




 本文详细介绍使用sklearn进行数据挖掘的步骤,包括数据预处理、特征选择与降维等关键技术,并介绍了并行处理、流水线处理、自动化调参及模型持久化的方法。此外,还涉及使用NumPy和SciPy进行数值分析的基础知识。
本文详细介绍使用sklearn进行数据挖掘的步骤,包括数据预处理、特征选择与降维等关键技术,并介绍了并行处理、流水线处理、自动化调参及模型持久化的方法。此外,还涉及使用NumPy和SciPy进行数值分析的基础知识。
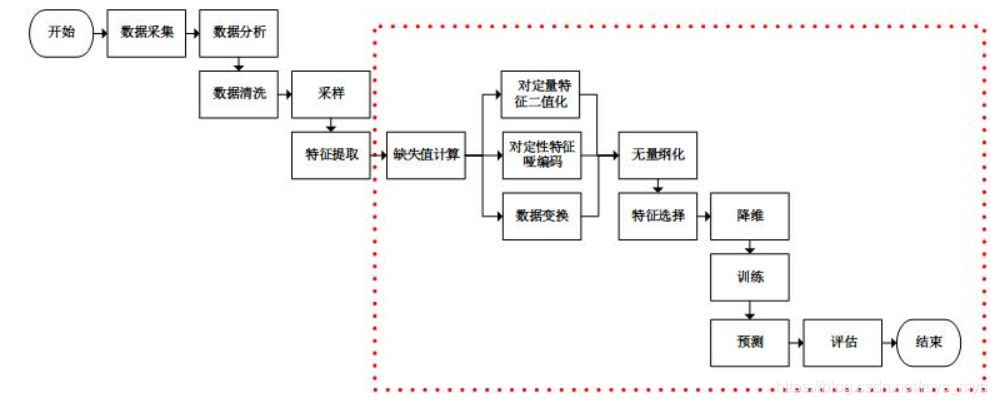
1. 数据挖掘步骤
数据采集,数据分析,特征工程,训练模型,模型评估
| 包 | 类 | 说明 |
|---|---|---|
| sklearn.perprocessing | StandardScaler | 标准化 |
| sklearn.perprocessing | MinMaxScaler | 区间缩放 |
| sklearn.perprocessing | Normalier | 归一化 |
| sklearn.perprocessing | Binarizer | 定量特征二值化 |
| sklearn.perprocessing | OneHotEncoder | 定量特征编码 |
| sklearn.perprocessing | Imputer | 缺失值计算 |
| sklearn.perprocessing | PolynomialFeatures | 多项式变换 |
| sklearn.perprocessing | FunctionThransformer | 自定义函数变换 |
| sklearn.feature_selection | VarianceThreshold | 方差选择 |
| sklearn.feature_selection | SelectKBest | 自定义特征评估选择 |
| sklearn.feature_selection | SelectKBest+chi2 | 递归特征消除法 |
| sklearn.feature_selection | RFE | 方差选择 |
| sklearn.feature_selection | SelectFromModel | 自定义模型训练选择法 |
| sklearn.decomposition | PCA | PCA降维 |
| sklearn.lda | LDA | LDA降维 |
关键技术:并行处理,流水线处理,自动化调参,持久化
训练好的模型是贮存在内存中的数据,持久化能够将这些数据保存在文件系统中,之后使用时无需再进行训练,直接从文件系统中加载即可。
2. 并行处理
并行处理使得多个特征处理工作能够并行地进行,分为:整体并行处理、部分并行处理
- 整体并行处理 pipeline FeatureUnion
from numpy import log1p
from sklearn.preprocessing import FunctionTransformer
from sklearn.preprocessing import Binarizer
from sklearn.pipeline import FeatureUnion
#新建将整体特征矩阵进行对数函数转换的对象
step2_1 = ('ToLog', FunctionTransformer(log1p))
#新建将整体特征矩阵进行二值化类的对象
step2_2 = ('ToBinary', Binarizer())
#新建整体并行处理对象
#参数transformer_list为需要并行处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
step2 = ('FeatureUnion', FeatureUnion(transformer_list=[step2_1, step2_2, step2_3]))
- 部分并行处理 FeatureUnionExt
from numpy import log1p
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import FunctionTransformer
from sklearn.preprocessing import Binarizer
#新建将部分特征矩阵进行定性特征编码的对象
step2_1 = ('OneHotEncoder', OneHotEncoder(sparse=False))
#新建将部分特征矩阵进行对数函数转换的对象
step2_2 = ('ToLog', FunctionTransformer(log1p))
#新建将部分特征矩阵进行二值化类的对象
step2_3 = ('ToBinary', Binarizer())
#新建部分并行处理对象
#参数transformer_list为需要并行处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
#参数idx_list为相应的需要读取的特征矩阵的列
step2 = ('FeatureUnionExt', FeatureUnionExt(transformer_list=[step2_1, step2_2, step2_3], idx_list=[[0], [1, 2, 3], [4]]))
3. 流水线处理
from numpy import log1p
from sklearn.preprocessing import Imputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import FunctionTransformer
from sklearn.preprocessing import Binarizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
#新建计算缺失值的对象
step1 = ('Imputer', Imputer())
#新建将部分特征矩阵进行定性特征编码的对象
step2_1 = ('OneHotEncoder', OneHotEncoder(sparse=False))
#新建将部分特征矩阵进行对数函数转换的对象
step2_2 = ('ToLog', FunctionTransformer(log1p))
#新建将部分特征矩阵进行二值化类的对象
step2_3 = ('ToBinary', Binarizer())
#新建部分并行处理对象,返回值为每个并行工作的输出的合并
step2 = ('FeatureUnionExt', FeatureUnionExt(transformer_list=[step2_1, step2_2, step2_3], idx_list=[[0], [1, 2, 3], [4]]))
#新建无量纲化对象
step3 = ('MinMaxScaler', MinMaxScaler())
#新建卡方校验选择特征的对象
step4 = ('SelectKBest', SelectKBest(chi2, k=3))
#新建PCA降维的对象
step5 = ('PCA', PCA(n_components=2))
#新建逻辑回归的对象,其为待训练的模型作为流水线的最后一步
step6 = ('LogisticRegression', LogisticRegression(penalty='l2'))
#新建流水线处理对象
#参数steps为需要流水线处理的对象列表,该列表为二元组列表,第一元为对象的名称,第二元为对象
pipeline = Pipeline(steps=[step1, step2, step3, step4, step5, step6])
4.自动化调参
from sklearn.grid_search import GridSearchCV
#新建网格搜索对象
#第一参数为待训练的模型
#param_grid为待调参数组成的网格,字典格式,键为参数名称(格式“对象名称__子对象名称__参数名称”),值为可取的参数值列表
grid_search = GridSearchCV(pipeline, param_grid={'FeatureUnionExt__ToBinary__threshold':[1.0, 2.0, 3.0, 4.0], 'LogisticRegression__C':[0.1, 0.2, 0.4, 0.8]})
#训练以及调参
grid_search.fit(iris.data, iris.target)
5.持久化
#持久化数据
#第一个参数为内存中的对象
#第二个参数为保存在文件系统中的名称
#第三个参数为压缩级别,0为不压缩,3为合适的压缩级别
dump(grid_search, 'grid_search.dmp', compress=3)
#从文件系统中加载数据到内存中
grid_search = load('grid_search.dmp')
| 包 | 类或方法 | 说明 |
|---|---|---|
| sklearn.pipeline | Pipeline | 流水线处理 |
| sklearn.pipeline | FeatureUnion | 并行处理 |
| sklearn.grid_searcn | GridSaerchCV | 网格搜索参数 |
| sklearn.joblib | dump | 数据持久化 |
| sklearn.joblib | load | 从文件系统中加载数据至内存 |
6.使用NumPy和SciPy进行数值分析
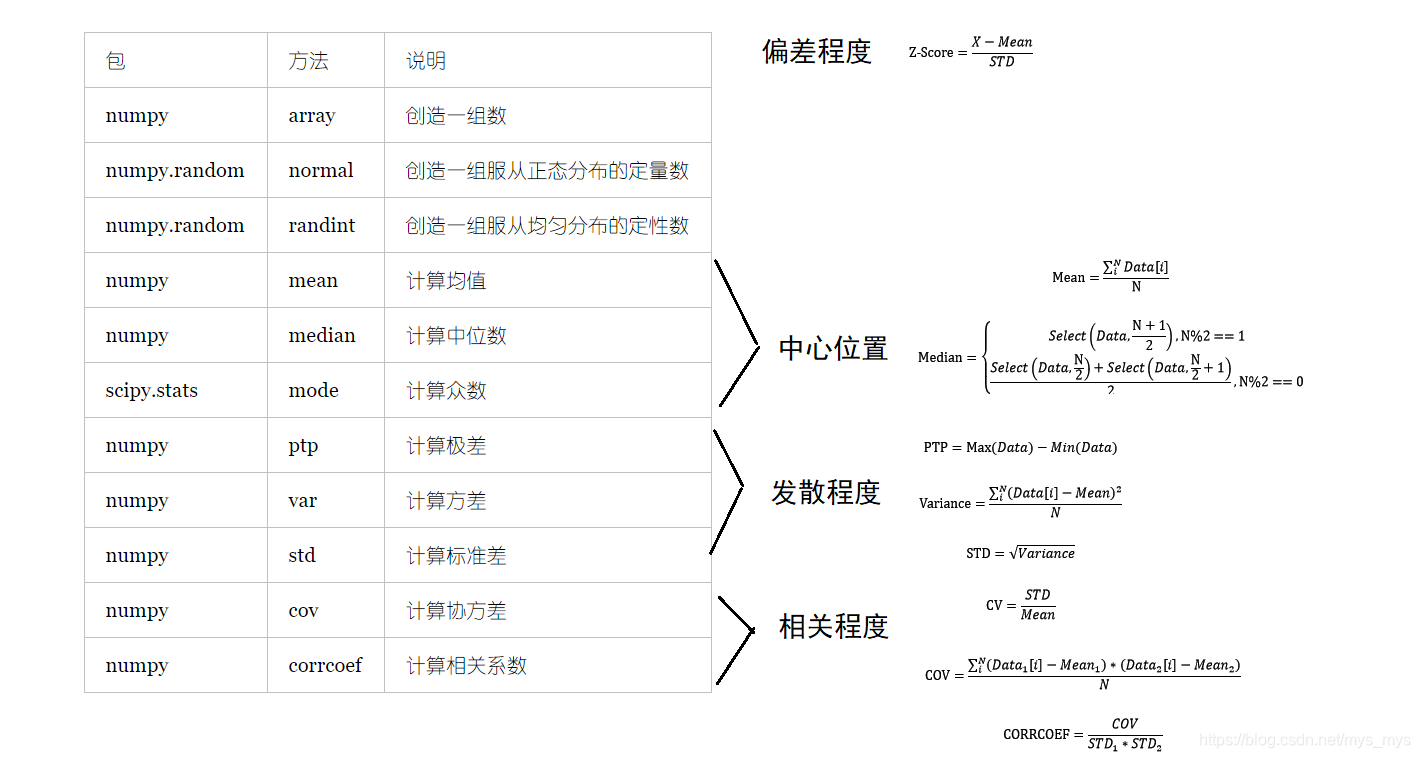
from numpy import array
from numpy.random import normal, randint
#使用List来创造一组数据
data = [1, 2, 3]
#使用ndarray来创造一组数据
data = array([1, 2, 3])
#创造一组服从正态分布的定量数据
data = normal(0, 10, size=10)
#创造一组服从均匀分布的定性数据
data = randint(0, 10, size=10)
from numpy import mean, median
#计算均值
mean(data)
#计算中位数
median(data)
from scipy.stats import mode
#计算众数
mode(data)
from numpy import mean, ptp, var, std
#极差
ptp(data)
#方差
var(data)
#标准差
std(data)
#变异系数
mean(data) / std(data)
from numpy import mean, std
#计算第一个值的z-分数
(data[0]-mean(data)) / std(data)
from numpy import array, cov, corrcoef
data = array([data1, data2])
#计算两组数的协方差
#参数bias=1表示结果需要除以N,否则只计算了分子部分
#返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的协方差。对角线为方差
cov(data, bias=1)
#计算两组数的相关系数
#返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的相关系数。对角线为1
corrcoef(data)

















 5629
5629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









