




 本文介绍了华农大数据1班在2019年上学期第13周的高程题目,包括求因子和的算法与链表数据结构的讲解。文章详细阐述了链表中头结点的作用,并通过示例展示了如何创建、插入和删除链表节点,以及解决‘圈中的游戏’问题。
本文介绍了华农大数据1班在2019年上学期第13周的高程题目,包括求因子和的算法与链表数据结构的讲解。文章详细阐述了链表中头结点的作用,并通过示例展示了如何创建、插入和删除链表节点,以及解决‘圈中的游戏’问题。
一、求因子和
思路:设函数f(x) = x的因子和,那么这道题把1~10000中符合f(x) = n的x都输出来即可
代码如下:
#include<stdio.h>
#define read(x) scanf("%d", &x)
int sum(int x)
{
int res = 0;
int i;
for(i=1; i<x ;i++)
if(x % i == 0) res += i;
return res;
}
int main()
{
int n;
read(n);
for(int i=1; i<=10000 ;i++)
if(sum(i) == n) printf("%d\n", i);
return 0;
}
二、链表
链表是一种数据结构,把在不连续地址中的数据用指针串起来
下图将数组跟链表进行比较
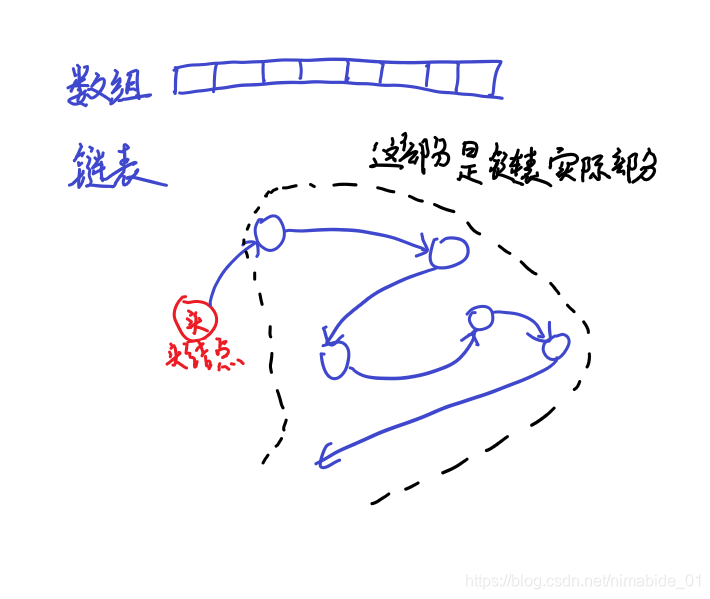
从上图我们可以看到,数组中数据的地址是连续的,但链表中数据的地址是不连续的,这里我们可以看到链表还有头结点,头结点中不存数据(你也可以在头指针数据域中存链表长度),正式的数据部分在头结点之后,所以头结点的作用是指向第一个正式数据的结点,比如有串数据{1, 3, 5}那么在链表中他们是这样存储的:[头]->[1]->[3]->[5]->NULL。正式数据是空的,那么头结点就会指向NULL,即[头]->NULL。
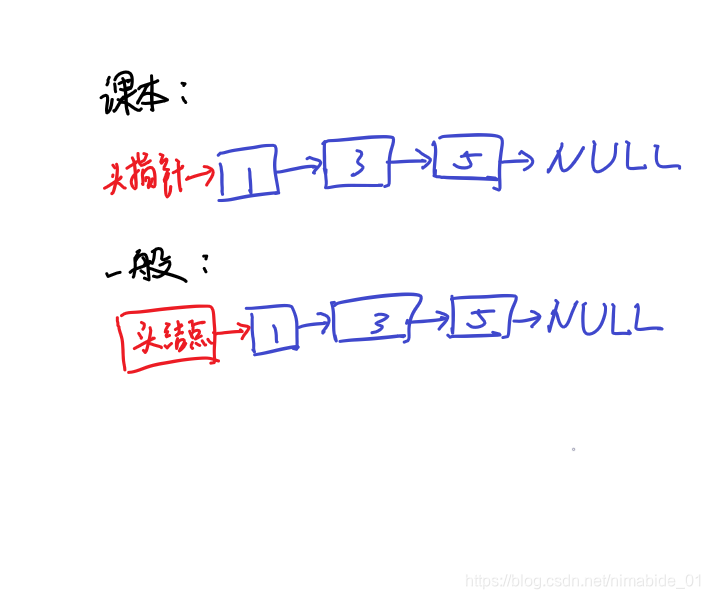
为什么要设置一个头指针呢?
实际上这涉及链表在实际程序中的的表示问题,我们在程序中定义一个链表List L,那一般来说,链表L经过创建后我们希望链表是这样表示的:
L->[1]->[3]->[5]->NULL。
这里L就是一个头结点。我们华农的高程课本上把头结点直接定义成了一个结构体指针head((实际上这成了一个头指针,不是结点),但是我认为把头定义成指针并不是很好,应该吧头定义为结点,也就是应该Node head这样定义,而不是Node* head这样定义。
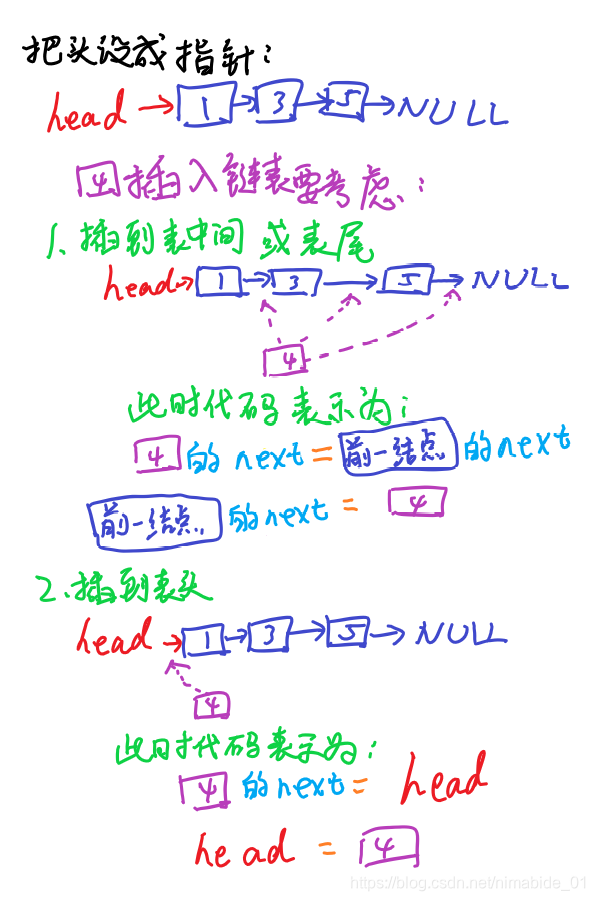
因为在设计实际的算法步骤的时候,如果把头设成指针,那么由于头跟整个链表数据的数据类型并不统一,导致一些情况下需要特判,把头设成结点就不会这样,这里举一个插入数据的例子,你们体会下这种把头设为指针的方法的局限性。
把头设为指针
把头设为结点
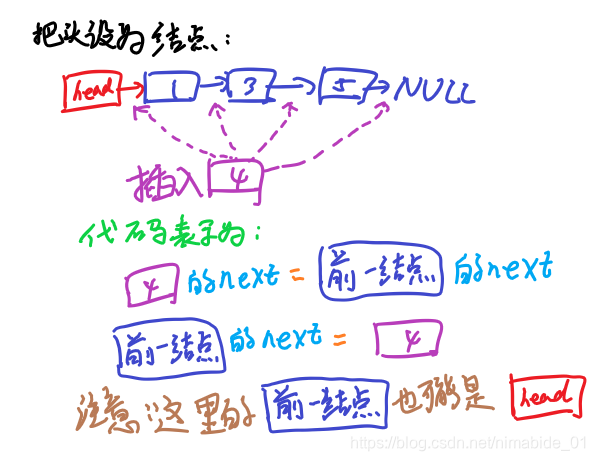
因为把头设成结点的话,就不用纠结新来的结点是不是插到表头,代码量就会小很多,代码的可靠性也会提高,所以我们一般是使用头结点,然后链表实际部分往头结点后面挂。
相关练习
18063 圈中的游戏(OJ->教材习题->第九章练习)
Description
有n个人围成一圈,从第1个人开始报数1、2、3,每报到3的人退出圈子。编程使用链表找出最后留下的人。
输入格式
输入一个数n,1000000>=n>0
输出格式
输出最后留下的人的编号
输入样例
3
输出样例
2
思路:创建链表,模拟这个过程
这里为了保证程序可靠性,mian函数中,我只用函数来操作链表
int main()
{
int n;
scanf("%d", &n);
List L;
CreateList(&L, n); //创建链表
printf("%d", ans(&L));//计算、输出答案
return 0;
}
链表结构不用说了,数据域就是编号
typedef struct Node{
int index;
struct Node* next;
} Node;
typedef Node* List;
为了方便添加新结点,我们定义了一个添加结点的函数
Node* newNode()
{
Node* p = (Node*)malloc(sizeof(Node));
p->next = NULL;
return p;
}
下面是创建链表的函数
int alive; //表示统计圈中还剩几个人
void CreateList(List* L, int n) //L是链表的头结点,这里写成List L会导致链表创建失败,想想这是为什么
{
(*L) = newNode(); //头结点创建。头结点的指针域指向链表的第一个结点。若链表为空,则头结点指针域的值为NULL
Node* p = (*L); //p始终指向表尾的最后一个结点,当表为空时,p指向头结点
//创建整表
for(int i=1; i<=n ;i++){
p->next = newNode(); //表尾申请新结点
p = p->next;//更新表尾位置
p->index = i;//设置当前表尾结点编号
}
p->next = (*L)->next; //表尾指针指向表头。构成一个循环链表
alive = n;
}
下面是删除结点的函数
void Link(Node* a, Node* b)//把结点a跟结点b连起来
{
a->next = b;
}
void del(Node* p, Node* pre)
{
Link(pre, p->next);
free(p);
}
获取答案的函数:
int ans(List* L) //这里写List L也行,但是这样子从外部看不出来这个函数会改变链表的结构,所以为了明确表明这个函数会改变链表,还是写成List*了,因为在我们的一般认知中,要传指针的参数一般都是要改变指针所指向的内容的
{
Node* p = (*L)->next; //这里p指向当前报数的人
Node* pre = (*L);//这里pre是p的前一个结点,也就是说pre的指针域指向p,辅助删除结点操作用的
int Count = 1; //当前报的数
while(alive > 1){
if(Count == 3){
del(p, pre); //删掉编号报道到3的人
alive--;
p = pre->next; //p所指结点被删后p指针指向NULL,所以这里让p更新一下
Count = 1;
}
else{
pre = p;
p = p->next;
Count++;
}
}
return p->index;
}
全部代码总览:
#include<stdio.h>
#include<malloc.h>
typedef struct Node{
int index;
struct Node* next;
} Node;
typedef Node* List;
Node* newNode()
{
Node* p = (Node*)malloc(sizeof(Node));
p->next = NULL;
return p;
}
int alive; //表示统计圈中还剩几个人
void CreateList(List* L, int n) //L是链表的头结点,这里写成List L会导致链表创建失败,想想这是为什么
{
(*L) = newNode(); //头结点创建。头结点的指针域指向链表的第一个结点。若链表为空,则头结点指针域的值为NULL
Node* p = (*L); //p始终指向表尾的最后一个结点,当表为空时,p指向头结点
//创建整表
for(int i=1; i<=n ;i++){
p->next = newNode(); //表尾申请新结点
p = p->next;//更新表尾位置
p->index = i;//设置当前表尾结点编号
}
p->next = (*L)->next; //表尾指针指向表头。构成一个循环链表
alive = n;
}
void Link(Node* a, Node* b)//把结点a跟结点b连起来
{
a->next = b;
}
void del(Node* p, Node* pre)
{
Link(pre, p->next);
free(p);
}
int ans(List* L) //这里写List L也行,但是这样子从外部看不出来这个函数会改变链表的结构,所以为了明确表明这个函数会改变链表,还是写成List*了,因为在我们的一般认知中,要传指针的参数一般都是要改变指针所指向的内容的
{
Node* p = (*L)->next; //这里p指向当前报数的人
Node* pre = (*L);//这里pre是p的前一个结点,也就是说pre的指针域指向p,辅助删除结点操作用的
int Count = 1; //当前报的数
while(alive > 1){
if(Count == 3){
del(p, pre); //删掉编号报道到3的人
alive--;
p = pre->next; //p所指结点被删后p指针指向NULL,所以这里让p更新一下
Count = 1;
}
else{
pre = p;
p = p->next;
Count++;
}
}
return p->index;
}
int main()
{
int n;
scanf("%d", &n);
List L;
CreateList(&L, n); //创建链表
printf("%d", ans(&L));//计算、输出答案
return 0;
}

















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









