






初阶
关键在于处理如何处理链的信息。
前置知识
首先我们定义轻重链:
孩子结点的子树最大的作为重儿子,每次优先跑重儿子,可以得到一条重链。
重链的
d
f
s
dfs
dfs序显然是连续的,轻链就是自己。
【可以证明从根结点到叶子节点的路径上,轻重链的个数不超过
l
o
g
n
logn
logn,但我不会】
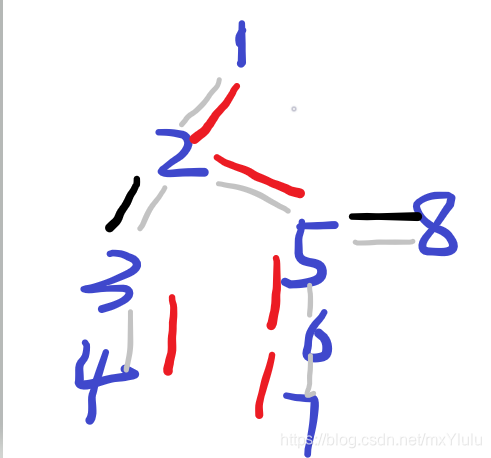
灰色是原来边,红色是重链,黑色是轻链,轻链我个人觉得需要记录的只有叶子节点。因为很明显可以发现
2
→
3
2\to 3
2→3这条轻链的两个点都在别的链上可以记录,所以接下来我们可以认为轻链只有自己,
2
→
3
2\to 3
2→3这种可以当做没有。
这就代表我们可以通过这个做文章了。
对于两个结点,我们要对其树上路径进行处理,就是把这些路径分成多个链进行处理,因为链都是连续的,所以可以直接当线性结构做(线段树等)
具体操作
具体怎么实现分成多个链呢,我们从头开始处理:
1、首先得到重儿子
void dfs1(int u,int pre){
dep[u]=dep[pre]+1;
sz[u]=1,fa[u]=pre;
int s=0;
for(auto v:G[u]){
if(v==pre)continue;
dfs1(v,u);
sz[u]+=sz[v];
if(sz[v]>s)son[u]=v,s=sz[v];
}
}
2、通过重儿子跑出重链,对于每个点存下自己所在链的链头 t o p [ i ] top[i] top[i],轻链就是自己
void dfs2(int u,int tr_top){
dfn[u]=++cnt;
top[u]=tr_top;
if(son[u])dfs2(son[u],tr_top);
for(auto v:G[u]){
if(v==fa[u]||v==son[u])continue;
dfs2(v,v);
}
}
3、对于两个结点,分别往上跳,每次跳的时候先跳链头深度低的,最后在一条链的时候结束。先跳低的能保证不会直接跳出 l c a lca lca的位置,因为只有重链会跳出去,而一个是重链,另一个必然是轻链(或者链头深度低的重链),所以会先跳另一个,直到跳到这个重链上
int query(int l,int r,int id){
int ans=0;
while(top[l]!=top[r]){
if(dep[top[l]]<dep[top[r]])swap(l,r);
ans+=query(dfn[top[l]],dfn[l],now);
l=fa[top[l]];
}
if(dfn[l]<=dfn[r])ans+=query(dfn[l],dfn[r],now);
else ans+=query(dfn[l],dfn[r],now);
return ans;
}
这里的
q
u
e
r
y
query
query就是具体操作了,query换成更新操作也是一样的,因为这段操作实际上只是将路径拆分成链而已。
例题
牛客练习赛 F F F: 题解

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









