







 本文探讨了分布式系统的特性,包括分布性、对等性、并发性、缺乏全局时钟和故障等问题。接着讲解了分布式一致性、事务处理(如2PC和3PC)以及Quorum机制。重点介绍了Zookeeper中的分布式一致性算法,如Paxos和Raft,并讨论了它们在实际场景中的应用,如命名服务、配置管理和服务发现。
本文探讨了分布式系统的特性,包括分布性、对等性、并发性、缺乏全局时钟和故障等问题。接着讲解了分布式一致性、事务处理(如2PC和3PC)以及Quorum机制。重点介绍了Zookeeper中的分布式一致性算法,如Paxos和Raft,并讨论了它们在实际场景中的应用,如命名服务、配置管理和服务发现。
分布式:
分布式特性:
什么是分布式?个人理解,就是对一个系统进行拆分或者分割,达到性能横向扩展和增加可靠性的目的;
没有规定说必须是拆分出不同的工作分配到各个机器,即使是相同的功能也可以分配到各个机器上,形成一个分布式系统;
特点:
- 分布性(多台计算机空间上随意分布,可能随时变动)
- 对等性(副本)
- 并发性(可能同时操作数据库,造成数据不一致问题)
- 缺乏全局时钟(先后顺序无法保证)
- 故障(经常会有宕机,网络问题等)
分布式异常情况:
- 节点或机器故障:服务问题,机器硬盘等问题;
- 数据丢失:对于有状态节点在工作前需要恢复数据;
- 网络异常:消息丢失/延迟
- 网络分区:部分网络不通,造成整个系统网络环境被切分成若干个独立的区域;
分布式系统指标:
- 可用性:面对各种异常时可以正确提供服务的能力
- 可扩展性:性能(并发,存储,延迟)随着机器数量增长而得到线性提升;
- 一致性:读写操作数据的一致性;
- 分区容错性:
一致性理解:
为什么会有一致性问题?
当服务是有状态的,在分布式系统中,就会涉及到拆分,为了提高可用性,就会涉及副本,那就会出现该问题;
还有一种是,为了提高扩展性,比如读写分离,主从模式下,主写,从读,也会出现该问题;
一致性类别:
强一致性,读写一致性,单调读一致性,因果一致性,弱一致性(不保证立即读到最新,不保证多久后达到一致),最终一致性(弱一致性的特例,在一定时间内保证最终一致);
强一致性和性能冲突,很难保证;
那么剩下的几种一致性又是如何保证的呢;
分布式事务:
acid,单机下比较好处理;可以先了解下单机如何处理事务;
分布式下,需要2pc两阶段提交;
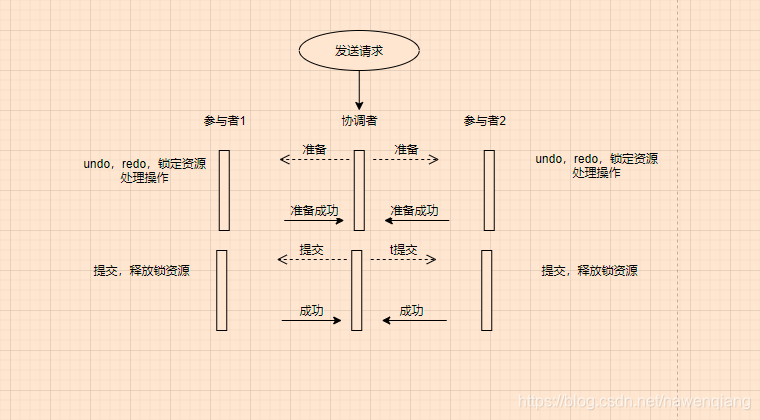
其他场景,无需资源锁定,直接操作;
2pc存在的问题:
- 一段阻塞,等待资源,影响性能
- 二段提交丢失/或者处理异常,造成数据不一致
- 必须收到所有准备没问题,才提交,否则整体回滚,没有容错机制,太保守
- 协调者单点故障
3pc流程:
- 询问,是否可以进行事务操作(2pc一段阻塞问题,得以改善,无需浪费时间阻塞线程等待资源)
- 预提交,类似于2pc一段,增加了超时自动提交
- 最终提交,类似2pc二段
仍然存在:数据可能不一致情况、单点故障问题。
Quorum机制:
在了解分布式一致性算法前,先要直到该机制是什么,因为后续要用到;
N:要复制的节点数;
W:写入成功的节点数;
R:读到最新数据所需的节点数;
情景1):W=1,R=N,写一份,写操作高效,但是,读操作效率低,要多N次才能读到最新数据,一致性简单,分区容错性差;
情景2):W=N,R=1,全部写完才能可用,如果某个写失败,整体失败,写操作效率低,读操作效率高,分区容错性高,一致性复杂;
情景3):W=(N/2+1),R=(N/2+1),写入超过一半,那么读也将超过一半,整体性能均衡,
分布式一致性算法:
议会制:超过一半达成一致即可
paxos:
角色:
proposer(提议者),acceptor(接收者),learner(学习者);相当zk的,leader,follower,observer;
流程:
提案内容(trx id + value)
- 阶段一:
(a) Proposer选择一个提案编号N,然后向半数以上的Acceptor发送编号为N的Prepare请求。
(b) 如果一个Acceptor收到一个编号为N的Prepare请求,若等待accept中(若N小于Prepare请求编号,则忽略或回复错误),将已经accept 过的编号最大的提案(如果有的话)作为响应反馈给Proposer,同时该Acceptor承诺不再接受任何编号小于N的提案。
- 阶段二:
(a) 如果Proposer收到半数以上Acceptor对其发出的编号为N的Prepare请求的响应,那么它就会发送一个针对[N,V]提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value,如果响应中不包含任何提案,那么V就由Proposer自己决定。
(b) 如果Acceptor收到一个针对编号为N的提案的Accept请求,若等待accept中(若N小于Prepare请求编号,则忽略或回复错误),若N大于已经accept 过的编号最大的提案,它就接受该提案。
问题:
多个提议者可能导致死循环(在于处理逻辑),因此选出一个主proposer,只有主proposer才能提案;
使用场景:主从同步;选举(把处理逻辑改一改,就可以);
关键:
递增的、唯一的trx id;
raft:
角色:leader,follower,candidate
同步:
- client修改操作经过leader,写日志,一直发送给follower写日志,直到所有都成功(带上上次的trx id,term的id,如果trxid不等于当前trxid,拒绝操作并返回当前trxid,让leader直到自己的位置并重新发送丢失的数据)
- 回应后,leader返回给client,提交,心跳机制发送给follower包含提交操作;
竞选:
- 超时机制,follower等待成为candidate的等待时间(随机150-300ms)选举定时器;心跳机制,leader定时向follower发送心跳;
- 选举定时器内,若没收到leader心跳,成为candidate,直到任意条件发生:1)成为leader;2)他人成为leader;3)没有leader,term结束,随机设置选举定时器;
- candidate发送投票请求向follower,半数以上同意,成为leader,如果一定时间内,没有leader,term结束;
ZK应用场景:
- 命名服务,zk工具client.sh使用时,create -s操作会创建有序号节点,且全局唯一,通过这种方式生命UID,然而,意义不大,zk主要用于多读少写情况,同时,事务串行,对性能影响很大,因此,qps几千倒是可以用用,不过一般服务,如cookie mapping,也都会自己生成UID;
- 配置,zk工具client.sh使用时,setdata可以设置节点数据,服务通过订阅方法(watch)发现更改;配置方法:单节点配置;或者单目录下多个节点分别配置;或者前两者结合,单节点配置一些单个节点信息,然后分别获取每个节点详细信息;
- 服务发现,zk工具client.sh使用时,create -e操作会创建临时节点,断开链接,节点会被删除,服务通过订阅方法(watch)发现更改;当节点少的时候,目前200左右没发现啥问题,但节点数量大的时候,对于抖动,会对整个集群有很大影响;


















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











