







 本文介绍了DQN算法存在的过度估计问题,以及DoubleDQN(DDQN)算法通过分离动作选择和目标Q值计算来改进这一问题。文章详细解释了DDQN的工作原理,并提供了代码示例对比DQN和DDQN的区别。
本文介绍了DQN算法存在的过度估计问题,以及DoubleDQN(DDQN)算法通过分离动作选择和目标Q值计算来改进这一问题。文章详细解释了DDQN的工作原理,并提供了代码示例对比DQN和DDQN的区别。
前言
DQN算法有一个显著的问题,就是DQN估计的Q值往往会偏大。这是由于我们Q值是以下一个s’的Q值的最大值来估算的,但下一个state的Q值也是一个估算值,也依赖它的下一个state的Q值…,这就导致了Q值往往会有偏大的的情况出现。
所以出现了对DQN算法的改进算法Double DQN(DDQN)算法。
一、DDQN算法原理
DDQN算法和DQN算法一样,也有一样的两个Q网络结构。在DQN算法的基础上,通过解耦目标Q值动作的选择和目标Q值的计算这两步,来消除过度估计的问题。
在DQN算法中, DQN算法对于非终止状态,其目标Q值的计算式子是:
y t = r t + γ ⋅ max a Q ( s t + 1 , a ; w ) {y_t = r_t + \gamma \cdot \max_aQ(s_{t+1},a;w)} yt=rt+γ⋅maxaQ(st+1,a;w)
在DDQN算法这里,不再是直接在目标Q网络里面找各个动作中最大Q值,而是先在当前Q网络(Q估计网络)中先找出最大Q值对应的动作(返回动作下标),即:
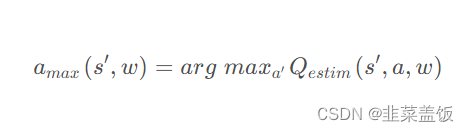
然后利用这个选择出来的动作
a
m
a
x
(
s
‘
,
w
)
a_{max}(s^‘,w)
amax(s‘,w)在目标网络 (Q Target) 里面去计算目 Target Q值
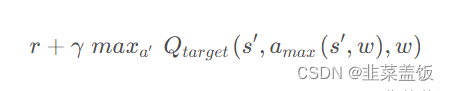
综合起来 在Double DQN 中的 TD Target 计算为:
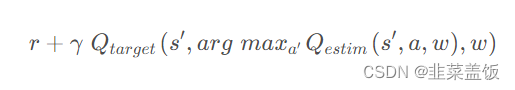
这样我们就可以降低过度估计的问题,因为目标网络的具有最大Q值的动作a,不一定就是当前Q网络中具有最大Q值的动作。
二、代码示例
由上面可知,Double DQN 算法和 DQN 算法唯一不同的地方在于计算Q值的方式。
在原始的 DQN 算法中,使用目标网络(target network)来计算下一个状态的 Q 值。
而在 DDQN 算法中,我们使用在线网络(online network)来选择下一个状态的动作,然后使用目标网络来计算该动作对应的 Q 值,其余流程一样。
这里附上代码的不同之处:
DQN算法:
def learn_batch(self,batch_obs, batch_action, batch_reward, batch_next_obs, batch_done):
# predict_Q
pred_Vs = self.pred_func(batch_obs)
action_onehot = torchUtils.one_hot(batch_action, self.n_act)
predict_Q = (pred_Vs * action_onehot).sum(1)
# target_Q
next_pred_Vs = self.target_func(batch_next_obs)
best_V = next_pred_Vs.max(1)[0]
target_Q = batch_reward + (1 - batch_done) * self.gamma * best_V
# 更新参数
self.optimizer.zero_grad()
loss = self.criterion(predict_Q, target_Q)
loss.backward()
self.optimizer.step()
DDQN算法:
def learn_batch(self, batch_obs, batch_action, batch_reward, batch_next_obs, batch_done):
# predict_Q
pred_Vs = self.pred_func(batch_obs)
action_onehot = torchUtils.one_hot(batch_action, self.n_act)
predict_Q = (pred_Vs * action_onehot).sum(1)
# target_Q
next_pred_Vs_online = self.pred_func(batch_next_obs)
next_pred_Vs_target = self.target_func(batch_next_obs)
best_action_online = next_pred_Vs_online.argmax(1)
best_V_target = next_pred_Vs_target.gather(1, best_action_online.unsqueeze(1)).squeeze(1)
target_Q = batch_reward + (1 - batch_done) * self.gamma * best_V_target
# 更新参数
self.optimizer.zero_grad()
loss = self.criterion(predict_Q, target_Q)
loss.backward()
self.optimizer.step()


















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











