




 在使用PyTorch进行多GPU训练时,通过mp.spawn和DistributedDataParallel进行分布并行训练,需要注意在加载预训练模型时指定GPU。错误的做法是直接使用torch.load,这会导致每个进程都在GPU:0加载模型,占用大量显存。正确的解决方案是使用torch.load结合map_location参数,如`torch.load(pretrain_path, map_location=lambda storage, loc: storage.cuda(args.local_rank))`,确保模型加载到正确指定的GPU上。
在使用PyTorch进行多GPU训练时,通过mp.spawn和DistributedDataParallel进行分布并行训练,需要注意在加载预训练模型时指定GPU。错误的做法是直接使用torch.load,这会导致每个进程都在GPU:0加载模型,占用大量显存。正确的解决方案是使用torch.load结合map_location参数,如`torch.load(pretrain_path, map_location=lambda storage, loc: storage.cuda(args.local_rank))`,确保模型加载到正确指定的GPU上。
使用mp.spawn(main, nprocs=args.num_gpus, args=(cfg, args,))和torch.nn.distributed.DistrbutedDataParallel时出现显卡在
用torch.load加载预训练模型或恢复训练时必须指定放在哪个GPU上,否则默认是每个进程都会在GPU:0 上占一块空间,用来存放恢复数据,而且很大。nvidia-smi的结果中可以看到0号显卡上会有每个进程的编号。
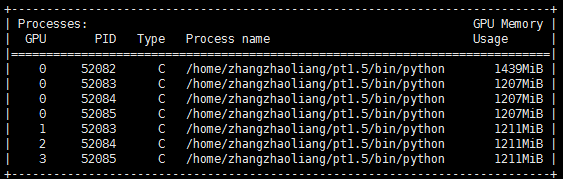
错误做法:
checkpoint = torch.load(pretrain_path)
正确做法:
checkpoint = torch.load(pretrain_path, map_location= lambda storage, loc: storage.cuda(args.local_rank))
args.local_rank是计算出来当前显卡在节点内的rank。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









