 图文解析大模型MOE架构原理
图文解析大模型MOE架构原理





2025年几乎所有领先的大型语言模型都采用了混合专家(Mixture of Experts,简称MOE)架构。
从GPT-4到DeepSeek V3,从Llama 4到Grock,这种稀疏激活的架构已经成为构建高性能AI系统的标准方法。
MOE(Mixture of Experts) 架构
MOE架构的主要组成部分
回顾下Transformer架构,我们会将token输入到Transformer中,Transformer架构是由N个编码器和N个解码器组成。编码器/解码器内部是由两部分组成:
- 注意力机制:残差+多头+LN
- 神经网络:残差+神经网络+LN
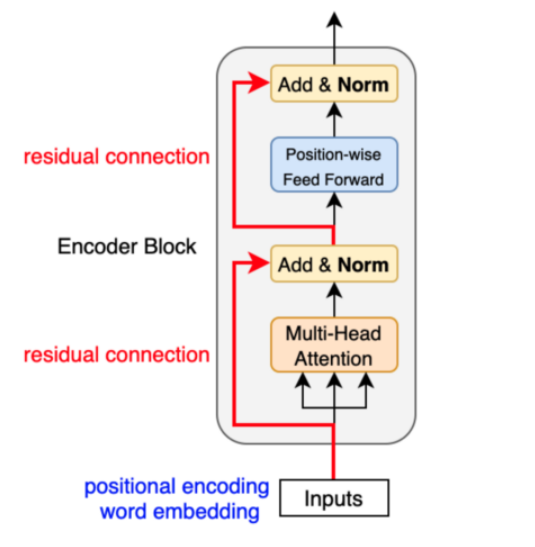
而MOE架构主要修改的是Transformer模型中的神经网络部分。由左图中可知MOE包含两部分:
- 稀疏 MoE 层: 这我们只需将 Transformer 的神经网络多拷贝几份(后文会将这一层称为专家层),在复杂运用中也可能是多个MoE层。
- 路由层: 这个部分用于决定哪些token被发送到哪个神经网络中。例如,在下图中,“More”这个令牌可能被发送到第二个神经网络,而“Parameters”这个令牌被发送到第一个神经网络。有时,一个令牌甚至可以被发送到多个神经网络。该路由方式是由预训练学习的参数所得到的
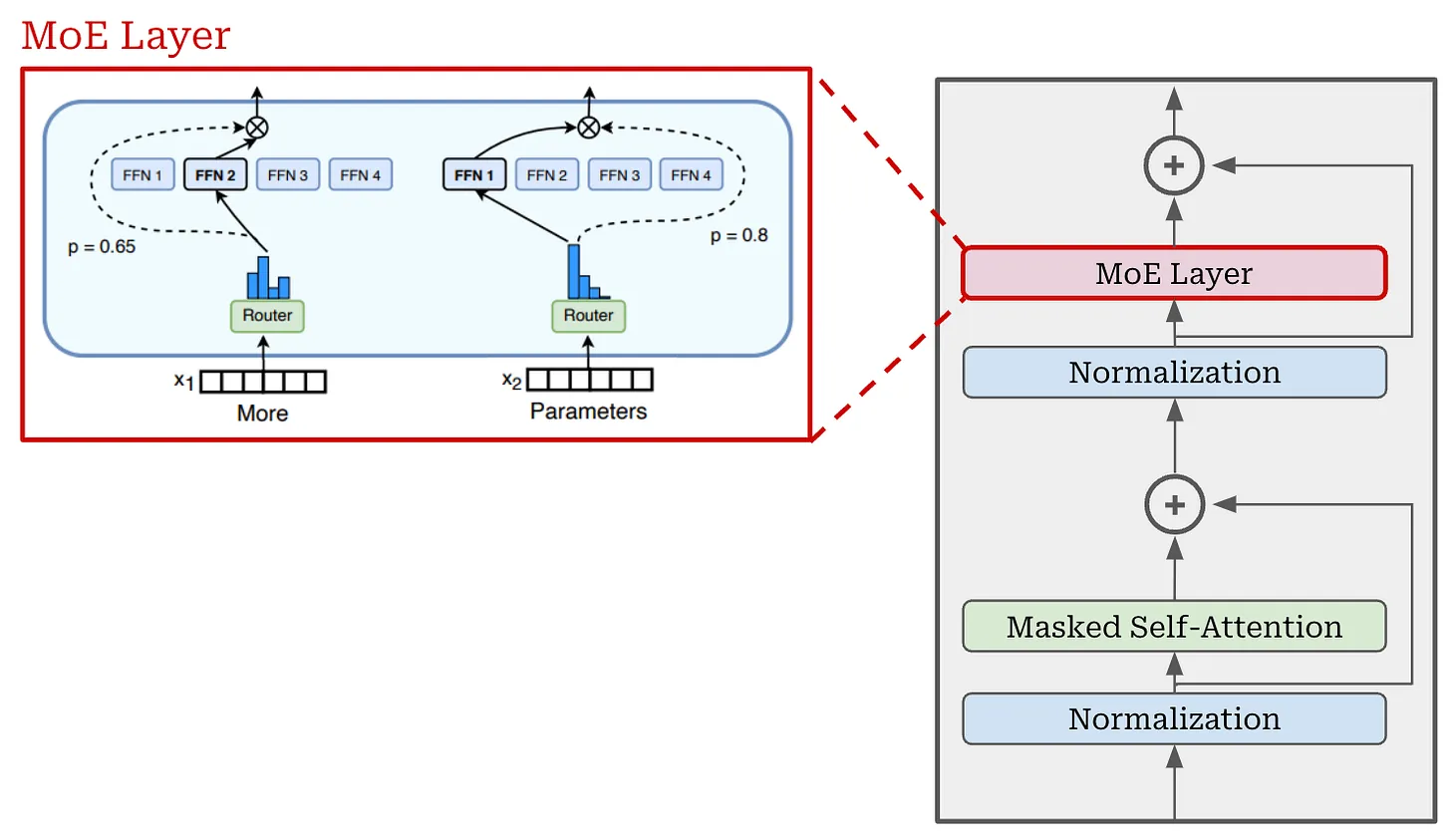
1. 专家层
我们无需在 Transformer 的每个前馈层都使用MOE层。即有的使用MOE有的保持神
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











