





想象一下,你的设备里住着两位核心的“打工人”。
GPU(图形处理器): 是一位全能型运动健将,什么图像、视频、界面都能快速“处理一下”。它追求通用性和极致的图形渲染速度。
NPU(神经网络处理器): 是一位专门练 AI 的“肌肉型学霸”,只专注于一件事——把深度学习模型跑得又快又省电。它追求能效比和AI 推理的专属速度。
GPU 做事全面但不够节能,而 NPU 虽然专一却在 AI 推理上快得像开挂。如今越来越多设备谈论 NPU,正是因为它能让你的相机更聪明、设备更能“理解世界”,让 AI 体验真正飞起来。
通用王者:GPU (Graphics Processing Unit)
GPU 最初是为了加速图形渲染(特别是 3D 游戏)而设计的专用微处理器。核心优势在于能够以极高的并行度同时处理大量独立的计算任务。2007 年,NVIDIA 推出 CUDA 编程模型,首次允许开发者将 GPU 核心用于通用的科学计算任务。随着程序化渲染与通用计算需求的增长,GPU 逐渐演进为一种高并行度、适合处理数据密集型任务的通用计算平台(GPGPU)。
架构特点:大规模并行
GPU 内部包含数百至上万个计算核心(如 CUDA Cores / Stream Processors),通过 SIMT (Single Instruction Multiple Threads) 机制,实现对大规模数据的并行处理。
高并行度的效率体现在:矩阵运算、卷积运算、图形渲染流水线、大规模数据处理。
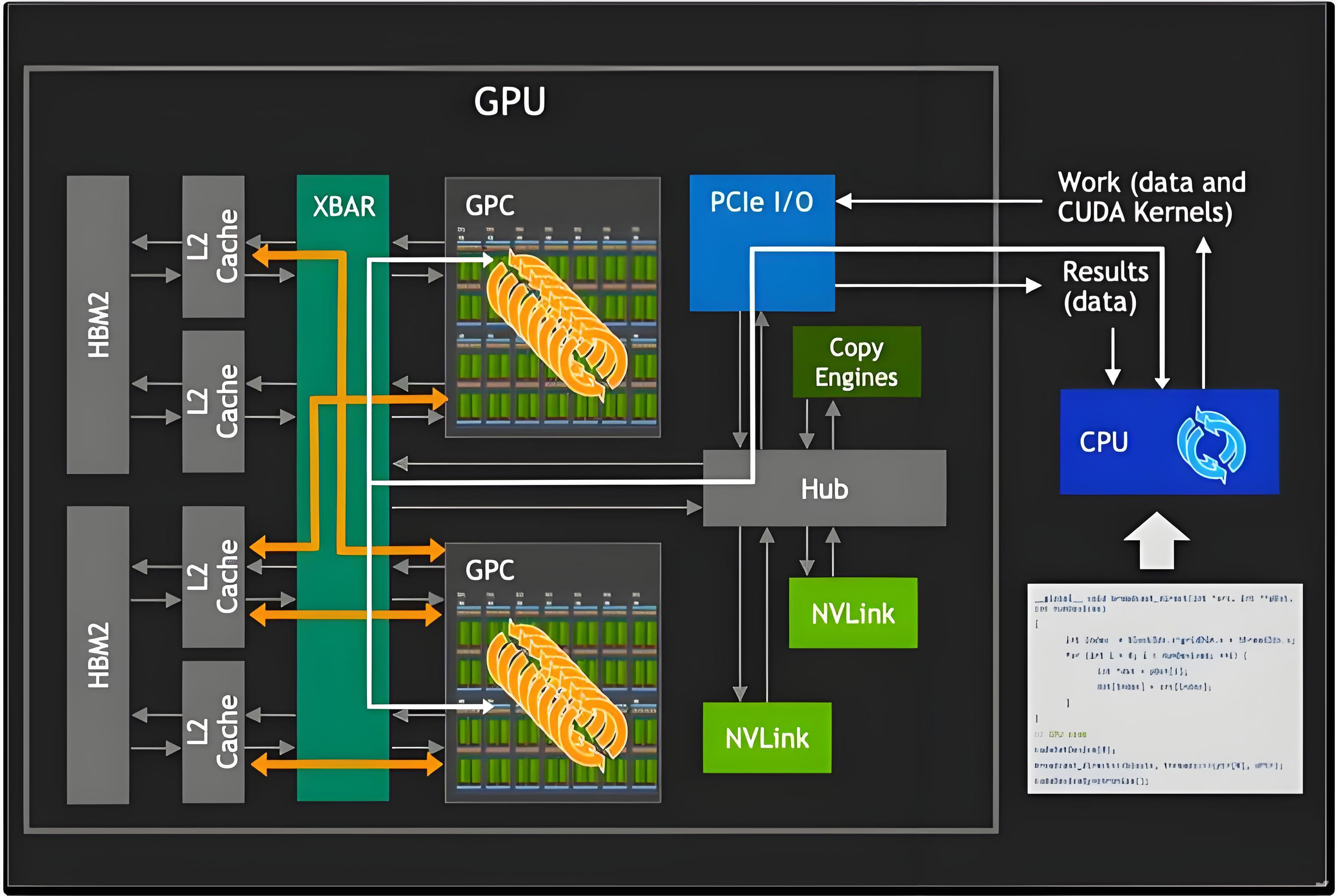
典型功能模块
GPU 通过 Vertex Shader(顶点处理)、Pixel/Fragment Shader(像素级运算)、Rasterizer(光栅化)、纹理单元(TMU) 等模块形成完整的图形流水线。这使其能够在毫秒级内处理成千上万的图元和像素,生成高分辨率、复杂的 3D 画面。
GPU 的应用领域
随着 CUDA、OpenCL 等通用计算接口的发展,GPU 的应用已从图形渲染扩展到:
深度学习:训练与推理
科学计算:CFD、分子模拟、物理仿真
数据中心加速:推理、搜索、数据库加速
边缘设备(SoC 中):UI 渲染、视频编解码、OpenGL ES/Vulkan 图形加速、部分 AI 算法的加速推理(在 NPU 不足或缺失时)。
专精之刃:NPU (Neural Processing Unit)
NPU 的诞生是为了解决 AI 模型部署到边缘设备时遇到的两大挑战:功耗限制和延迟需求。许多 AI 任务(如实时语音识别、自动驾驶)要求极低的延迟与较低的功耗,必须在本地即时完成计算。NPU 是一种专用型微处理器,其设计初衷是为了高效地执行深度学习模型的推理任务(Inference)。与追求通用性的 CPU 和 GPU 不同,NPU 追求的是针对神经网络计算的极致效率和能效比。
架构特点:矩阵乘加阵列
NPU 的计算核心由大量 MAC(Multiply-Accumulate,乘加)单元组成,用于执行深度学习中最基础、最频繁的运算:卷积(Convolution)和全连接(Matrix Multiply)。为了最大化深度学习模型的吞吐率,NPU 会设计:矩阵乘加阵列(Systolic Array / Tile Array): 将乘加器组织成高度并行的网格。数据流优化与复用: 最大限度地减少对外部存储器的访问。专用 ISA: 极简指令集,专为 AI 算子服务。
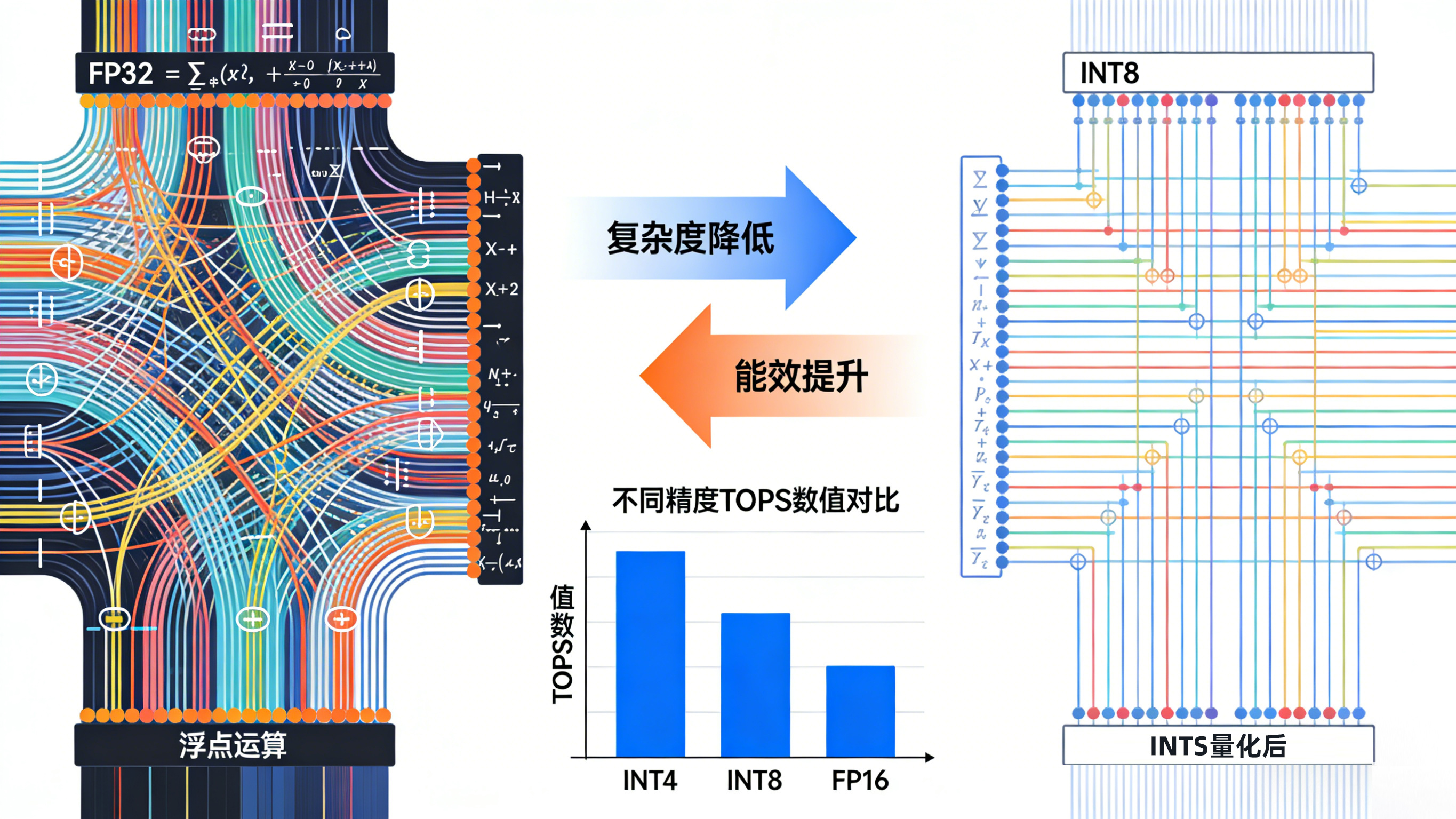
NPU 的高效来源于其独特的工作原理:
模型量化: 将复杂的浮点运算转换为简化的 INT8 整数运算,极大地降低了计算复杂度。
数据流融合: 数据和权重在阵列中像脉搏一样同步流动,相邻单元直接传递计算结果,最大限度地减少了对“内存墙”的访问,实现了极低的功耗和极高的能效比。
性能指标:TOPS 与精度
衡量 NPU 性能时,最常听到的单位是 TOPS(Tera Operations Per Second),表示 NPU 每秒可以执行多少万亿次运算(通常指 MAC 运算)。
当我们谈到 NPU 的性能时,最常听到的单位就是 TOPS。TOPS表示 NPU 每秒可以执行多少 万亿次运算(通常指 MAC 运算)。但需要注意的是:TOPS 的数值与计算精度密切相关。常用的精度格式包括 INT4、INT8、INT16、FP16、BF16 等。精度越低,单个数据占的位宽越小,NPU 在同样面积、同样带宽下可以塞进更多的并行计算单元和更高的数据吞吐,因此:
INT8 TOPS 最大(最常用),能效最高;
INT4 TOPS 更高,但适用模型有限;
FP16 / BF16 TOPS 较低,但计算更精确;

NPU 已成为嵌入式、边缘计算和终端设备的标配计算单元,例如:
- 手机/IoT:拍照优化、语音识别、图像分割、姿态识别。
- 智能摄像头:人脸识别、行人检测、多目标跟踪。
- 车载设备:ADAS 边缘推理、驾驶监控。
- 工业 AI:缺陷检测、OCR、目标识别。
GPU 和 NPU 并非相互取代的关系,而是在 AI 时代下扮演着生态位分工的角色:
- GPU: 依旧是AI 训练和复杂通用计算的核心算力。
- NPU: 负责将训练好的模型部署到边缘和终端设备,实现低功耗、低延迟的实时 AI 体验。
随着技术发展,现代 SoC(如 RK3588、Jetson Orin 系列)通常会同时集成高性能 GPU 和专用 NPU,让设备能够根据不同的任务需求,灵活调用不同的“打工人”,共同构建更智能、更高效的计算系统。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











