




AlchemistCoder
AlchemistCoder 是InternLM的代码生成模型
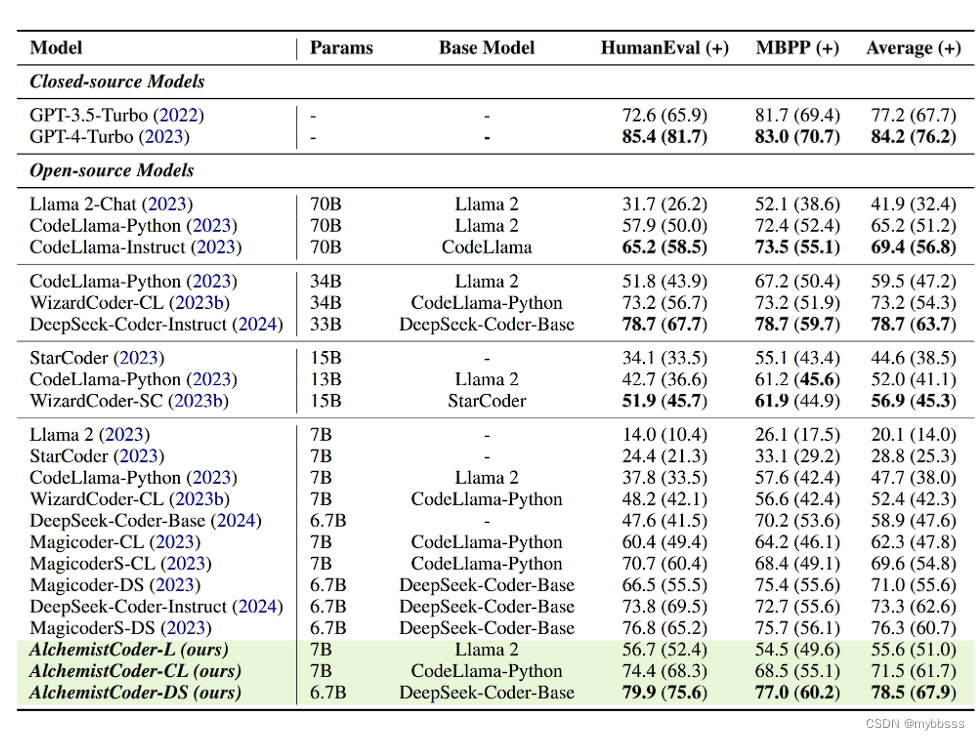
对比一下类似参数,近期评价很好的Qwen2-7B
下载模型
分别下载到本地(使用hf-mirror)
huggingface-cli download --resume-download internlm/AlchemistCoder-DS-6.7B --local-dir /root/models/AlchemistCoder-DS-6.7B/
huggingface-cli download --resume-download Qwen/Qwen2-7B-Instruct --local-dir /root/models/Qwen2-7B-Instruct/
运行评测
python run.py
--datasets humaneval_plus_gen \
--hf-path /root/models/AlchemistCoder-DS-6.7B \ # HuggingFace 模型路径
--tokenizer-path /root/models/AlchemistCoder-DS-6.7B \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='lef 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+



 到【灌水乐园】发言
到【灌水乐园】发言








