



当托尼·斯塔克在《钢铁侠》中与J.A.R.V.I.S进行自然交流,让AI助手控制各种系统并完成复杂任务时,这一幕曾被视为遥不可及的科幻场景。然而,随着大型语言模型(LLM)和多模态大模型(MLLM)的快速发展,这样的智能助手——现在我们称之为"智能体"(Agent)——正从科幻走向现实。
近年来,从OpenAI的ComputerUse到移动端的SpiritSight和MobileFlow,从学术研究到产业应用,智能体技术正经历前所未有的发展浪潮。本文将综合当前最前沿的研究成果,例如:
-
AppAgentX:Evolving GUI Agents as Proficient Smartphone Users
-
MobileFlow:A Multimodal LLM for Mobile GUI Agent
-
OS Agents:A Survey on MLLM-based Agents for General Computing Devices Use
-
SpiritSight Agent:Advanced GUI Agent with One Look.
为读者提供一份关于智能体技术的全面总结,特别关注其中发展最为迅速的GUI智能体领域。
1. 智能体的定义与分类
1.1 什么是智能体
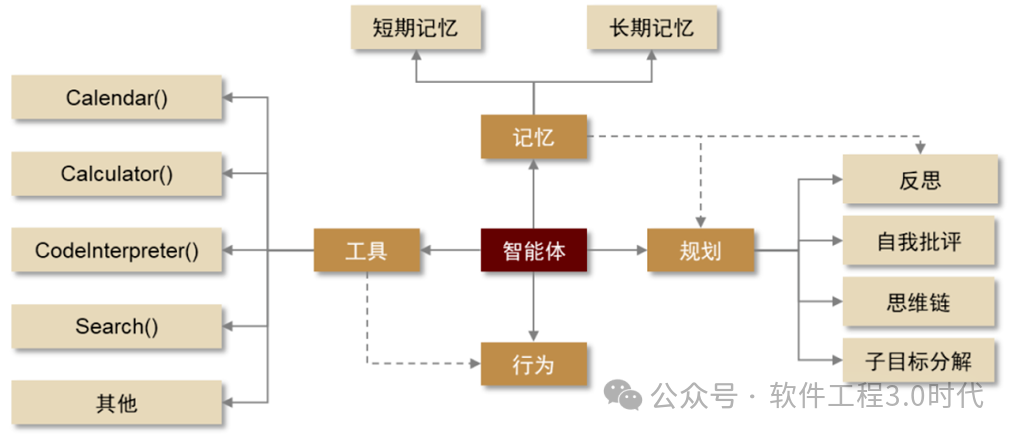
智能体(Agent)是一种能够感知环境、制定决策并采取行动以实现特定目标的AI系统,一般具有记忆、规划、采取行为、使用工具等基本能力,如下图所示,其中规划中有思维链、能进行反思、目标分解。与传统AI系统不同,智能体具有自主性、持续性和适应性,能够在复杂环境中持续学习和优化自身行为。
1.2 OS Agent:操作系统智能体
OS Agent(操作系统智能体)是一类特殊的智能体,它们通过操作计算设备(如计算机和移动手机)的图形用户界面(GUI)来完成各种任务。根据最新的OS Agent综述,这类智能体有三个关键组成部分:
-
环境:OS Agent所处的操作系统环境,如Windows、macOS、Android等
-
观察空间:智能体获取信息的方式,如界面截图、DOM结构等
-
行动空间:智能体可执行的操作集合,如点击、输入、滑动等
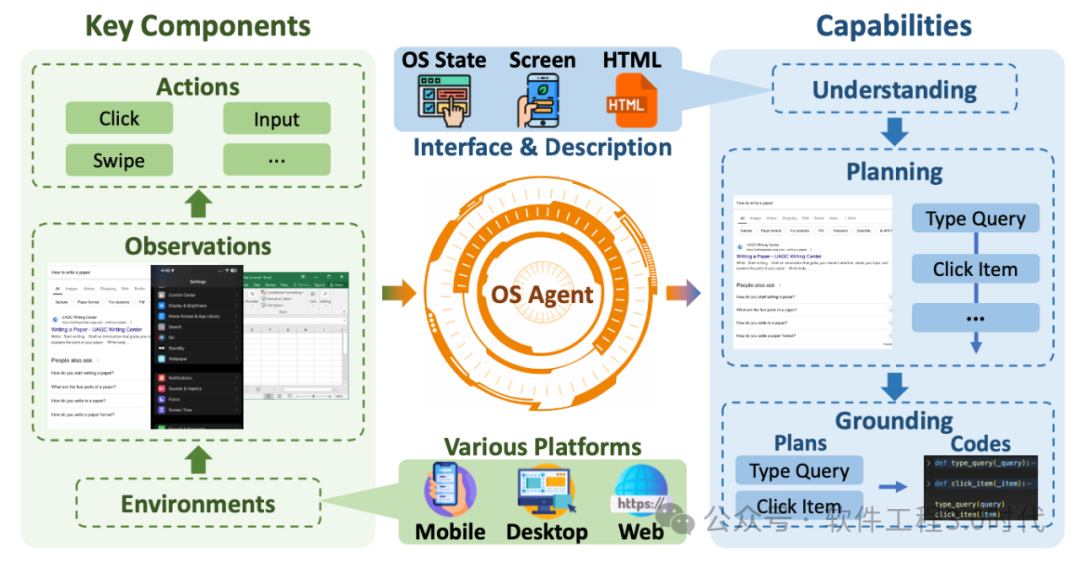
(来源于论文:OS Agents:A Survey on MLLM-based Agents for General Computing Devices Use)
1.3 智能体的主要分类
根据输入模态和技术实现,GUI智能体可分为三类:
-
基于语言的智能体:仅使用HTML/XML等文本描述作为输入
-
基于视觉的智能体:仅使用屏幕截图作为输入
-
视觉-语言混合智能体:同时使用屏幕截图和文本描述作为输入
其中,基于视觉的智能体(如SpiritSight)和视觉-语言混合智能体(如MobileFlow)因其跨平台兼容性和丰富的感知能力,正成为研究热点。
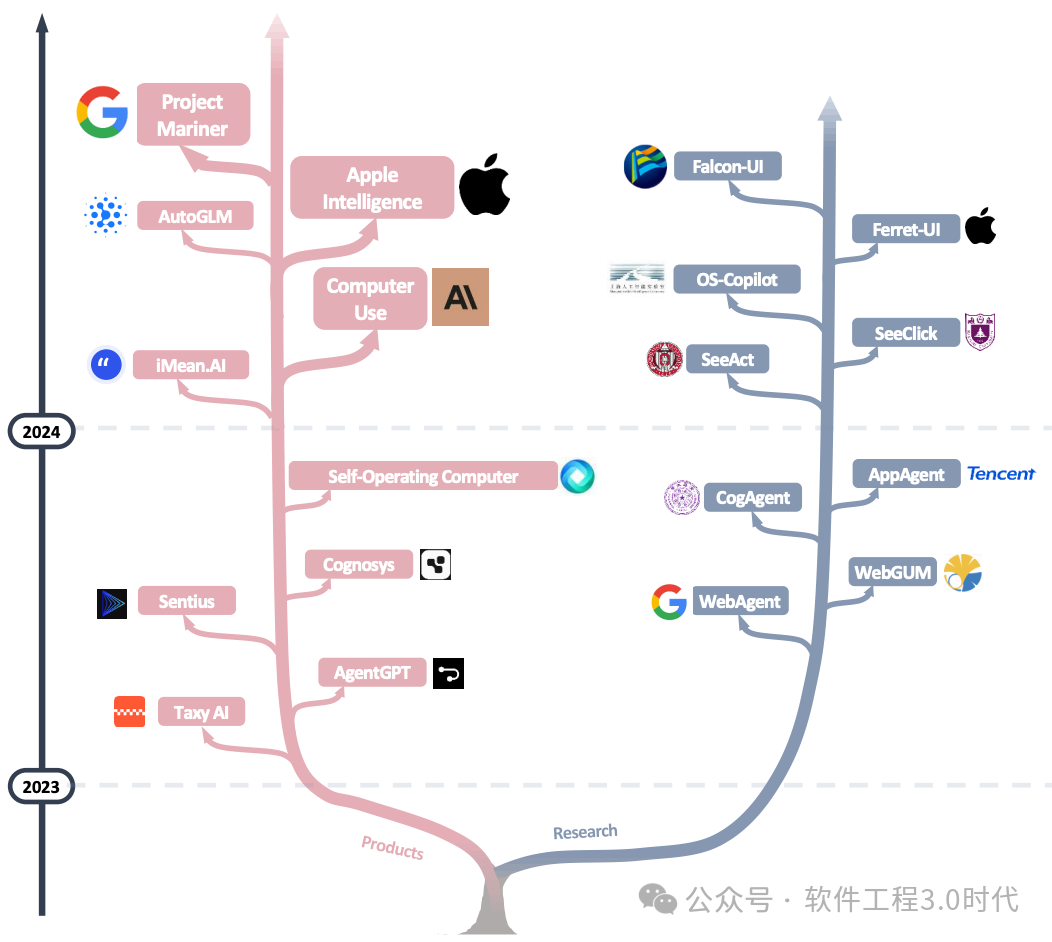
(来源于论文:OS Agents:A Survey on MLLM-based Agents for General Computing Devices Use)
2. 智能体的核心能力
现代智能体,特别是OS/GUI智能体,需要具备以下核心能力:
2.1 理解能力
理解能力是指智能体解读用户指令、理解任务目标的能力。最新研究如MobileFlow引入了GUI Chain-of-Thought(CoT)技术,使模型能够像人类一样进行推理,从而更好地理解复杂任务。
2.2 感知与定位能力
感知能力是智能体理解环境的基础。对GUI智能体而言,关键的感知挑战是元素定位(Element Grounding):
-
SpiritSight提出的Universal Block Parsing(UBP)方法解决了动态高分辨率输入中的歧义问题
-
MobileFlow的混合视觉编码器支持可变分辨率输入,提高了对细节的感知能力
-
OpenAI的ComputerUse则通过闭环视觉-操作系统直接分析整个屏幕并执行精确操作
2.3 规划能力
规划能力是智能体将复杂任务分解为步骤序列的能力。根据OS Agent综述,规划方法分为两类:
-
全局规划:在任务开始前规划完整的操作序列
-
迭代规划:根据环境反馈动态调整操作计划
如MobileFlow采用的四步法(观察、推理、行动、总结)就是一种有效的迭代规划框架。
3.4 操作能力
操作能力是智能体执行具体行动的能力,典型的GUI操作包括:
-
鼠标/触摸操作:点击、长按、拖拽
-
键盘操作:文本输入、快捷键
-
导航操作:滚动、翻页、切换标签等。
3. 当前智能体技术前沿
3.1 OpenAI的ComputerUse
OpenAI的ComputerUse是一项革命性技术,它使AI代理能够直接操作计算机界面:
-
技术原理:基于Computer-Using Agent (CUA)模型,结合GPT-4o的视觉能力和推理能力
-
工作流程:指令理解→动作生成→执行与反馈→状态理解→迭代改进
-
支持环境:浏览器、macOS、Windows、Ubuntu(暂不支持移动平台)
-
应用场景:自动化测试、探索式测试、回归测试、跨平台一致性测试等。
(有视觉能力的智能体)
3.2 SpiritSight:视觉导向的GUI智能体
SpiritSight代表了基于视觉的GUI智能体的最新进展:
-
核心创新:提出GUI-Lasagne多级大规模GUI数据集和Universal Block Parsing方法
-
技术特点:端到端、纯视觉感知,无需HTML/XML辅助
-
性能表现:在Multimodal-Mind2Web等多个基准测试中超越现有方法
-
跨语言能力:通过小规模目标语言数据微调,可实现跨语言(如中文)GUI操作
先分享到这里,可以关注再走哦,戳底部私信


















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









