





想象一下,你正在做一个 RK3588 的边缘 AI 项目:摄像头视频流需要实时做人脸识别、车辆检测,还要配合 UI、上传数据、处理业务逻辑。你发现:画面一多就掉帧,模型一大就跑不动,温度还蹭蹭往上涨。
这时候大家都会说一句:“你这个模型太大了,RK3588 的 6TOPS 不够用了。”
但真的是算力不够吗? 你有没有想过:为什么 6TOPS 的 NPU,跑一个 4TOPS 的模型,依然会卡顿掉帧? 问题的答案,藏在 NPU 算力的三个维度中:峰值(TOPS)、精度(INT8/FP16)和效率(带宽)。
你会看到各种芯片都在强调 NPU 的指标,都有一个核心参数写得很显眼: NPU 算力:X TOPS。无论是 RK3588-6TOPS、RK3576-6TOPS、RK1820-20TOPS、Hi3403V100-10TOPS、Hi3519DV500-2.5TOPS、Jetson Orin Nano-20/40TOPS、Jetson Orin NX-70/100TOPS……
TOPS 是什么?为什么人人都在提?
Tera(万亿):代表10¹²。
Operations Per Second(每秒操作次数):指NPU在一秒内可以执行的AI操作总次数。
简单来说,1 TOPS 就是指NPU每秒能执行一万亿次(10¹²)操作。
TOPS是如何计算的?
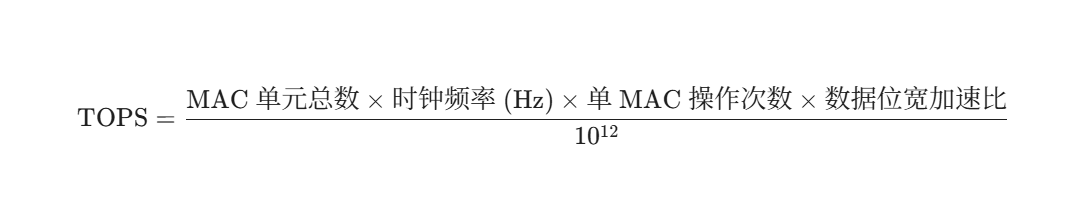
MAC 单元总数(MAC Units)是神经网络计算的核心。在卷积层和全连接层中,主要的计算就是将输入数据和权重相乘,然后累加起来。
NPU的设计理念就是拥有极大量的并行 MAC 单元阵列。一个NPU芯片可能拥有数千甚至数万个MAC单元,它们可以同时工作,实现大规模并行计算。
MAC 单元数量越多,NPU在一个时钟周期内能完成的运算量就越大。
时钟频率(Clock Frequency)频率决定了NPU芯片及其MAC单元每秒运行的周期次数(赫兹,Hz)。频率越高,MAC阵列在单位时间内就能执行更多的乘加操作。厂商在公布TOPS时,使用的是NPU的峰值运行频率(即能达到的最高频率)。
单 MAC 操作次数(Operations per MAC)一个完整的 MAC 操作实际上包含了一次乘法和一次加法。为了与传统的FLOPS(浮点运算)计数方法保持一致,许多计算标准将一个 MAC 操作计为 2 次基本运算(乘法计为1,加法计为1)。
数据位宽加速比(Precision Factor)NPU的MAC单元是为处理低精度数据(如INT8)而优化的。
INT8 vs FP32 的简化加速比: 由于32位 / 8位=4,理论上一个FP32单元在切换到INT8计算时,可以在一个周期内执行4倍的操作。因此,如果厂商的TOPS是基于INT8计算的,则需要乘以一个与位宽相关的加速比。这也是为什么 INT8 TOPS 远高于 FP32 TOPS 的原因。
TOPS衡量的是峰值理论算力。在实际应用中,由于数据传输、内存限制和模型结构等原因,NPU的实际有效算力往往会低于这个峰值。
算力讲速度,精度讲“细腻度”
算力告诉我们NPU跑得多快,而计算精度(Precision)则告诉我们它跑得多精细。精度是NPU性能的另一个关键维度,它决定了数据在计算过程中使用的位数和表示范围。

相同TOPS下,INT8的实际运算速度比FP32快得多。 这是因为NPU的MAC单元可以一次性处理更多的8位数据,执行更多的运算。
厂商标称的NPU TOPS通常都是基于INT8精度。 如果要进行比较,请确保比较的是同等精度下的TOPS。
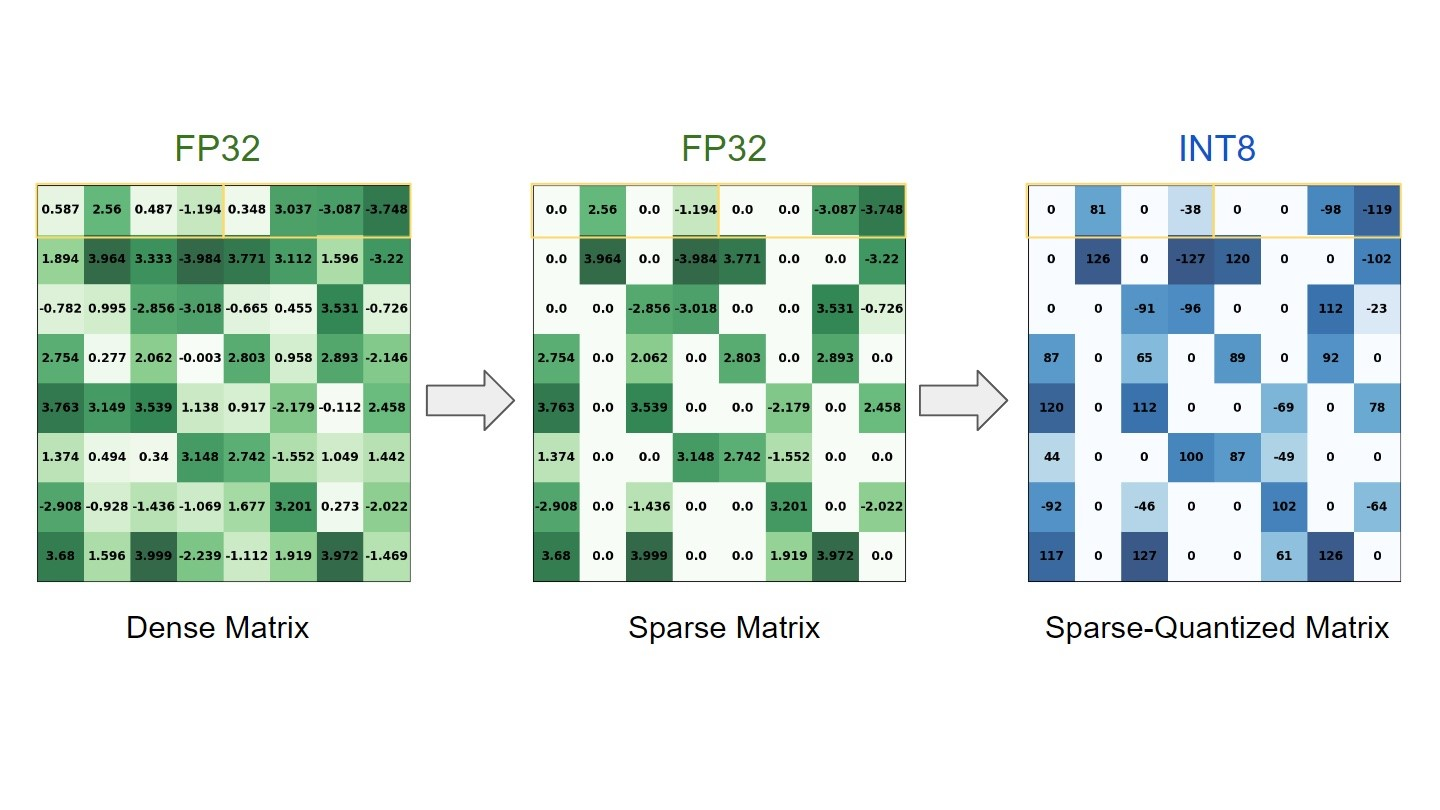
高精度(通常用于训练)
- FP32(单精度浮点,32位): 提供最大的数值范围和精度。在传统的GPU和PC计算中很常见。模型在训练阶段通常使用FP32以保证准确性。
- FP16/BF16(半精度浮点,16位): 在保持一定精度的同时,数据量减半,可以加快计算速度并节省内存。
低精度(通常用于推理)
- INT8(8位整数): 这是目前评估端侧NPU推理性能的行业标准。将高精度(如FP32)的模型权重和激活值转换为8位整数的过程称为量化 (Quantization)。
- INT4(更低位宽): 进一步压缩,适用于对功耗和延迟要求极高的场景,但对模型精度损失控制提出了更高要求。
如何理解NPU的实际性能?
当你看到一个NPU宣称20 TOPS (INT8)时,你需要理解:
- 峰值算力为每秒两十万亿次操作。
- 该算力是在8位整数(INT8)精度下测得的。 这意味着主要用于AI推理(如图片识别、语音处理等),而非训练。
- 最终性能取决于应用: 实际用户体验(如人脸解锁速度、实时翻译延迟)不仅依赖于NPU的TOPS,还依赖于:
- 模型的量化质量: 量化后的INT8模型是否保持了足够的准确度。
- 内存带宽: 数据输入和输出的速度。
- 软件栈和驱动: 芯片厂商提供的工具链和驱动程序对模型部署的优化程度。
NPU的算力(TOPS)是其速度的指标,而计算精度(如INT8)是其效率和适用性的关键。对于面向终端用户的设备,厂商普遍追求在保持可接受的精度损失的前提下,最大化INT8 TOPS,以达到低功耗、高效率的AI推理性能。


















 81
81

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











