




目前业界的日志生态,最常用的是 ELK,其次就是 ClickHouse,本文会演示如何使用 Vector + ClickHouse 来采集 Nginx 日志并做清洗,最终写入 ClickHouse。至于日志的可视化,后面再单独介绍,后面夜莺会把日志可视化能力下放到开源版本,之前跟映客的兄弟们交流准备一起搞,可惜迟迟没有抽出时间。别急,会有的,本文先把前半段完成,即日志的收集 + 传输 + 清洗 + 存储。存储显然是 ClickHouse,前面三个环节,使用 Vector 来完成。之前有一篇文章对 Vector 做过简单介绍,大家可以参考:《可观测性数据收集集大成者:Vector》。
配置 Nginx log
我们可以直接采集默认的 Nginx access log,不过我们可以走的更远一点,使用我们自定义的日志格式:
log_format track '$remote_addr - $time_iso8601 "$request_uri" '
'$status $body_bytes_sent "$http_user_agent"';
server {
location / {
access_log /var/log/track.log track;
return 200 'ok';
}
}
这个配置会把所有请求记录到 /var/log/track.log 文件中,样例如下:
127.0.0.1 - 2022-08-01T17:19:38+03:00 "/?test=1" 200 2 "curl/7.81.0"
这个日志是因为使用 curl 发起了一个如下请求:
curl "http://127.0.0.1/?test=1"
ClickHouse 表结构
下面我们创建一个 ClickHouse 表结构,用于存储 Nginx 日志,一般生产环境下,都是每个应用单独一个表,这样可以让不同的应用使用不同的日志字段,同时做了纵向切分,避免所有的日志存在一个表中导致表过大,影响查询性能。
CREATE TABLE log
(
`ip` String,
`time` Datetime,
`url` String,
`status` UInt8,
`size` UInt32,
`agent` String
)
ENGINE = MergeTree
ORDER BY date(time)
这个表基本够演示所用了。
安装 Vector
Vector 是一个用于构建数据传输 pipeline 的工具。它开箱即用支持 ClickHouse。使用 Vector Remap Language (VRL) 可以对日志进行清洗,把非结构化的数据清洗成结构化数据。
安装 Vector 较为简单,在 Ubuntu 上,可以使用如下命令:
curl -1sLf 'https://repositories.timber.io/public/vector/cfg/setup/bash.deb.sh' | sudo -E bash
sudo apt install vector
完事使用如下命令检查版本,如果正常输出,表示安装成功:
root@desktop:~# vector --version
vector 0.23.0 (x86_64-unknown-linux-gnu 38c2435 2022-07-11)
配置 pipeline
使用 Vector 配置日志流水线非常容易。整体上就是三步:采集 -> 处理 -> 输出,每个阶段都对应 Vector 配置中的 section,当然,采集可以有很多来源,处理也可以分多个环节,输出也可以有很多目的地。
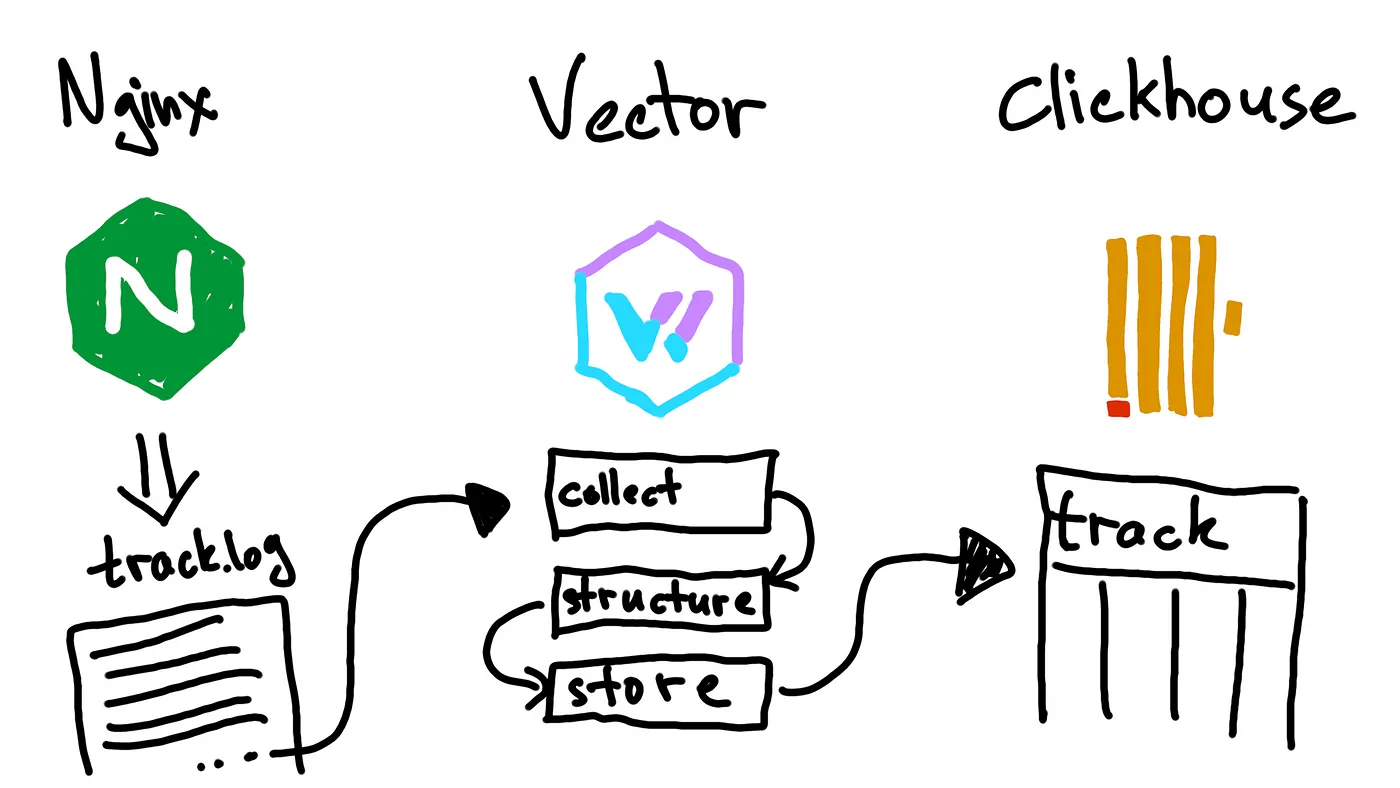
配置文件:/etc/vector/vector.toml,基础步骤包括:
- 1.
[sources.***]配置数据从哪里采集 - 2.
[transforms.***]配置数据如何清洗处理 - 3.
[sinks.***]配置数据输出到哪里
*** 的位置,是一个自定义的名字,可以随便取,但是要保证唯一。无论是 sources、transforms 还是 sinks,都可以有多个。
采集数据
我们故意修改了 Nginx 的日志格式,我们需要手工配置 pipeline。/var/log/track.log 日志文件内容现在是非结构化的,首先我们要用 Vector 读取它。
[sources.track]
type = "file"
include = ["/var/log/track.log"]
read_from = "end"
这里我们让 Vector 读取指定的日志文件,从文件末尾读取,只要 Nginx 有新的日志写入,Vector 就会读取到。
清洗数据
为了得到结构化的数据,我们在 VRL 中使用带有捕获组的正则表达式来处理每一行日志,这部分配置到 transforms 中。
[transforms.process]
type = "remap"
inputs = ["track"]
source = '''
. |= parse_regex!(.message, r'^(?P<ip>\d+\.\d+\.\d+\.\d+) \- (?P<date>\d+\-\d+\-\d+)T(?P<time>\d+:\d+:\d+).+?"(?P<url>.+?)" (?P<status>\d+) (?P<size>\d+) "(?P<agent>.+?)"$')
'''
Transform 部分的代码在 source 字段中,这段代码会解析日志并且把正则捕获组得到的信息放到对应的字段中。这些字段最终会被发给 ClickHouse。transform 有多种不同的类型,这里我们使用了 remap 类型,inputs 字段指定了输入源,这里是 track,即我们之前定义的源,inputs 是个数组,所以 transform 可以同时对接到多个 source 上。
存储数据
在把数据存到 ClickHouse 之前,让我们来检查一下数据是否正确。我们可以使用 console sink 来输出到控制台,这样我们可以看到 Vector 处理后的数据。
[sinks.print]
type = "console"
inputs = ["process"]
encoding.codec = "json"
这里定义了一个 sink:print,它的输入是 process,即我们之前定义的 transform。console sink 会把数据输出到控制台,encoding.codec 字段指定了输出的格式,这里是 json。如上配置都保存在 /etc/vector/vector.toml,然后使用交互模式运行 vector:
root@desktop:~# vector
使用 url 发起一个请求:127.0.0.1/?test=3,然后查看控制台输出:
root@desktop:~# vector
...
2022-08-01T14:52:54.545197Z INFO source{component_kind="source" component_id=track component_type=file component_name=track}:file_server: vector::internal_events::file::source: Resuming to watch file. file=/var/log/track.log file_position=497
{"agent":"curl/7.81.0","date":"2022-08-01","file":"/var/log/track.log","host":"desktop","ip":"127.0.0.1","message":"127.0.0.1 - 2022-08-01T17:52:58+03:00 \"/?test=3\" 200 2 \"curl/7.81.0\"","size":"2","source_type":"file","status":"200","time":"17:52:58","timestamp":"2022-08-01T14:53:04.803689692Z","url":"/?test=3"}
我们可以看到,除了解析出的字段之外,还有一些额外的字段,比如 timestamp、host、message 等,这些字段是 Vector 自动添加的。在数据最终发给 ClickHouse 之前,我们还需要在 transform 过程做一些额外的处理:
- 1.基于解析出的
date和time字段创建一个单独的datetime字段 - 2.把
status和size字段转换成整型
这两个改动都可以在 transforms 部分完成。
[transforms.process]
type = "remap"
inputs = ["track"]
source = '''
. |= parse_regex!(.message, r'^(?P<ip>\d+\.\d+\.\d+\.\d+) \- (?P<date>\d+\-\d+\-\d+)T(?P<time>\d+:\d+:\d+).+?"(?P<url>.+?)" (?P<status>\d+) (?P<size>\d+) "(?P<agent>.+?)"$')
.status = to_int!(.status)
.size = to_int!(.size)
.time = .date + " " + .time
'''
. 就相当于当前这条日志记录,.status 就是当前这条日志记录的 status 字段,to_int! 就是把 status 字符串转换成整型,+ 就是字符串拼接,最终把 date 和 time 字段拼接成 datetime 字段。这样我们就完成了数据的清洗。再次发起请求,查看控制台输出:
{"agent":"curl/7.81.0","date":"2022-08-01","file":"/var/log/track.log","host":"desktop","ip":"127.0.0.1","message":"127.0.0.1 - 2022-08-01T18:05:44+03:00 \"/?test=3\" 200 2 \"curl/7.81.0\"","size":2,"source_type":"file","status":200,"time":"2022-08-01 18:05:44","timestamp":"2022-08-01T15:05:45.314800884Z","url":"/?test=3"}
一切如预想。最终,我们可以配置数据存储到 ClickHouse,增加一个 sink 配置段,之前那个输出到 console 的 sink 可以删除了。
[sinks.clickhouse]
type = "clickhouse"
inputs = ["process"]
endpoint = "http://127.0.0.1:8123"
database = "default"
table = "log"
skip_unknown_fields = true
这里我们让 Vector 读取 process 这个 transform 环节产生的数据,然后发给 ClickHouse 中的 default 数据库中的 log 表。另外,我们增加了 skip_unknown_fields 配置项来跳过未知字段,这样即使我们的日志格式发生了变化,也不会影响数据的写入。
OK,保存配置文件,重启 Vector,向 Nginx 发一些测试数据,然后,我们就可以在 ClickHouse 中看到相关日志数据了。
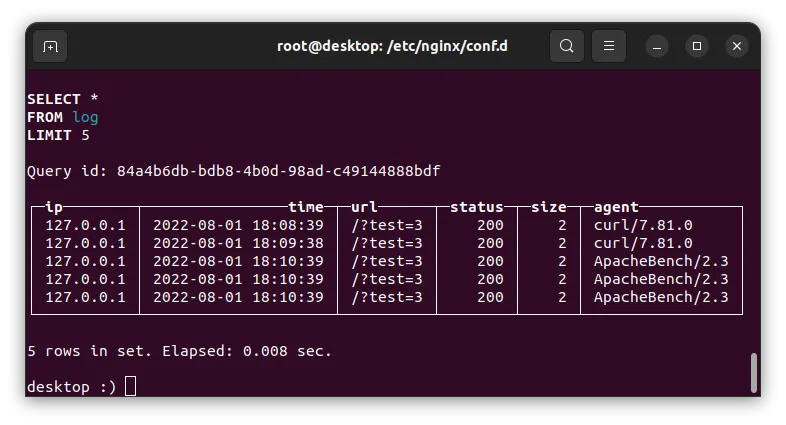
推到生产环境
vector 要在生产环境运行,就不要使用交互模式启动前台进程了,使用 systemd 或者 supervisord 之类的做进程托管。
性能考虑
我的电脑是 16C32G,可以轻松处理 2 万个请求每秒。需要几秒钟数据才能进入 ClickHouse,或许我们需要考虑使用 ClickHouse Buffer 表来优化插入性能。
小结
Vector 是一个很不错的工具,很方便的把 Nginx 日志采集、清洗、传输到 ClickHouse,Vector 提供强大的数据清洗能力,可以处理任何类型的非结构化数据。Cool。
下面是整个 vector.toml 的内容:
[sources.track]
type = "file"
include = ["/var/log/track.log"]
read_from = "end"
[transforms.process]
type = "remap"
inputs = ["track"]
source = '''
. |= parse_regex!(.message, r'^(?P<ip>\d+\.\d+\.\d+\.\d+) \- (?P<date>\d+\-\d+\-\d+)T(?P<time>\d+:\d+:\d+).+?"(?P<url>.+?)" (?P<status>\d+) (?P<size>\d+) "(?P<agent>.+?)"$')
.status = to_int!(.status)
.size = to_int!(.size)
.time = .date + " " + .time
'''
[sinks.clickhouse]
type = "clickhouse"
inputs = ["process"]
endpoint = "http://127.0.0.1:8123"
database = "default"
table = "log"
skip_unknown_fields = true
本文翻译自:https://medium.com/datadenys/using-vector-to-feed-nginx-logs-to-clickhouse-in-real-time-197745d9e88b ,感谢作者的分享。
本公众号主理人:秦晓辉,极客时间《运维监控系统实战笔记》作者,Open-Falcon、夜莺、Categraf、Cprobe 等开源项目的创始人,当前在创业,为客户提供可观测性相关的产品。如下是我们两款核心产品,欢迎访问我们的官网了解详情:
我们主要提供两款产品:

欢迎加我好友,交流可观测性相关话题或了解我们的商业产品,如下是我的联系方式,加好友请备注您的公司、姓名、来意 🤝

扩展阅读:


















 1696
1696

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











