




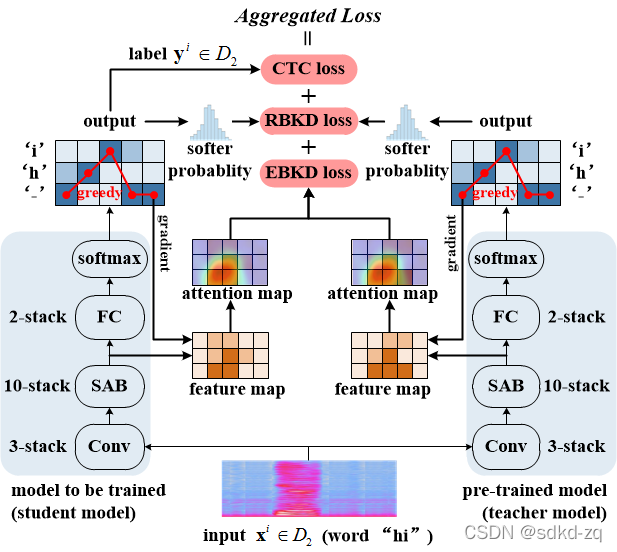
 该文章探讨了增量学习如何在不损害原有模型性能的基础上,提升端到端自动语音识别(ASR)模型在新数据集的表现。通过教师-学生框架和CTC损失,以及RBKD和EBKD两种知识蒸馏方法,尤其是提出的EBKD方法,能够更好地保留模型在原始任务上的能力。EBKD利用SAB的结果作为特征图,计算重要性矩阵,并结合模型贪婪预测的梯度,以计算欧氏距离,从而实现模型的优化更新。
该文章探讨了增量学习如何在不损害原有模型性能的基础上,提升端到端自动语音识别(ASR)模型在新数据集的表现。通过教师-学生框架和CTC损失,以及RBKD和EBKD两种知识蒸馏方法,尤其是提出的EBKD方法,能够更好地保留模型在原始任务上的能力。EBKD利用SAB的结果作为特征图,计算重要性矩阵,并结合模型贪婪预测的梯度,以计算欧氏距离,从而实现模型的优化更新。
INCREMENTAL LEARNING FOR END-TO-END AUTOMATIC SPEECH RECOGNITION
url: https://arxiv.org/pdf/2005.04288.pdf
增量学习的目的就是在保持原模型性能的前提下,提升在新数据集上的表现;
采用Teacher-student结果,CTC loss用于帮助ASR模型学习新的任务;RBKD和EBKD两种蒸馏loss用于保留模型 在原任务上的性能。
RBKD计算output的对齐结果loss最小
文章提出一种EBKD的方法,相比Response-based Knowledge Distillation(RBKD)方法,可以取得更好的效果。
EBKD:SAB的结果作为feature map, 计算feature map的重要性矩阵,根据模型greedy 预测结果的梯度,然后相乘后,计算relu,Returns the normalized Euclidean distance of two models.


















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









