




以防读者不了解夜莺,开头先做个介绍:
夜莺监控,英文名字 Nightingale,是一款侧重告警的监控类开源项目。类似 Grafana 的数据源集成方式,夜莺也是对接多种既有的数据源,不过 Grafana 侧重在可视化,夜莺是侧重在告警引擎。比如把 Prometheus、VictoriaMetrics、ElasticSearch 等作为数据源接入夜莺,即可在夜莺里配置告警规则做指标、日志的告警。当然了,夜莺也不止做告警,还提供了 ad-hoc 查询、指标视图、仪表盘等可视化能力,不过在可视化方面没有 Grafana 道行深。配合 Categraf 采集器,夜莺可以做到一站式监控。其项目地址是:https://github.com/ccfos/nightingale
近期,夜莺监控项目发布了 v8.0.0-beta10 版本,虽然是 beta 版本,实际是稳定的,可以放心升级,只不过要配合市场工作会把正式版放到每年 7 月发布。这个版本最重要的变化,是支持在中心端无法连通的时序库的告警。
示意图
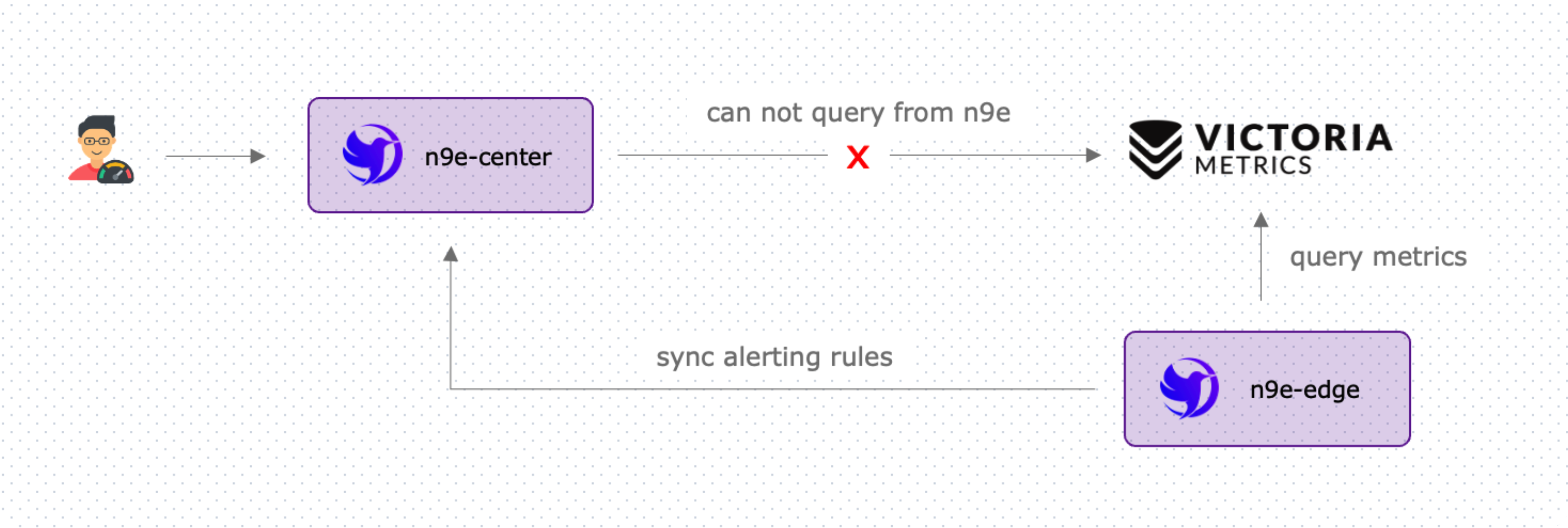
通常来讲,夜莺只需要部署中心端一个 n9e 进程即可,使用这个 n9e 进程去对接各个时序库、日志库,做查询、告警等。在网络环境比较好的情况下是 ok 的,但是有的时候,中心端无法直连边缘机房的时序库(可能是因为安全性、合规等各种因素),只能是边缘机房连中心。此时,要想在中心机房统一看数据是不行的,但是仍然可以在中心统一管理告警规则,对边缘机房的时序库做告警。这个版本就支持了这个场景。
老版本夜莺要处理边缘机房的场景,需要在「数据源」那里把边缘机房的时序库地址配置上,但是中心端连不上边缘机房,保存的时候会报错。新版本支持了仅保存不做连通性校验的能力,配合「时序库内网地址」的配置,就可以达成上图的效果了。
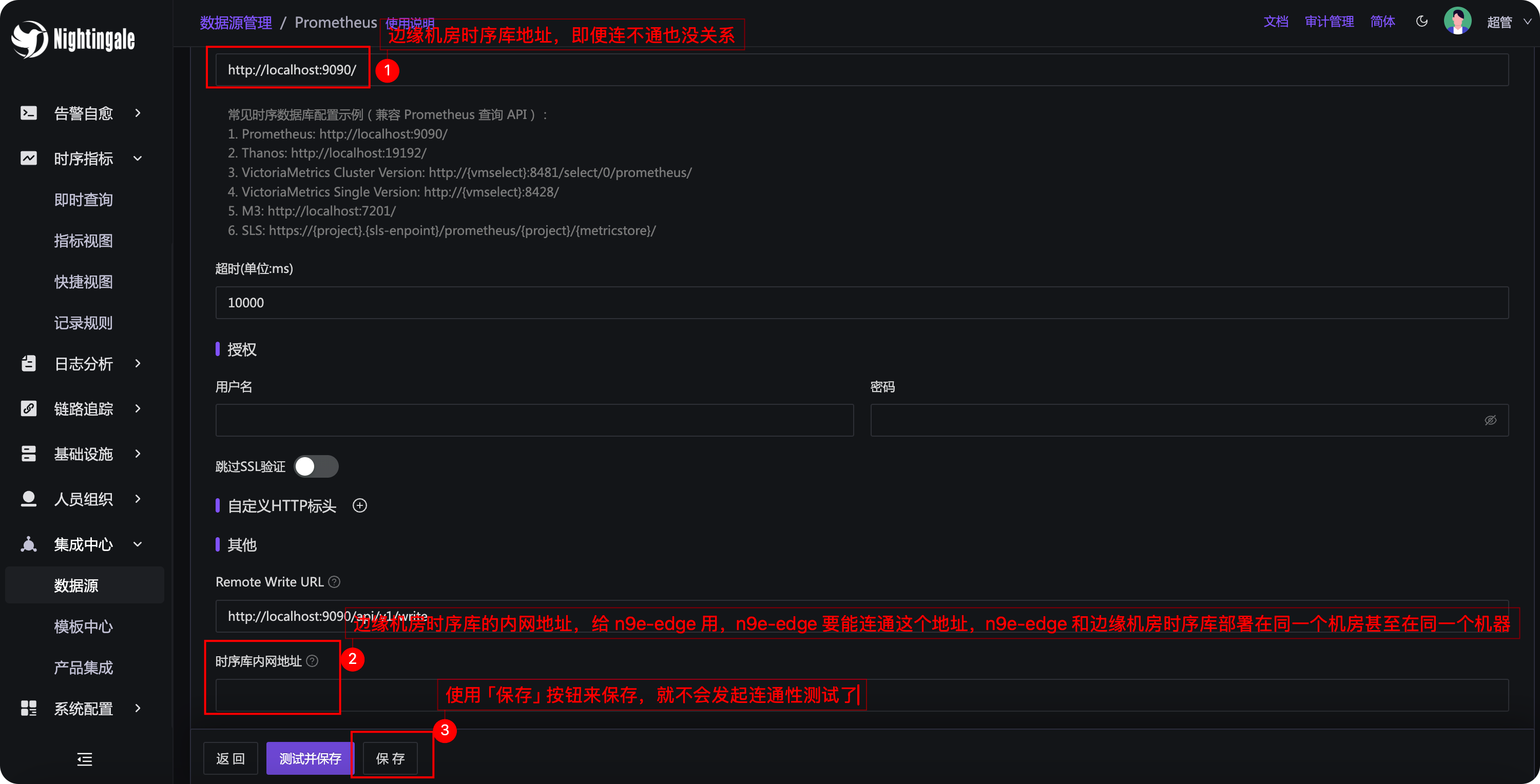
最终,n9e-edge 周期性调用 n9e 的接口同步告警规则,缓存在内存里(即便网络断了,还可以使用内存中缓存的规则),然后查询时序库(使用时序库的内网地址),做告警判定。在这个模式下,其实在夜莺的数据源页面那里,最上面 ① 的位置即便配置一个假地址都无所谓了,因为压根就不校验了。
其他更新
changelog 和新版下载地址:https://github.com/ccfos/nightingale/releases/tag/v8.0.0-beta.10,其他更新:
- feat: 仪表盘新版数据源选择器
- refactor: 仪表盘包含 “机器标识” 变量时禁止启用匿名访问
- refactor: 仪表盘下线 “业务组标识” 变量
- refactor: 告警规则默认执行频率改为 60 秒
- refactor: 记录规则表单页提交按钮统一改名为 “保存”
- refactor: 通知规则优化
- 告警规则的通知规则选择器添加查看规则功能
- 消息模板支持克隆
- 消息模板右侧文档宽度支持调节
- fix: 修复创建数据源后部分页面数据源类型未刷新问题
- fix: 修复告警规则克隆时遇规则被其他修改无法保存问题
- fix: 修复告警规则 Elasticsearch 源保存的字段路径错误问题
- fix: 修复 Elasticsearch 日志查询 Lucene 模式的过滤条件的字段值中包含 and or 等字符时会被自动转换成大写问题
- fix: 修复一些比较老的仪表盘导入后因为缺少 legend.placement 导致图例容器溢出问题
- fix: 修复折线图提示信息没有过滤掉空值图例问题
欢迎大家下载试用。有问题提 issue 即可,研发人员会持续关注。
总结
本文介绍夜莺新版本的一个重要更新,支持在中心端无法连通的时序库的告警。这个版本的更新增强了夜莺的灵活性和可用性,尤其是在复杂网络环境下的应用场景。希望大家能在实际使用中体验到这个新功能的便利。


















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











