




 本文深入探讨了Spark中RDD的分区机制,包括分区数量如何影响性能,不同操作如何改变分区数,以及Task的调度原理。理解这些概念对于优化Spark应用至关重要。
本文深入探讨了Spark中RDD的分区机制,包括分区数量如何影响性能,不同操作如何改变分区数,以及Task的调度原理。理解这些概念对于优化Spark应用至关重要。
分区(Partition)数
我们都知道一个 RDD 中有多个 Partition,Partition 是 Spark RDD 计算的最小单元,决定了计算的并发度。
分区数如果远小于集群可用的 CPU 数,不利于发挥 Spark 的性能,还容易导致数据倾斜等问题。
分区数如果远大于集群可用的 CPU 数,会导致资源分配的时间过长,从而影响性能。
那么,Partition 的数量是由什么决定的呢?
这个又得根据 RDD 的创建方式分为两种情况:
- 1、从内存中创建 RDD:
sc.parallelize(...),那么默认的分区数量为该程序所分配的资源的 CPU 数量。 - 2、从 HDFS 文件创建:
sc.textFile(...)或spark.sql(...),每个 HDFS 文件以块(Block)的形式存储,Spark 读取时会根据具体数据格式对应的 InputFormat 进行解析,例如文本格式就用 TextInputFormat 进行解析,一般是将若干个 Block 合并为一个输入分片(InputSplit),而这个 InputSplit 数就是默认的分区数。
然而,RDD 经过不同的算子计算后,分区数目又会变化。
- 通过 Generic Transformation 创建
filter(), map(), flatMap(), distinct()Partition 数量等于父 RDD 的数量。rdd.union(other_rdd)Partition 数量等于 rdd_size + other_rdd_sizerdd.intersection(other_rdd)Partition 数量等于 max(rdd_size, other_rdd_size)rdd.subtract(other_rdd)Partition 数量等 于rdd_sizerdd.cartesian(other_rdd)Partition 数量等于 rdd_size * other_rdd_size
- 通过 Key-based Transformation 创建
什么是 key-based?key-based 指的是执行 transformation 的 rd d都必须是 pair rdd,在 pyspark 中,并没有 pair rdd 这个类型,一个 rdd 要成为有效的 pair rdd,只需要 rdd 中的每条记录满足 k, v = kv,也就是只要是一个支持迭代,且一共含有两个元素的对象即可,可以是(k, v) ,也可以是[k, v], 也可以是自定义类型等。
在默认的情况下:reduceByKey(), foldByKey(), combineByKey(), groupByKey()partition 数量等于 parent rdd 的数量,使用 HashPartitioner,允许自己指定 hash 函数sortByKey()partition 数量等于 parent rdd 的数量,使用 RangePartitionermapValues(), flatMapValues()partition 数量等于 parent rdd 的数量,使用 parent rdd 的 partitioner,这两个函数接收的 parent rdd 必须为 pair rdd, 确保执行完以后保持原有 partition 不变join(), leftOuterJoin(), rightOuterJoin()partition 数量取决于相关的两个 rdd, 使用 HashPartitioner
Task 数
总的 Task 数
默认情况下,Task 的数量是由 Partition 决定的,RDD 计算时,每个分区会启一个 Task,所以 RDD 的分区数决定了总 Task 数。
在类 DAGScheduler 中的 submitMissingTasks 方法中,在 Stage 中会根据 RDD 的 Partitions 来获得一个 TaskSet,每个 Task 处理一个 Partition。
DAGSchedueler.scala:
Copy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
// From submitMissingTasks
...
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties)
}
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics)
}
}
}
...
|
HDFS File Block、InputSplit、Partition 和 Task 数量的关系可见下图: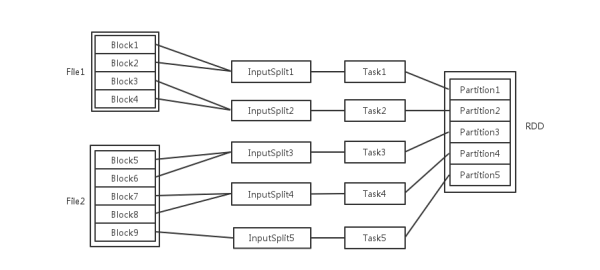
Task 的最大并发数
申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的 Task 数目。
同时又因为只有当前的 Stage 计算完成,才能计算下一个 Stage,一个 Stage 会为 RDD 的每个 Parition 生成一个 Task 任务,所以 Task 的并发数目还受 RDD 的分区数影响。
当 Task 被 Executor 提交后,会根据 Executor 可用的 CPU 核数,来决定一个 Executor 总同时可以执行多少个 Task。
在类 TaskSchedulerImpl 的 resourceOfferSingleTaskSet 方法中,CPUS_PER_TASK 的定义为val CPUS_PER_TASK = conf.getInt("spark.task.cpus", 1),也就是说默认情况下一个task对应cpu的一个核。如果一个executor可用cpu核数为8,那么一个executor中最多同是并发执行8个task;假如设置spark.task.cpus为2,那么同时就只能运行4个task。
TaskSchedulerImpl.scala:
Copy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// From resourceOfferSingleTaskSet
...
if (availableCpus(i) >= CPUS_PER_TASK) {
try {
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager(tid) = taskSet
taskIdToExecutorId(tid) = execId
executorIdToTaskCount(execId) += 1
executorsByHost(host) += execId
// 决定了一个 Executor 中可以运行多少个 Task
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
case e: TaskNotSerializableException =>
logError(s"Resource offer failed, task set ${taskSet.name} was not serializable")
// Do not offer resources for this task, but don't throw an error to allow other
// task sets to be submitted.
return launchedTask
}
}
...
|
Task 的调优
But!!!
通常根据默认情况下,Task 的数量是偏少的,如果 Task 数目偏少,就会导致前面设置好的 Executor 的参数都前功尽弃。
例如,Executor进程有很多个,CPU 和内存资源也相当充足,但是由于 RDD 的分区数较少,那么 Task 数也很少,那么很多 Executor 进程很可能根本就没有 Task 可以执行,导致并行执行的 Task 数太少,资源也就白白浪费了。
因此 Spark 官网建议的 Task 的设置原则是:设置 Task 数目为num-executors * executor-cores的2~3倍较为合适。例如 Executor 的总 CPU core 数量为300个,那么设置1000个 Task 是可以的,此时可以充分地利用 Spark 集群的资源。
Executor 数
num-executors = spark.cores.max / spark.executor.cores
spark.cores.max 是指你的 Spark 程序需要的总核数spark.executor.cores 是指每个 Executor 需要的核数
而这些参数是在使用 spark-submit 提交程序时,根据作业和集群的情况手动设置的(具体需要设置多少,那样根据 Spark 的调优经验来定了),因为默认情况下,只会启动少量的 Executor,无法发挥 Spark 集群的性能。
例如:
Copy
1 2 3 4 5 6 |
$ bin/spark-submit \ --master yarn-cluster \ --num-executors 100 \ --executor-memory 6G \ --executor-cores 4 \ -- ... |

















 4719
4719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









