




LoRA:从线性代数到模型微调
从矩阵分解理解Lora
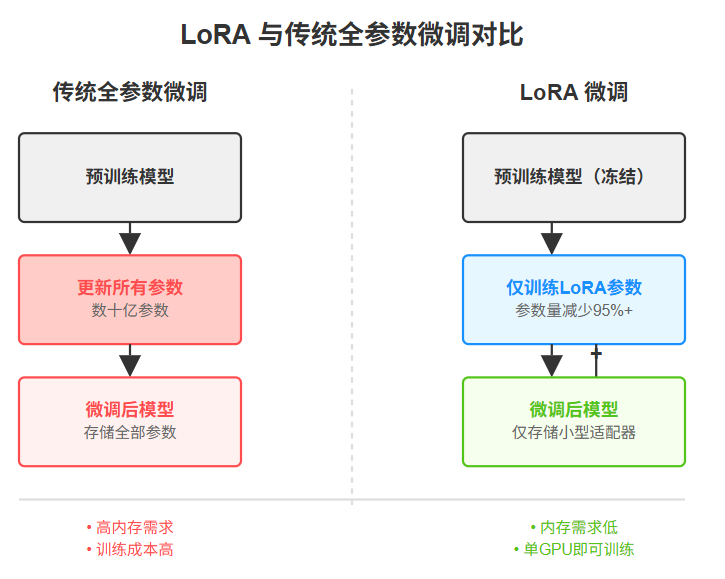
假设我们有一个大模型中的权重矩阵,形状为1024×512(包含约52万个参数)。传统微调方法会直接更新这52万个参数,这不仅计算量大,而且存在过拟合风险。
LoRA的做法是:
- 保持原始权重矩阵不变
- 引入两个小矩阵:比如1024×32和32×512
- 这两个小矩阵相乘得到的结果与原始矩阵形状相同
- 将乘积结果与原始矩阵相加,作为最终使用的权重
这种方法的优势立刻显现:
- 32是一个超参数r(rank),通常远小于原始维度
- 两个小矩阵总共只有约4.9万个参数,仅为原始矩阵的约9.3%
- 如果r取更小值(如8或4),参数量可进一步减少
总结一下:LoRA的核心思想源自线性代数中的"低秩矩阵分解"技术。这个名字可以拆解为Low-Rank Adaptation,字面意思是"低秩适应"。通过这种技术,我们可以巧妙地绕过直接修改原始模型的庞大参数,而是添加训练一组规模小得多的参数矩阵。
为什么这么做会有效
LoRA的数学表达
让我们用数学公式来表达这个过程。对于原始权重矩阵 W∈R^(d×k),LoRA微调后的权重表示为:
W_LoRA = W + ΔW = W + BA
其中:
- B∈R^(d×r) 和 A∈R^(r×k) 是两个低秩矩阵
- r << min(d,k),确保参数量大幅减少
- 初始化时,B可以随机初始化,而A通常初始化为全零矩阵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











