



介绍书生浦语
大模型的发展背景
大模型已成为发展通用人工智能的重要途径。从本世纪初至2021-2022年,研究主要集中在专用模型上,针对特定任务采用特定模型。然而,近两年趋势转向发展通用大模型,即一个模型应对多种任务和模态。
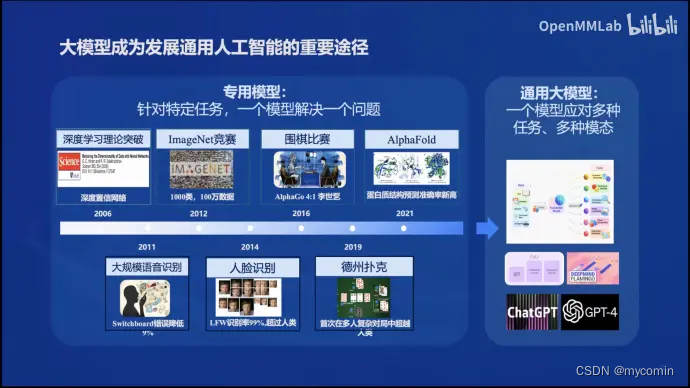
书生浦语大模型的特点
书生浦语大模型是一个全链条的开源体系,支持长达20万汉字的输入,是全球大模型产品中支持的最长上下文输入长度。模型具备超长上下文能力、推理数学代码能力、对话和创作体验,以及工具调用能力。
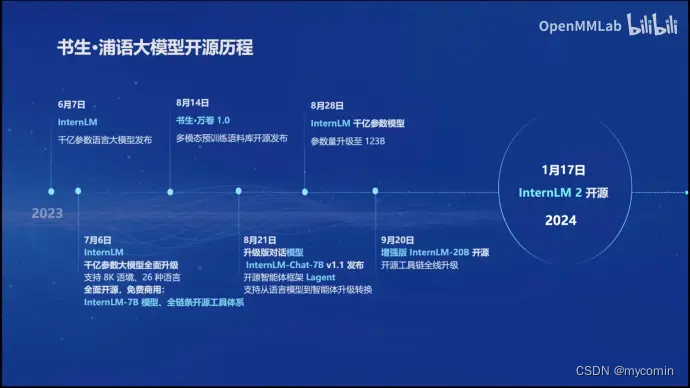
开源历程
书生浦语大模型自发布以来,经历了快速迭代。包括升级千亿参数大模型、支持8K语境、推出全免费商用的7B开源模型和全链条工具体系、发布多模态预训练语料库、升级对话模型等。
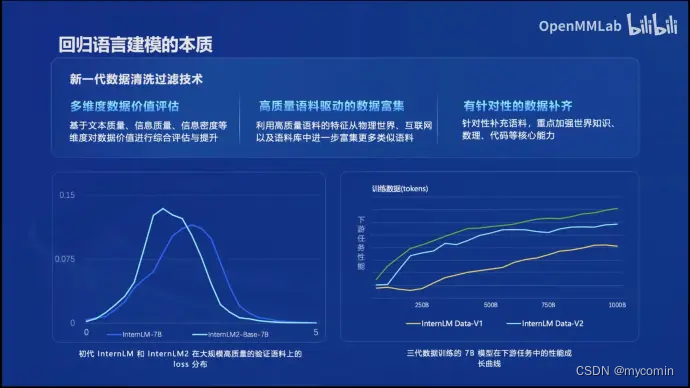
回归语言建模的本质
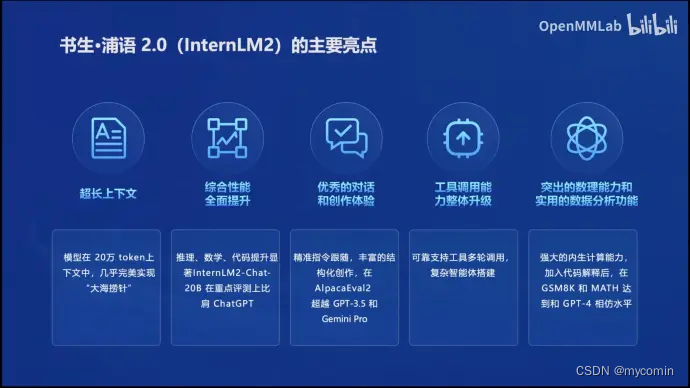
书生浦语2.0的主要亮点
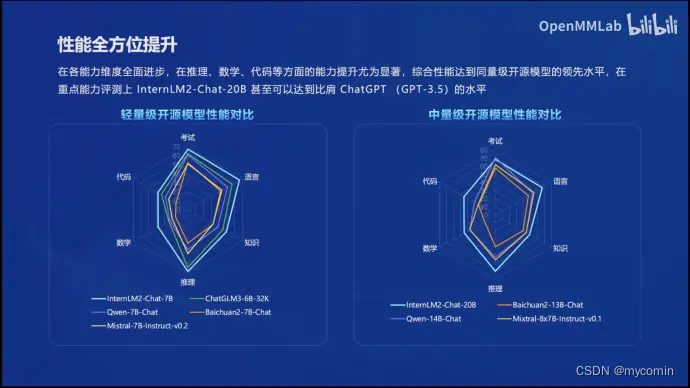
书生浦语的20B小参数模型在部分场景下达到接近或超越GPT-3.5的水平,换言之达到其他开源模型70B的效果,能有效减少调用成本。
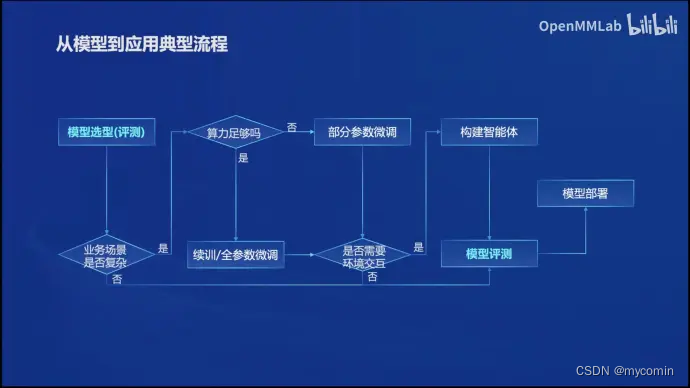
从模型到应用
全链路开放体系
为了简化从模型到应用的过程,开发了全链条的工具体系并开源。这包括数据集、预训练框架、微调框架、部署解决方案、评测体系和智能体框架等。这些工具支持从数据准备、模型训练、微调、部署到评测的整个过程,旨在帮助开发者和研究者更容易地使用和开发大模型应用。

数据集(书生万卷)

预训练框架InternLM-Train

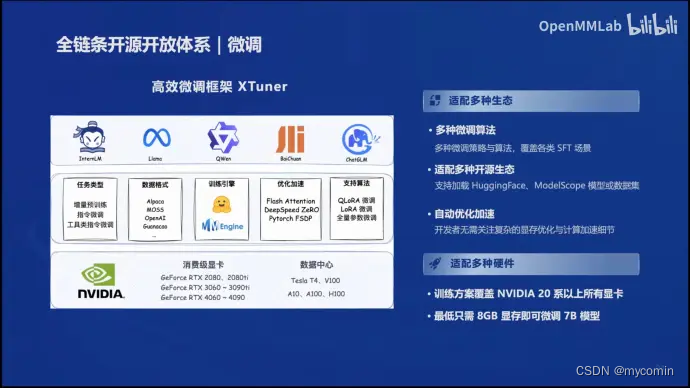
高效微调框架XTuner
部署平台 LMDeploy

智能体框架:Lagent

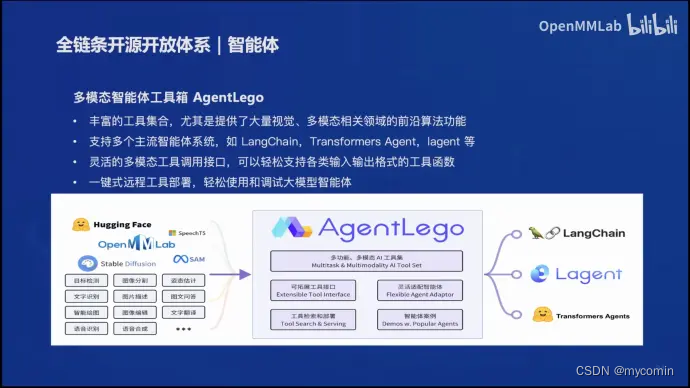
多模态智能体工具箱AgentLego
InternLM2大型语言模型技术报告概览
链接: arxiv.org/pdf/2403.17297.pdf
摘要
随着ChatGPT和GPT-4等大型语言模型(LLMs)的演进,对通用人工智能(AGI)的到来展开了热烈讨论。然而,在开源领域复制这些进步面临挑战。本报告介绍了InternLM2,这是一款开源LLM,通过创新的预训练和优化技术,在六个维度和三十个基准测试中超越了其前辈,尤其在长上下文建模和开放式主观评估方面表现出色。InternLM2在超过2万亿字节的高质量预训练语料上进行了训练,涵盖18亿、70亿和200亿参数规模的模型,适应多种应用场景。为了更好地支持长上下文,模型采用了GQA方法降低推理成本,并针对最长32K的上下文进行了额外训练。除模型本身开源外,还提供了训练过程各阶段的检查点,便于未来研究。
技术细节
数据处理与预训练
数据来源:覆盖文本、代码、长文本数据类型,以及对齐数据,确保多样性。
代码数据:基于学习分类器的质量分级,高质量数据多次训练,中等质量一次,低质量数据剔除。对于资源稀缺的编程语言数据则保留不统计在内。
数据去重:考虑到代码的特殊性,如Python中缩进的不同表示,采用了考虑上下文完整性的文件级去重策略,尽管细粒度去重技术已有所进展。
质量过滤:采用混合过滤流程,包含规则和模型基础评分器。发现代码风格不是可靠的指标,因此依赖模型评分,通过约5万条标注样本训练多个基线模型,但注意到不同语言下评分与人工判断的相关性差异。
训练框架与技术创新
长上下文处理:引入GQA方法减少长上下文模型的推理成本,有效应对大规模数据处理。
条件在线RLHF:为解决强化学习过程中偏好冲突问题,提出条件在线RLHF算法,实现偏好和谐。
开源与贡献
模型开源:不仅模型代码开源,还包括详细的训练流程说明,如训练框架、数据准备、预训练策略等,为构建更高效的大模型提供宝贵经验。
数据格式化:详细介绍了以网页数据为例的数据处理流程,从原始数据抽取到最终格式化存储的每一步骤。
重复数据处理:利用局部敏感哈希(LSH)与MinHash方法进行文本去重,确保数据集的新颖性和质量。
结论
InternLM2的发布,不仅代表了开源社区在大型语言模型领域的重大突破,也为研究者和开发者提供了一个高性能、多用途的工具箱,推动了自然语言处理技术的发展。通过对高质量多样数据的精心准备、创新的预训练策略及有效的数据管理,InternLM2在多个维度展现了卓越性能,为迈向通用人工智能的道路提供了坚实的基础。

















 2252
2252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









