




 本文旨在帮助初学者掌握Python的运行及编程技巧,通过介绍如何在IDLE环境中运行代码、理解Python的基础知识、导入和使用模块,以及提供实验建议,助力学习者提升数据敏感性和实验效果。
本文旨在帮助初学者掌握Python的运行及编程技巧,通过介绍如何在IDLE环境中运行代码、理解Python的基础知识、导入和使用模块,以及提供实验建议,助力学习者提升数据敏感性和实验效果。
这周的实验作业,需要我们写Python,当然,与其说是写,不如说是原封不动地把Python代码抄下来罢了,尽管如此,python一些东西没弄好,你程序抄了也跑不起来。
本文目的有两个:
1.帮助同学们抄的Python程序能成功跑起来
2.帮助同学们在实验作业上取得更好的学习效果
一、怎么运行Python
虽然Anaconda也能拿来写Python,但是由于是黑窗口,对于我们一些小白同学来说不是很友好,所以我推荐同学们安装Python官方的写Python用的软件(IDE),具体怎么装,我这边给个B站的视频,大家可以看着操作,注意的是,视频中Python是3.3版本的,但现在Python已经出到3.8版本了,所以是建议装3.8版本,也就是最新版,然后也希望大家能把视频看完,对Python的程序怎么敲进去有个大致了解
视屏链接:https://www.bilibili.com/video/av4050443/?p=2
二、Python的一些基础知识
Python是一种解释型语言,代码是逐行读取然后编译执行的,所以可以变敲代码边运行;
作为对比,我们学的C语言是一种编译语言,完整的源代码将直接编译为机器代码,由CPU直接执行,所以代码得完整写完才能运行。
比如,你想在C语言上打A+B程序,你得新建个文件,然后写个头文件,写个main函数,再在main函数里定义变量A, B,然后给A,B赋值,再用printf()输出,最后还不能忘记加return 0;在这个过程中,要是漏个字母,漏个标点符号,程序就会编译出错,更别说跑了。而你想在Python上打A+B程序,你可以在IDLE先打一行A = 4(Python中变量不需要事先定义,赋值的时候自动定义的,变量类型也是自动确定的),回车,然后再打一行B = 6,回车,再打一行print(A+B)回车,我们就会看到: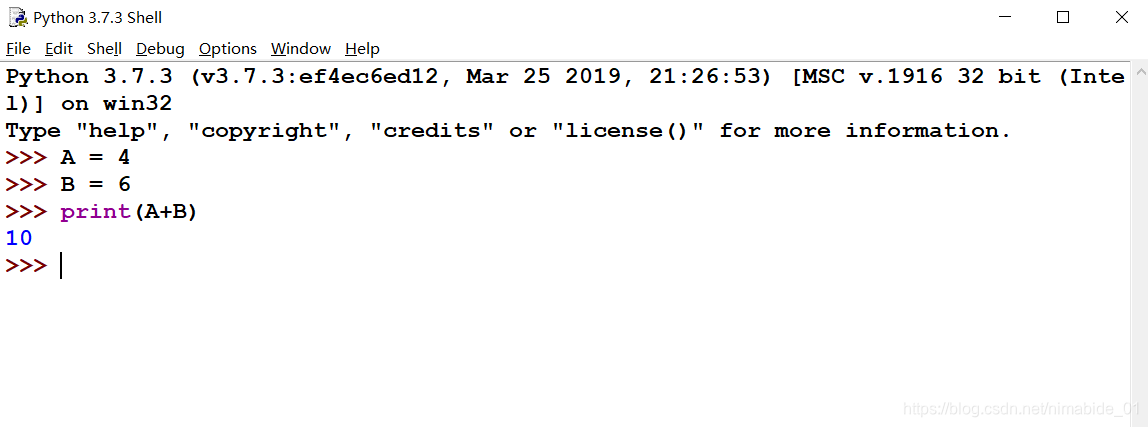
就在print(A+B)那行代码的下一行有个蓝色的“10”,程序运行结果马上出来了
如果我中间敲程序可能敲错了,比如,Python中print()的后面是没有f的,但你C语言敲习惯了,多加了个f,然后一回车,报错了,这时候我们需要重新写代码重新给A,B赋值吗?不用!继续专心把你print()那行敲对就行,写Python程序跟敲命令行一样,一条一条慢慢来,敲错无妨,不影响什么。
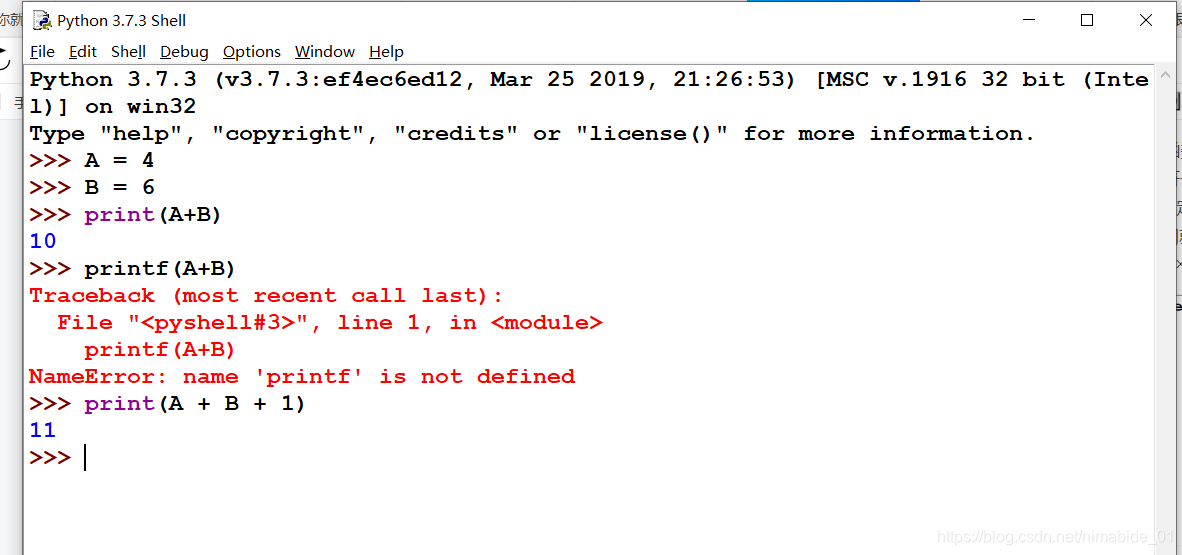
那么,Python是不是不能像C语言那样先把所有完整代码敲出来再完整运行?当然不是!
工具栏里File那栏,点开然后有New File一项,点进去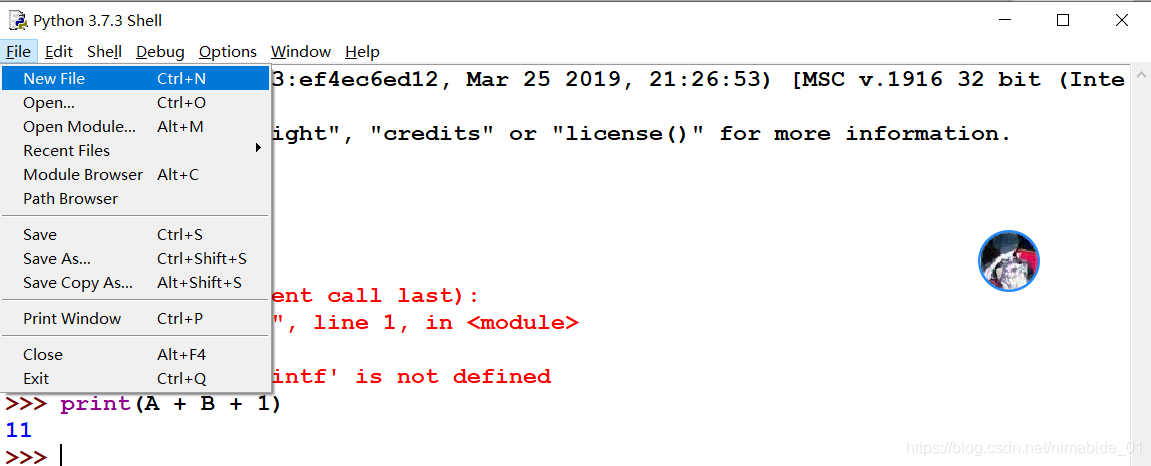
然后会打开一个空白窗口,在这里你可以像写C一样写Python代码,然后运行

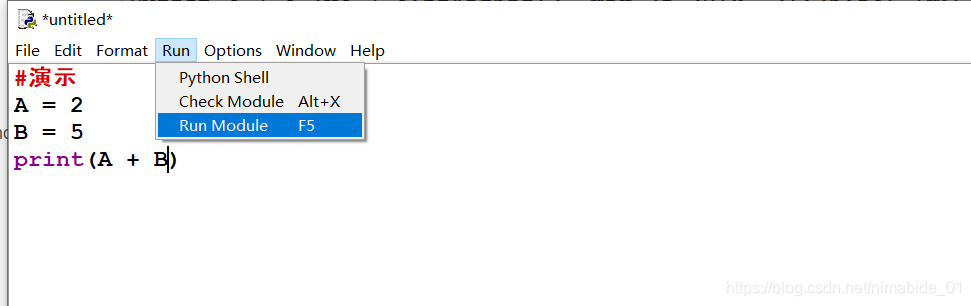
不过需要注意的是,虽然是像C一样写代码,但实际运行过程中Python还是在逐行运行代码的,如果某一行写错了,那么Python在运行到那一行时就会报错,然后程序终止
二、关于Python模块的知识
Python的精髓就是导入模块
模块是什么?模块就是别人已经用python写好的工具包,我们以调用函数的方式去使用,这样就不需要我们从0开始去写那些我们所需要的功能,比如pandas模块中有很多处理数据的工具像read_csv(),读入表格文件用,discribe(),把数据整理后以表格形式显示出来;而turtle模块中有很多画图的工具像fd(),控制画笔往前画线,left()画笔向左转多少度等等。
导入模块需要用到import命令,格式为
import 你要导入的模块名
比如:import pandas
那么以后我们要使用这个模块时,就打pandas.xxx()
不过有时程序员觉得模块名太长,他就给模块进行了重命名,比如把pandas模块重命名成pd,那么以后要使用pandas模块时,打pd.xxx()就行了,而不用打pandas.xxx()
给模块重命名的方法很简单,就是在import时你这样写
import 你要导入的模块名 as 你给这个模块重命名的名字
比如:import pandas as pd
然后在下面的程序中想使用pandas模块的时候打pd.xxx()就可以了
不过模块这种东西,不是安装Python时自带的,更不是凭空出现的,而是需要我们去下载的,不然你import的时候Python就找不到这个模块,这也是我们同学把网上代码就算抄下来也跑不起来的原因,像什么pandas,numpy这些模块,你电脑里根本就没有,怎么import得进去呢。
所以重点来了,我们怎么去下载那些模块?
按下win+R,在左下角弹出的窗口中输入cmd,然后点运行
然后电脑会弹出一个控制台窗口,我们要用这个窗口来下载并安装Python模块
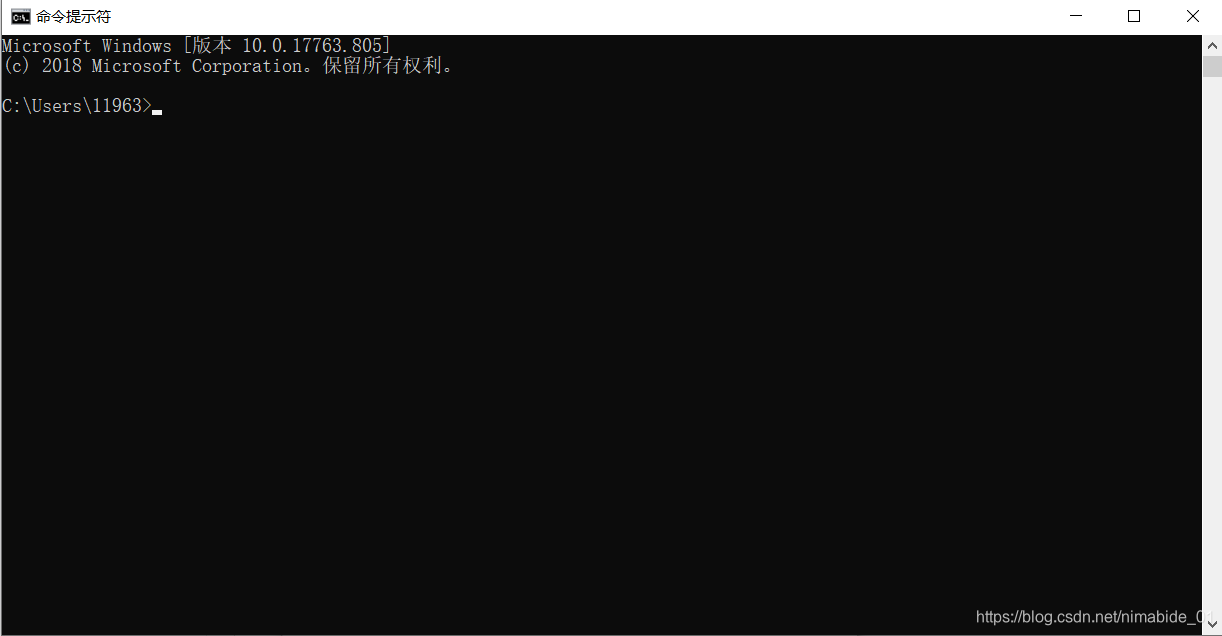
比如我们要下载并安装pandas模块,那么我们就在控制台中输入:pip install pandas 然后按下回车,电脑就会自己跑去Python服务器找到pandas模块下载并安装下来
也就是说,安装某个模块的命令是:
pip install 你要安装的模块
稍微解释一下这行命令,pip是一个Python的模块管理器,install是安装的意思,pip除了install命令外还有show(显示模块版本),uninstall(卸载)等命令,这里我们用到的install是安装命令。
在我们装好程序中所用到的模块后,程序就能正确地把模块import进去然后跑起来了。
三、关于进行实验的一些建议
Python有在IDLE界面直接一行一行敲代码运行跟新建一个文件往里边敲好所有代码再运行两种编程方式,出于实验效果考虑,我推荐大家在IDLE界面一行一行地敲,这样碰到相应的代码时大家能更好地感受到某行代码的作用,并且实验展示效果也会更好。
那么,关于程序的部分到这里就完了。
四、大数据实验我们需要探究什么?思考什么?
我们做的是数据实验,所以写代码不是我们的第一目的,而从实验中感受到数据之间的关系,培养我们数据的敏感性才是我们的学习目的。
就拿本次实验来说,本次实验是研究员工离职的案例分析,那么我们直接可以得知这案例分析是分析员工离职跟他各项数据的关系的,进而我们可以联想实际:薪水跟员工离职的关系(老板给钱越少肯定干得越不乐意,最后就跑了),加班时间跟员工离职的关系(老板天天叫你加班,最终你受不了了,就跑了),犯过错误的次数与员工离职的关系等。然后我们就能猜到这个程序的目的是什么(数据整理,然后将其可视化),在敲程序的时候关注它整理数据的方法,这样有目的地去进行实验,有助于我们更好地进行学习。

















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









