







Paper地址:https://arxiv.org/abs/2203.08991
GitHub链接:amodaresi/AdapLeR
随着AI软硬件基础设施的日趋完善(包括算法框架、推理引擎、编译器与底层硬件等),从算法或模型视角的性能优化,已经成为降低计算复杂度、节省资源成本的必不可少的技术手段。
前言
基于生成式自监督训练(Generative Self-supervised Learning),预训练模型能够充分掌握语境相关的知识与信息,典型代表如BERT预训练任务MLM、ViT预训练任务MAE、推荐模型预训练任务Next-query Prediction等。对于BERT模型而言,在充分的大规模预训练之后,针对特定的下游任务,凭借语境知识与少量Token信息,便足以完成NLP任务。因此,基于Sequence的Token表示冗余,可通过逐层消减Sequence length的方式、达成BERT推理加速。
基于BERT模型压缩技术(如剪枝、量化等),可实现BERT推理加速,本质而言实现了模型结构精简(静态优化,推理时模型结构固定)。从另一个角度而言,由于Sequence存在表示冗余,因此BERT模型中不同Layer的输出特征序列、可通过动态方式进行Sequence length的消减(Sample-driven length reduction),本质而言实现了数据结构精简(动态优化,推理时数据结构随Sample变化)。AdapLeR便是一种基于Sequence length reduction的动态优化策略,以实现BERT推理加速。
BERT/Transformer模型压缩与推理加速,更为详细的讨论可参考:
实现方法
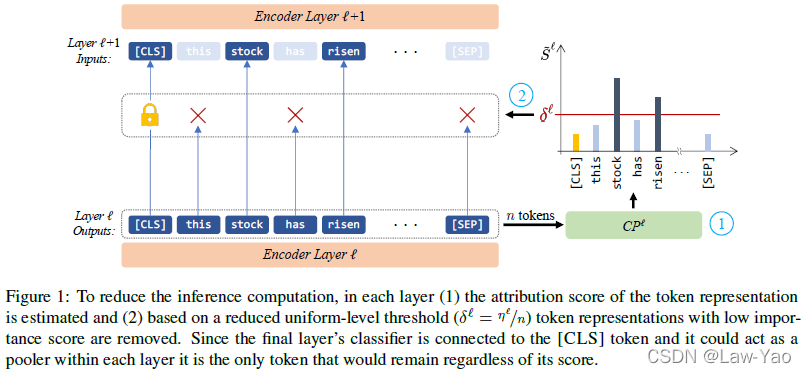
如上图所示,AdapLeR在每个BERT layer设置了Contribution predictor (CP),用于估计第l个Layer输出特征的Per-token saliency (每个Token的重要性),以消减Less contributing tokens,从而实现Inference加速。由于[CLS] token起Pooler作用(代表整个Sequence的语义或表征),直接反映下游任务的精度表现,因此[CLS] token不会被消减(尽管CP预测得分可能较低)。且在Inference阶段(Batch size=1),相比于模型整体的推理耗时,CP的预测耗时可忽略。
AdapLeR的动态优化策略或动态推理方式,依赖于每个Layer的CP与Uniform-level阈值,执行方式如下:
-
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









