



 本文详细介绍了如何使用Matlab和Python实现多分类任务,包括矩阵操作、概率计算、损失函数计算及梯度计算等核心步骤。通过对比两种语言的实现方式,帮助读者理解并掌握多分类问题的解决方法。
本文详细介绍了如何使用Matlab和Python实现多分类任务,包括矩阵操作、概率计算、损失函数计算及梯度计算等核心步骤。通过对比两种语言的实现方式,帮助读者理解并掌握多分类问题的解决方法。
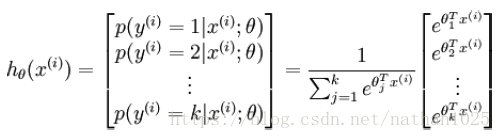
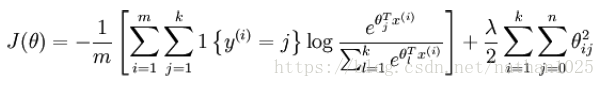
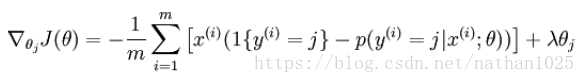 、
、
Matlab:
theta = reshape(theta, numClasses, inputSize);
numCases = size(data, 2);
% groundTruth = full(sparse(labels, 1:numCases, 1));
%
labels = repmat(labels, numClasses, 1);
k = repmat((1:numClasses)',1,numCases);% numClasses×numCases.
groundTruth = double((k == labels));% % groundTruth algrithum is the same as (k===label)
thetagrad = zeros(numClasses, inputSize);cost = 0;
z = theta*data;
z = z - max(max(z)); % avoid overflow while keep p unchanged.
z = exp(z); % matrix product: numClasses×numCases
p = z./repmat(sum(z,1),numClasses,1); % normalize the probbility aganist numClasses. numClasses×numCases
cost = -mean(sum(groundTruth.*log(p), 1)) + sum(sum(theta.*theta)).*(lambda/2);
thetagrad = -(groundTruth - p)*(data')./numCases + theta.*lambda; % numClasses×inputSizepython:
#theta.shape==(k,n+1)
#lenda是正则化系数/权重衰减项系数,alpha是学习率
def J(X,classLabels,theta,alpha,lenda):
bin_classLabels=label_binarize(classLabels,classes=np.unique(classLabels).tolist()).reshape((m,k)) #二值化 (m*k)
dataSet=np.concatenate((X,np.ones((m,1))),axis=1).reshape((m,n+1)).T #转换为(n+1,m)
theta_data=theta.dot(dataSet) #(k,m)
theta_data = theta_data - np.max(theta_data) #k*m
prob_data = np.exp(theta_data) / np.sum(np.exp(theta_data), axis=0) #(k*m)
#print(bin_classLabels.shape,prob_data.shape
cost = (-1 / m) * np.sum(np.multiply(bin_classLabels,np.log(prob_data).T)) + (lenda / 2) * np.sum(np.square(theta)) #标量
#print(dataSet.shape,prob_data.shape)
grad = (-1 / m) * (dataSet.dot(bin_classLabels - prob_data.T)).T + lenda * theta #(k*N+1)
return cost,grad下式即: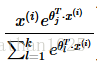 =====
===== ![]()
prob_data = np.exp(theta_data) / np.sum(np.exp(theta_data), axis=0)

https://www.cnblogs.com/Deep-Learning/p/7073744.html
https://blog.youkuaiyun.com/jiede1/article/details/76983938

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









