年,直到算力和数据成熟才厚积薄发。量子AI目前就类似90年代的神经网络,概念验证已有,离真正实用还需外部条件成熟。在量子计算硬件发生质变的时刻,量子AI的优势可能会迅速涌现。一旦数百乃至上千逻辑比特规模可用,量子AI或将在某些任务上远超最强经典AI模型,正如人们期待的那样实现“质的飞跃”。
第八章 主要应用领域分析
量子人工智能作为工具,最终价值要通过应用体现出来。尽管现阶段离大规模商用尚有距离,但一些前沿探索已显示量子AI在特定领域的潜在应用前景。本章选取若干关键领域,分析量子AI可能产生的影响和已有进展。
8.1 化学模拟与新材料设计
这是被广泛认为最有希望率先实现量子优势的领域之一。分子和材料的性质由量子力学主宰,经典计算在模拟分子电子结构时往往遇到指数复杂度困难。量子计算天然适合模拟量子体系,量子AI可以辅助发现新分子、新材料。例如,量子变分算法(如VQE)已用于计算简单分子的基态能量,并在小规模上达到化学精度。未来,通过量子神经网络处理更多电子关联,或用量子强化学习指导分子结构搜索,可能更快发现高效药物分子或新型催化材料。量子AI还能用于材料属性预测:比如构建量子卷积网络来分类材料的拓扑相、超导性等属性,比经典方法更直接地处理量子相干特征。总体而言,化学与材料科学是量子AI最直接契合的应用,因为问题本身就是量子体系,量子计算可更准确逼近答案。一旦数百逻辑比特量子机可用,可能首先在中等分子模拟上击败经典化学计算。
8.2 金融科技与优化决策
金融领域充斥着复杂的优化与预测问题,如投资组合优化、期权定价、风险分析等。量子计算的并行和随机性可为金融模型提供新思路。例如,投资组合优化可抽象为带约束的组合最优化,量子QAOA和退火非常适合此类问题,有望找到更优的资产配置方案或更快达到次优解。丰业银行等已尝试用量子退火求解小规模投资组合问题,结果表明量子算法能在逼近最优解质量上与经典遗传算法竞争。期权定价方面,量子算法可加速蒙特卡洛模拟:利用量子叠加产生大量路径并通过振幅估计计算期权价格,其理论收敛速度优于经典Monte Carlo。这被称为量子算法金融模拟(Quantum Monte Carlo),若误差,经典需要
仿真步数,而量子只需
。一些初步实验已在模拟环境下验证了小型振幅估计算法。交易策略优化也可以借助量子强化学习来平衡收益风险。瑞士信贷等机构投入研究量子机器学习在股票走势预测、信用风险评估中的应用,希望借助量子核方法挖掘更高维的关联。目前金融是量子计算创业公司重点开拓的领域之一,因为相对而言很多金融问题可以在中等规模量子计算上有所斩获,且金融机构愿意为哪怕微小的性能提升买单。未来,当量子AI能可靠处理上千资产、万个场景的优化时,金融领域或将率先实现商业回报。
8.3 图论与网络分析
许多现实世界问题可以抽象为图,如社交网络、通信网络、生物调控网络等。图算法(如最短路径、社区划分)在大规模下计算代价高昂。量子算法可以加速部分图问题,例如Grover搜索可加速无结构路径搜索,量子行走算法可用于计算页面排名等。对于NP-hard的图划分、社团发现问题,QAOA提供了一种自然的近似方法。近期还有将量子电路与图神经网络(Graph Neural Network)结合的尝试:例如,用量子电路来表征节点embedding之间的高阶关联,再通过测量结果更新图神经网络参数。一项研究提出了量子图卷积网络,在一个药物分子图上,结合VQE方法预测分子性质,比经典GNN取得更高精度。在通信网络路由优化中,量子退火被用于求解特定路由方案,结果显示可缓解拥塞。这实际上与前述大众交通优化类似,只不过目标从公交变为了数据包。随着网络规模和复杂性的增长,经典启发式可能力不从心,而量子优化有机会探索出更优方案。理论上,量子行走可实现对图结构的指数加速理解,但受限于量子存取结构。未来若出现高效的量子存储与检索装置,图数据库查询、模式匹配等都可能由量子算法重塑。
8.4 安全与加密分析
量子计算对传统密码的威胁众所周知(Shor算法可在足够大规模时破解RSA公钥密码)。量子AI可以从另一个角度增强网络安全:例如异常检测,可使用量子机器学习模型在高维流量数据中检测异常模式,如网络入侵、欺诈交易等。量子核方法有望捕捉微妙的攻击特征,提高检测的及时性和准确率。又如密码分析,量子计算在某些情况下能加速密码破解过程,比如Grover算法对对称密钥暴力搜索的二次加速。虽然这并非AI范畴,但也是量子对安全的影响。值得注意的是,量子AI也可以应用于生成更安全的系统:如量子算法生成高质量的随机数用于加密(量子随机源无疑更可信),或用量子增强认证来抵御机器学习模型对抗攻击。华为等公司已经布局量子安全通信,将量子技术融入5G/6G安全框架。结合AI的智能安全防御也是趋势,比如AI动态调配量子密钥资源。可以预见,在“后量子密码”时代来临前,量子AI将在安全领域扮演攻防两端的角色:一方面帮助强化系统安全,另一方面也促使现有安全方案更新以对抗更强的量子计算威胁。
8.5 其他潜在领域
此外还有许多领域值得展望:医疗健康方面,量子AI可辅助分析基因组和蛋白质折叠等高维生物数据,帮助新药发现和个性化医疗;交通物流方面,除了前述公交优化,量子算法还可用于更大规模的物流配送路径优化和航空航线规划;气象与地球科学方面,量子机器学习有望改善对气候模式的建模和极端天气的预测;人机交互与推荐系统领域,也有尝试用量子概率模型解释用户行为,以改进推荐效果。这些场景有的需要强计算能力(如气候模拟),有的需要处理复杂不确定性(如用户兴趣建模),量子AI或许能够提供新方案。当然,所有应用前景都取决于底层量子技术的成熟度。在量子计算能力不足时,量子AI很难真正落地。因此,对这些领域来说,目前更现实的意义在于探索验证:通过小规模试点,找出量子AI在何种子问题上有潜力胜过经典方法。一旦硬件准备就绪,即可迅速扩大战果。
第九章 当前量子硬件限制与未来展望
经过前面章节的讨论可以看到,量子人工智能的发展与量子计算硬件的演进密不可分。最后一章我们聚焦量子硬件本身:分析当前限制性因素,并展望未来可能的突破方向,以及对量子AI的影响。
9.1 当前量子硬件的限制因素
(1)量子比特数目有限,纠错尚未实现。 尽管IBM、谷歌等不断刷新量子比特数量记录(如IBM Condor达到1121比特,谷歌亦宣称在研数千比特规模芯片),但这些比特都是物理比特,且噪声水平较高。要实现容错量子计算,需要通过量子纠错将多个物理比特组成一个逻辑比特,目前估计可靠编码一个逻辑比特可能需要上千物理比特。这意味着当下几百物理比特的设备实际上连一个完美逻辑比特都构建不出。没有纠错,量子电路深度被噪声容限严格限制,无法执行长算法。
(2)量子门保真度和相干时间不足。 目前超导比特单量子门保真度可达99.9%以上,两比特门在99%左右,离容错要求(99.99%以上)尚有差距。离子阱比特相干时间长但门速度慢,同样存在折衷。噪声导致的错误会累积并干扰计算结果。尤其对量子AI而言,训练过程需要大量重复量子电路,噪声影响更显著。一些量子AI实验中,研究者不得不频繁插入校准和误差缓减步骤,以保证结果可信度。
(3)尺度扩展引发工程难题。 增加量子比特并非易事:超导芯片比特数提升会遇到控制线布线、干扰、散热等问题(IBM通过多层布线和新封装部分解决了这些问题);离子阱扩展需要巧妙的电极设计和多阱耦合策略。光量子、量子点等路线也各有工程瓶颈。另外,读出、放大、信号实时反馈等支持系统的复杂度随比特数增长呈超线性上升,导致大型系统稳定运行难度极大。
(4)量子设备操作复杂,标准化欠缺。 目前每台实验室量子机几乎都是专门定制,软件栈也各不相同。这导致开发者使用门槛高,调试优化耗费大量人力。与经典计算已有统一架构不同,量子计算硬件尚未统一接口标准,如不同公司机器的门集合、拓扑结构有差异,使得编译和移植困难。这些限制共同决定了:短期内量子AI只能在很有限的硬件条件下运行,以toy problem验证为主,离解决真实世界AI问题尚远。
9.2 未来技术突破展望
尽管困难重重,各国科研人员正努力攻克技术壁垒,若干未来突破方向令人期待:
(1)实用量子纠错。一旦实现纠错,哪怕只能保护十几个逻辑比特运行较短深度,也足以执行一些关键算法。研究表明,当物理门错误率低于阈值并有足够冗余比特,纠错逻辑可指数降低错误率。Google在2023年宣布首次验证了量子纠错的“面臨阈值”现象,即增加冗余后逻辑比特的失错率降低,预示纠错的可行。未来几年可能看到稳定维持几个逻辑比特的小型纠错码问世,这将极大鼓舞士气,为量子AI执行更长时间的训练提供保障。
(2)新型量子比特与体系结构。除了超导、离子两条主流路线,若拓扑量子比特、自旋量子比特等取得突破,可能在相干时间或可集成性上实现飞跃。微软等在攻关的马约拉纳零模拓扑比特有望天然抗噪,大幅降低纠错开销。如果成功,将彻底改变量子计算硬件版图。一些初创也探索混合架构,如将多个中等规模量子处理模块通过光子互联构成更大系统,这类似经典多核CPU理念。华为的多子芯片耦合专利也是朝此方向努力。模块化、可扩展的架构将可能实现数万比特规模量子机。
(3)量子计算与经典高性能计算融合。未来很长一段时间,量子计算不会完全取代经典计算,而是作为加速器存在。IBM提出了量子中心超算的构想,即量子芯片通过高速接口与CPU/GPU协同工作。这样可以将量子AI融入现有AI流水线——经典部分处理预处理和简单计算,量子部分处理核心难点。这种融合需要发展高带宽、低延迟的量子-经典接口,以及分布式量子算法。近年来已有概念验证,比如IBM实现了经典计算参与的动态量子回路,可根据中间测量结果决定后续操作。融合架构将显著拓展量子AI应用范围。
(4)软件与理论的进步。硬件之外,算法改进同样重要。例如更高效的量子编译技术能减少电路门数,提高在有限相干时间内能完成的算法规模。AI辅助的编译(IBM已用强化学习优化量子线路调度)和差错消除将提升有效计算能力。此外,理论上更深刻理解量子模型的表达能力和学习原理,有助于设计对噪声更宽容的算法。在经典-量子混合优化方面,或许会出现专为量子AI定制的新优化方法,克服barren plateau等问题。
9.3 对量子AI发展的影响
随着上述技术逐步兑现,量子AI将进入一个崭新阶段。可以预见以下场景:当硬件达到上百逻辑比特、可执行上万深度电路时,量子机器学习算法将有舞台大展身手,可能首先在化学模拟、组合优化领域实现对经典方法的超越;当逻辑比特数进一步上千,并支持基本的量子内存和并行,复杂量子神经网络将成为可能,量子AI有机会介入大型机器学习任务,如对千万样本的数据集进行训练,用更短时间达到同等甚至更好精度;更远的未来,如果量子计算真正成熟成为IT基础设施,量子AI或将无处不在——人们或许并不感知到背后有量子技术,但享受着其带来的性能提升和全新功能。从长远看,量子AI并不会取代经典AI,而是融合共生。正如GPU加速深度学习但没有让CPU过时一样,量子加速器将与经典计算协同,形成混合智能系统。量子AI也会促使经典AI演进,例如启发新的经典算法思路,或者迫使经典AI寻找新的突破口以保持竞争力。
综上所述,量子人工智能作为量子计算和人工智能交汇的前沿领域,近几年取得了令人瞩目的理论和实践进展。尽管目前仍处于早期探索阶段,但其发展势头迅猛。在理论上,量子计算提供的指数级状态空间、叠加并行和纠缠关联为AI模型带来了前所未有的表达能力;在应用上,量子AI有望在化学、生物、金融等领域率先落地,解决经典计算难以应对的挑战。与此同时,我们也清醒地看到,实现量子AI宏伟蓝图还需克服硬件、算法诸多困难。然而,科技发展的历史证明,任何革命性技术的诞生都需要过程。可以预见,在未来的5-10年里,随着首批容错量子计算原型机的出现和更成熟的量子算法涌现,量子人工智能将逐步由理论走向实用,在一定范围内展现出优于经典的新性能;而在更长远的将来,量子与经典的融合将孕育出新一代智能计算范式,为人类探索更复杂的系统和数据打开大门。2025年的今天,我们正站在量子AI的起跑线上,充满挑战亦充满机遇。量子人工智能的发展之路任重道远,但前景光明。让我们拭目以待这场计算范式的深刻变革,期待量子之光为人工智能带来新的辉煌。
部分参考文献
-
Kamila Zaman et al. “A Survey on Quantum Machine Learning: Current Trends, Challenges, Opportunities, and the Road Ahead.” arXiv preprint arXiv:2310.10315, 2025.
-
Xavier Vasques et al. “Application of quantum machine learning using quantum kernel algorithms on multiclass neuron classification.” Scientific Reports, vol. 13, 11541, 2023.
-
Casey Hall. “Alibaba's research arm shuts quantum computing lab amid restructuring.” Reuters, Nov 27, 2023.
-
Edd Gent. “Alibaba and Baidu Cash Out on Quantum Computing Stakes – But Tencent and Beijing double down.” IEEE Spectrum, Feb 14, 2024.
-
IBM News Room. “IBM Debuts Next-Generation Quantum Processor & Quantum System Two, Extends Roadmap to Advance Era of Quantum Utility.” IBM Press Release, Dec 4, 2023.
-
Volkswagen News. “Volkswagen optimizes traffic flow with quantum computers.” VW Press Release, Oct 31, 2019.
-
Charles Q. Choi. “IBM Unveils 433-Qubit Osprey Chip – Next year entanglement hits the kilo-scale with 1,121-qubit Condor.” IEEE Spectrum, Nov 09, 2022.
-
华为技术有限公司. “量子芯片以及量子计算机” 发明专利公开号 CN114613758A, 2022.
-
夏舍予. “百度首个超导量子计算机发布,搭载10量子比特,秀软硬一体解决方案.” 凤凰网科技, 2022-08-25.
-
Jay Gambetta. “The hardware and software for the era of quantum utility is here.” IBM Quantum Blog, Dec 4, 2023.
作者声明:文中部分概念或术语链接可以打开,可供学习。


















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











