




前言
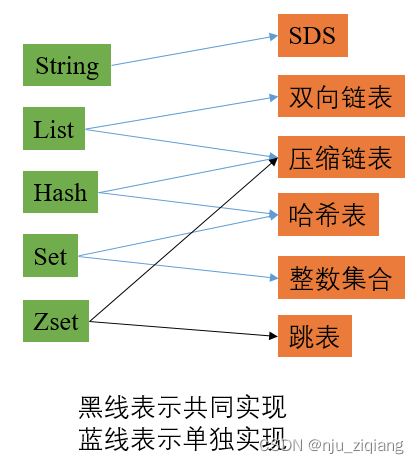
在Redis3.0中,数据结构包括6种:SDS(简单动态字符串),双向链表,压缩列表,哈希表,整数集合,跳表。
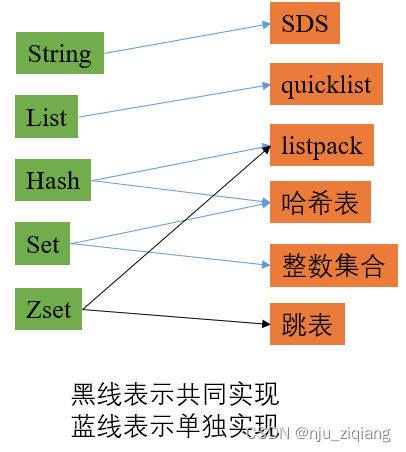
而在最新的Redis版本中,包括以下6种:SDS(简单动态字符串),quicklist,listpack,哈希表,整数集合,跳表。
以上综合起来是8种数据结构。
SDS(简单动态字符串)
SDS是Redis中String数据类型的底层数据结构
未使用char[]数组的原因有以下三点:
- 获取长度的时间复杂度是O(N);
- 利用/0作为字符串结尾,导致不能保存音频、视频等二进制文件;
- 拼接字符串可能存在缓冲区溢出的风险。
SDS的结构
存在四个成员变量:
- len:用于记录字符串的长度
- alloc:分配的空间长度
- flags:sds的类型,存在五种(sdshdr5,sdshdr8,sdshdr16,sdshdr32,sdshdr64),5 种类型的主要区别是,它们数据结构中的 len 和 alloc 成员变量的数据类型不同。比如sdshdr5表示字符数组长度和分配空间长度不能超过2的5次方。
- buf[]:字节数组,用于保存实际数据
双向链表
双向链表的优点
- 获取前一个节点、后一个节点、头结点、尾结点、节点数量的时间复杂度都是O(1);
- 链表中的节点可以保存不同类型的值。
双向链表的缺点
- 由于链表中节点的内存不连续,无法很好利用cpu的缓存;
- 保存一个链表节点的值需要一个链表节点结构头的分配,内存开销大。
压缩列表
压缩列表的优点
- 它的特点是,被设计成一种紧凑的数据结构,占用一块连续的内存空间,可以有效利用cpu缓存;
- 针对不同长度的数据进行相应编码,有效节省内存开销
压缩列表的缺点
- 不能保存过多元素,否则查询效率降低;
- 新增或修改某个元素时,压缩列表占用的内存空间可能需要重新分配,甚至导致连锁更新的问题。使得压缩列表的内存空间要多次重新分配,直接影响访问性能。
结构
压缩列表在表头有三个字段,表尾有一个字段:
- zlbytes:压缩列表占用内存字节数
- zltail:列表尾部偏移量
- zlen:包含的节点数
- zlend:标记压缩列表的结束点,固定值0xFF
压缩列表中节点的结构,有三个字段:
- prevlen:前一个节点的长度
- encoding:当前节点的实际数据类型和长度
- data:当前节点的实际数据
当我们往压缩列表中插入数据时,压缩列表就会根据数据是字符串还是整数,以及数据的大小,会使用不同空间大小的 prevlen 和 encoding 这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。
连锁更新
当在压缩列表中新增或者更改节点元素时,如果空间不够,压缩列表内存空间就要重新分配,如果插入元素过大可能导致后面元素的占用空间发生变化,引起连锁更新。
哈希表
哈希表的优点
- 查询数据的时间复杂度是O(1)
哈希表的缺点
- 随着数据增多,导致哈希冲突严重
rehash
redis中采用链式哈希解决哈希冲突,但是随着链表长度不断增加,这条链表上的查询就会更耗时,就需要利用rehash对哈希表大小进行扩展。
rehash触发条件:
负载因子 = 哈希表中节点数量/哈希表大小
- 当负载因子大于等于1,并且redis没有进行bgsave和bgrewriteaof命令时;
- 当负载因子大于等于5时,强制进行rehash。
在redis中,定义了一个dict结构体,里面定义了两个哈希表,进行rehash的时候就要利用第二个哈希表。具体过程是:
- 给哈希表2分配空间,一般比第一个大两倍
- 将哈希表1的数据迁移到哈希表2
- 将哈希表1的空间释放,将哈希表2设置为哈希表1,然后在哈希表2的地方创建一个空白的哈希表。
但是如果哈希表1中的数据过于庞大,拷贝过程中可能会对redis造成阻塞。为了避免这种情况,redis利用渐进式rehash解决:
- 给哈希表2分配空间
- 在rehash进行期间,对哈希表元素进行增删改查操作时,会顺序将哈希表1中索引的元素迁移到哈希表2上
- 直到哈希表1的所有元素都迁移到哈希表2,完成rehash
整数集合
是set对象的底层实现之一,当一个 Set 对象只包含整数值元素,并且元素数量不大时,就会使用整数集这个数据结构作为底层实现。
结构
本质是一块连续的内存空间,结构中包含编码方式,元素数量,保存元素的数组。
升级操作
当新加入的元素类型比集合现有所有元素的类型要长时,集合会先进行升级,将所有元素都升级为新加入元素的类型。
优点是:节省内存空间。
跳表
Redis 只有在 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询。
跳表示在链表基础上改进的,实现一种多层的有序链表。
跳表的查询:
- 从头节点最高层级开始查询,
如果当前节点的权重「小于」要查找的权重时,跳表就会访问该层上的下一个节点。
如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「小于」
要查找的数据时,跳表就会访问该层上的下一个节点。
- 如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的 level 数组里的下一层指针,然后沿着下一层指针继续查找,这就相当于跳到了下一层接着查找
quicklist
quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
之前在压缩列表中提到过当修改元素或增加元素有连锁更新的风险,quicklist通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
listpack
quicklist并没有完全解决连锁更新的问题,这是由于压缩列表这种数据结构导致的。因此为了解决这个问题,设计了一种新的数据结构listpack,listpack中的节点不再包含前一个节点长度。
listpack还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。
注:本文主要参考小林coding,进行总结。

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









