



一 前言
前面聊起huggingface上模型的应用,测试了聊天机器人、语言翻译器、自然语音识别等多个模型,这篇聊下,其他常见的模型。
二 实践
2.1 文本转语音
文本转语音,其实还挺难的,因为同样的文本,有非常多的实现方式,可能有不同的音色、语调等。 文本转语音应用场景还是很多的,比如我们有不少电子书,如果能够通过AI的方式进行朗读,这样可以减少屏幕对眼镜的伤害,还可以将我们双手和眼睛解放出来,干些别的事情。
虽然文本转语音难,好在huggingface上有很多免费的模型。
from transformers.utils import logging
logging.set_verbosity_error()
from transformers import pipeline
#创建一个文本转语音的管道,指定使用本地路径 ./models/kakao-enterprise/vits-ljs 中的 VITS 模型
#这个模型是由 Kakao Enterprise 训练的,基于 LJSpeech 数据集
narrator = pipeline("text-to-speech",
model="./models/kakao-enterprise/vits-ljs")
text = """
Hello,everyone . I'am mingyi.
"""
narrated_text = narrator(text)
from IPython.display import Audio as IPythonAudio
#narrated_text["audio"][0]:这应该是音频数据本身(通常是一个数值数组,表示音频的波形数据),#从narrated_text字典的"audio"键对应的列表中取第一个元素。
IPythonAudio(narrated_text["audio"][0],
rate=narrated_text["sampling_rate"])2.2 物品检测模型
物品检测简单来说,就是让计算机理解图片中有什么。 应用场景,比如给盲人发一张照片,AI如果能检测出照片中的物体,并读出来,这样就解决了盲人无法识别照片的问题;再比如,用这种物品检测可以检测火灾,在无人值守的仓库,如果失火了,损失会非常严重,如果能在火灾开始的时候,及时检测到火灾的情况,可以极大地减少损失。 可以利用物品检测技术,对仓库的监控视频,做抽样分析,发现有火的照片,及时告警。
物品检测 开发代码需要安装如下库:
!pip install transformers
!pip install gradio
!pip install timm
!pip install inflect
!pip install phonemizer其中库:timm 全称是 PyTorch Image Models,是一个专注于计算机视觉的模型库,包含大量预训练的图像分类、检测、分割模型(如 ResNet、EfficientNet、Swin Transformer 等)。在物品检测中,它可以提供高效的主干网络(Backbone)或完整检测模型,加速模型训练和推理。
inflect一个处理英语语法变化的库,主要用于词形转换(如复数形式、动词时态、序数词等)。在物品检测中,它通常用于结果后处理,比如将检测到的 "car" 根据数量自动转换为 "cars",让输出更符合自然语言习惯。
phonemizer用于将文本转换为语音音素(发音符号)的工具。它在物品检测中并不属于直接相关的核心库,可能用于扩展功能,比如将检测结果(如 "这是一个苹果")转换为语音发音,实现语音播报检测结果的功能。
总结,前面三个库用于检测核心功能实现,后面两个库为检测的输出需要; 代码:
from helper import load_image_from_url, render_results_in_image
from transformers import pipeline
od_pipe = pipeline("object-detection", "./models/facebook/detr-resnet-50")
from PIL import Image
raw_image = Image.open('huggingface_friends.jpg')
raw_image.resize((569, 491))
pipeline_output = od_pipe(raw_image)
processed_image = render_results_in_image(
raw_image,
pipeline_output)其中引入的两个函数内容:
def render_results_in_image(in_pil_img, in_results):
# 创建一个16x10英寸的绘图窗口
plt.figure(figsize=(16, 10))
# 在窗口中显示原始图像
plt.imshow(in_pil_img)
# 获取当前图像的坐标轴对象(用于后续绘制边界框和文本)
ax = plt.gca()
for prediction in in_results:
# 左上角坐标
x, y = prediction['box']['xmin'], prediction['box']['ymin']
# 宽度(xmax - xmin)
w = prediction['box']['xmax'] - prediction['box']['xmin']
# 高度(ymax - ymin)
h = prediction['box']['ymax'] - prediction['box']['ymin']
# 不填充矩形内部
# 边框颜色为绿色
# 边框线宽为2
ax.add_patch(plt.Rectangle((x, y),
w,
h,
fill=False,
color="green",
linewidth=2))
#在边界框左上角(x, y)位置添加文本,内容为 “标签:置信度 %”(如 “cat: 98.5%”)
ax.text(
x,
y,
f"{prediction['label']}: {round(prediction['score']*100, 1)}%",
color='red'
)
# 隐藏坐标轴,只显示图像内容
plt.axis("off")
# Save the modified image to a BytesIO object
## 创建内存缓冲区(类似临时文件)
img_buf = io.BytesIO()
# 去除图像周围多余空白
plt.savefig(img_buf, format='png',
bbox_inches='tight',
pad_inches=0) # 边缘填充为0
img_buf.seek(0) # 将缓冲区指针移到开头,方便后续读取
# 从缓冲区读取图像,转为PIL Image对象
modified_image = Image.open(img_buf)
# Close the plot to prevent it from being displayed
plt.close()
return modified_image
#从网远程加载图片
def load_image_from_url(url):
return Image.open(requests.get(url, stream=True).raw)效果如下:
用Gradio库简单做个界面:
import os
import gradio as gr
def get_pipeline_prediction(pil_image):
pipeline_output = od_pipe(pil_image)
processed_image = render_results_in_image(pil_image,
pipeline_output)
return processed_image
demo = gr.Interface(
fn=get_pipeline_prediction,
inputs=gr.Image(label="Input image",
type="pil"),
outputs=gr.Image(label="Output image with predicted instances",
type="pil")
)
demo.launch(share=True, server_port=int(9000))
demo.close()测试个图片,不过没有把更细节的鱼没检测到,测试结果如下: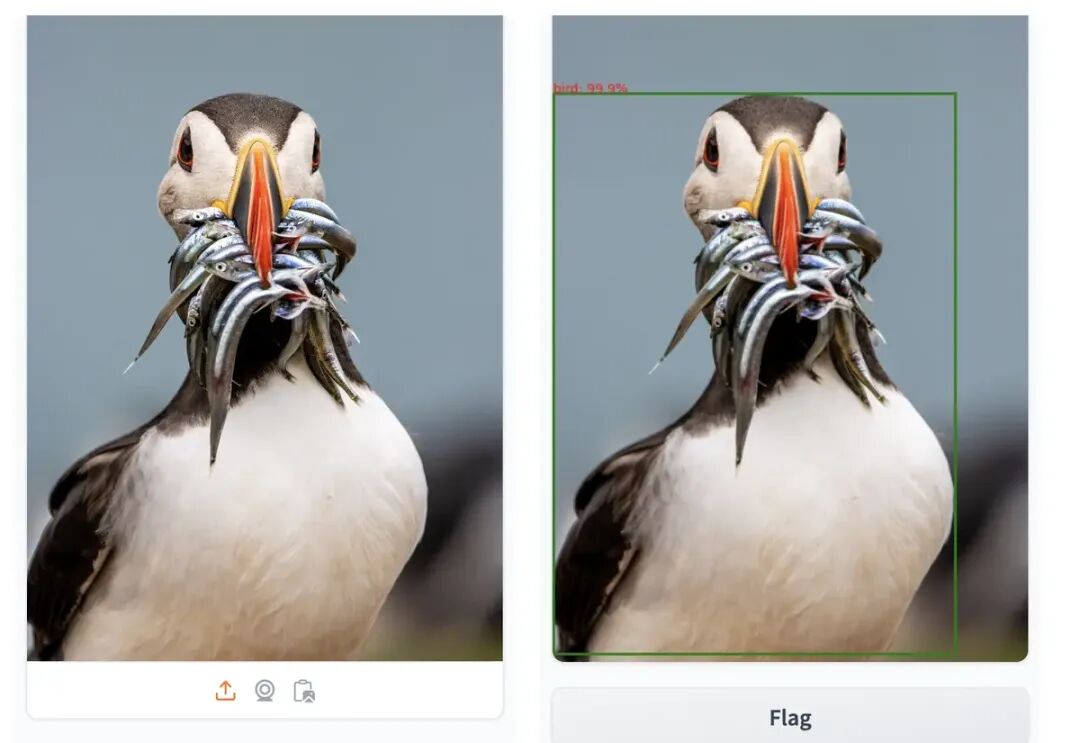
下面可以结合我们上面的文字转语音功能,将识别出来的图片内容以语音方式播放出来。
识别出来的其实是json内容,打印下内容: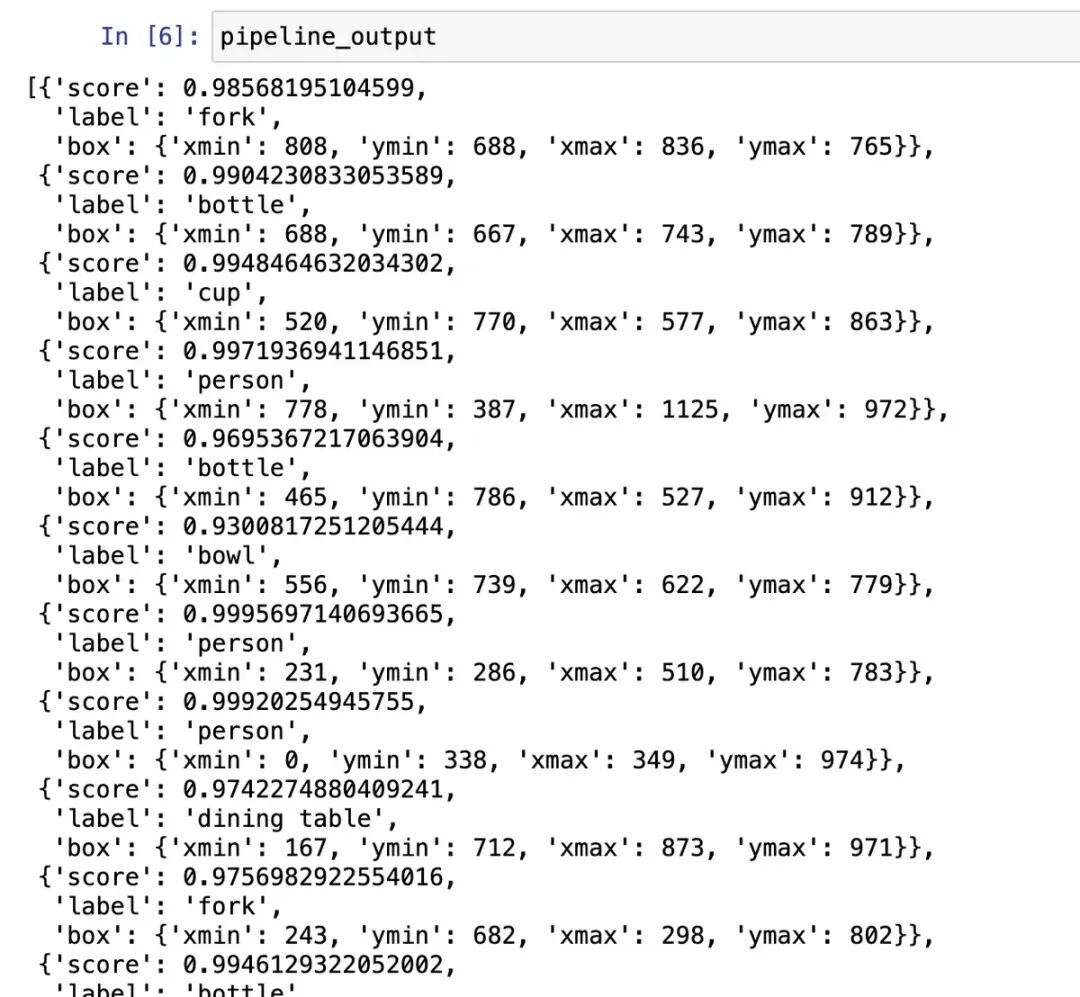
结果是json内容,我们需要将图片的内容总结下,总结成几句话,然后通过语音输出,先写个总结函数:
def summarize_predictions_natural_language(predictions):
summary = {}
#创建inflect库的引擎对象,用于数字转英文单词(如1→"one",2→"two")
p = inflect.engine()
for prediction in predictions:
label = prediction['label']
if label in summary:
summary[label] += 1
else:
summary[label] = 1
result_string = "In this image, there are "
for i, (label, count) in enumerate(summary.items()):
count_string = p.number_to_words(count)
result_string += f"{count_string} {label}"
if count > 1:
result_string += "s"
result_string += " "
if i == len(summary) - 2:
result_string += "and "
# Remove the trailing comma and space
result_string = result_string.rstrip(', ') + "."
return result_string上面的图片识别的结果就是:'In this image, there are two forks three bottles two cups four persons one bowl and one dining table.' 下面就简单了,加载文本转语音模型,然后将文本转语音输出:
tts_pipe = pipeline("text-to-speech",
model="./models/kakao-enterprise/vits-ljs")
#调用创建好的 TTS 流水线,将输入文本(text变量,需提前定义,如text = "Hello, world")转换为语音数据。
narrated_text = tts_pipe(text)
from IPython.display import Audio as IPythonAudio
#narrated_text["audio"]:语音的原始音频数据(通常是一个二维数组,包含音频波形)。
IPythonAudio(narrated_text["audio"][0],
rate=narrated_text["sampling_rate"])结果显示:
2.3 图片检索
上面的模型大多是单一的,比如图片识别,就是识别图片中的内容。图片检索模型比较有意思,是多模态的。比如我们输入一段文字,和一张图片,然后检测文字和图片是否匹配?这里,文字和图片就是两种模态。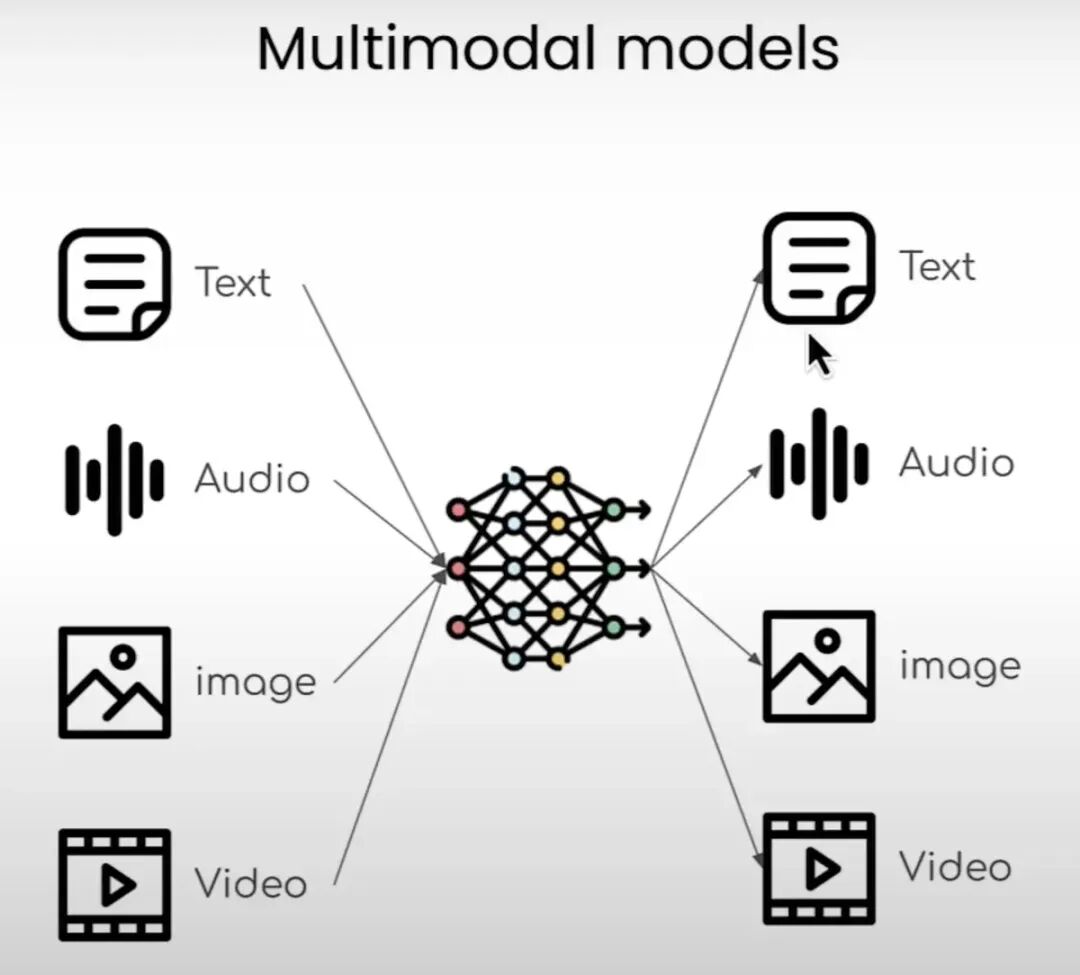 常见的多模态任务:
常见的多模态任务:
文本和图片是否匹配
给图片起个标题
视觉问答
零样本图片分类(比如自动对照片分类)
该架构通过双编码器(图像编码器 + 文本编码器),先将图像和文本分别转换为特征,再通过交叉注意力让文本 “参考” 图像特征,最终判断文本是否能准确描述图像内容(即图文是否匹配)。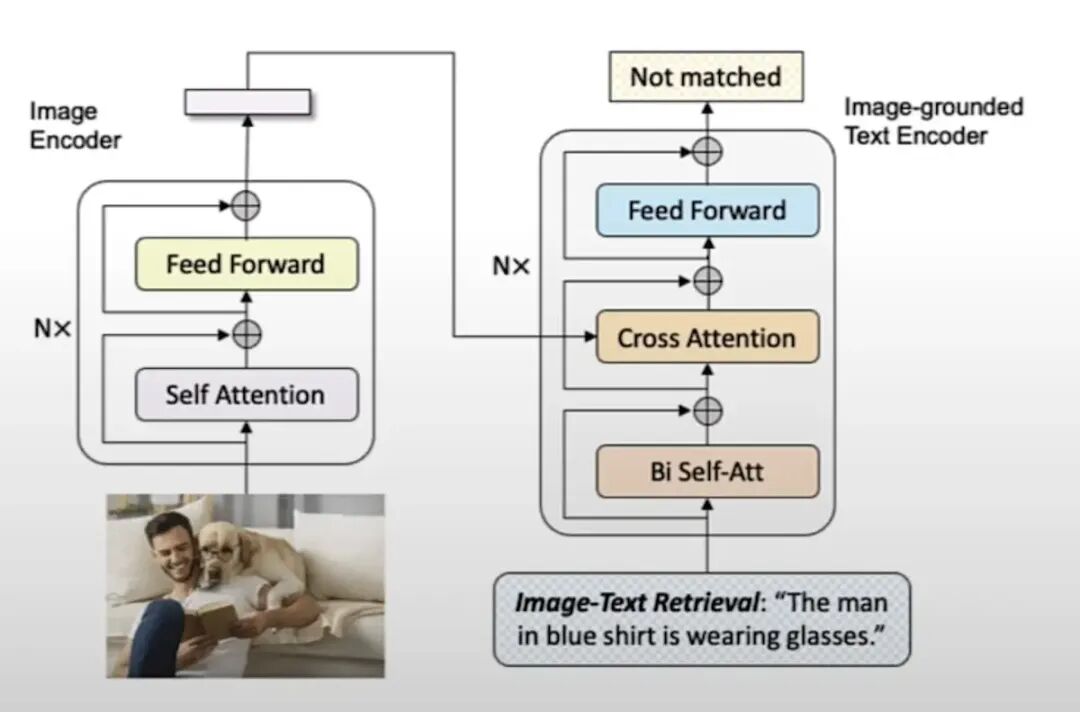 说明:
说明:
左边是图像编码器,捕捉图像的视觉信息,重复N多次Transformer Encoder 层(自注意力机制和前馈网络),最终将输入的图像编码为特征向量,传递给右侧的文本编码器。
右侧的基于图像的文本编码器,输入待匹配的文本,以及左边图像编码器输出的图像特征,判断文本和图像是否匹配。
上代码:
from transformers.utils import logging
logging.set_verbosity_error()
from transformers import BlipForImageTextRetrieval
#BLIP(Bootstrapping Language-Image Pre-training)模型进行图像 - 文本匹配(Image-Text Matching, ITM)
model = BlipForImageTextRetrieval.from_pretrained(
"./models/Salesforce/blip-itm-base-coco")
#AutoProcessor 是自动匹配模型的预处理工具,
#负责对输入的图像和文本进行标准化(如图像 resize、文本 tokenize 等),使其符合模型输入要求。
#处理器与模型来自同一预训练权重,确保预处理方式与模型训练时一致
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained(
"./models/Salesforce/blip-itm-base-coco")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
from PIL import Image
import requests
# 从 URL 下载图像并转换为 RGB 格式(模型要求的输入格式)
raw_image = Image.open(
requests.get(img_url, stream=True).raw).convert('RGB')
# 待匹配的文本描述
text = "an image of a woman and a dog on the beach"
# 用处理器对图像和文本进行预处理,转换为模型可接受的张量(return_tensors="pt" 表示返回 PyTorch 张量)
inputs = processor(images=raw_image,
text=text,
return_tensors="pt")
# 模型推理
# 获取图像-文本匹配的原始分数
itm_scores = model(**inputs)[0]
import torch
# 对原始分数应用 softmax,转换为概率(dim=1 表示在类别维度计算)
itm_score = torch.nn.functional.softmax(
itm_scores,dim=1)
print(f"""\
The image and text are matched \
with a probability of {itm_score[0][1]:.4f}""")输出结果:The image and text are matched with a probability of 0.9884
2.4 通过AI给图片加说明
简单来说,给模型一张图片,加些开头文字,模型给出完整的对图片的描述,比较简单,直接上代码:
from transformers.utils import logging
logging.set_verbosity_error()
import warnings
warnings.filterwarnings("ignore", message="Using the model-agnostic default `max_length`")
from transformers import BlipForConditionalGeneration
model = BlipForConditionalGeneration.from_pretrained(
"./models/Salesforce/blip-image-captioning-base")
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained(
"./models/Salesforce/blip-image-captioning-base")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
from PIL import Image
raw_image = Image.open(
requests.get(img_url, stream=True).raw).convert('RGB')
text = "a photograph of"
# 用处理器对图像和文本进行预处理,转换为模型可接受的张量(return_tensors="pt" 表示返回 PyTorch 张量)
inputs = processor(raw_image, text, return_tensors="pt")
out = model.generate(**inputs)
# 解码生成的结果(去除特殊标记,得到自然语言文本)
print(processor.decode(out[0], skip_special_tokens=True))输出:a photograph of a woman and her dog on the beach 当然我们也可以无开头文字输出,将后面的代码改下:
inputs = processor(raw_image,return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))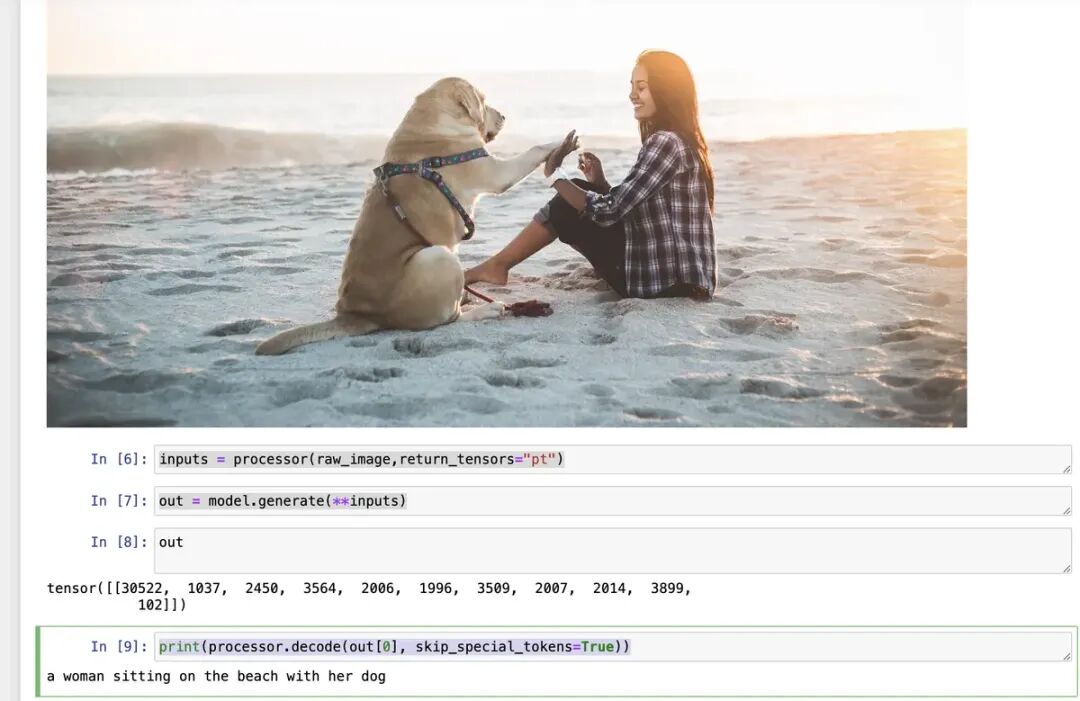
三 总结与展望
通过前文的实践,我们基于 Hugging Face 生态,逐步探索了文本转语音、物品检测、图文检索、图像描述生成这四类实用的 AI 模型应用 —— 从将文字转化为自然语音以解放双眼,到让计算机 “看见” 并标注图像中的物体,再到实现跨模态的图文匹配与自动 caption 生成,每一项功能都清晰展现了预训练模型在实际场景中的落地价值。
这些实践并非孤立存在:物品检测的结果可通过文本转语音实现 “可视化 + 语音播报” 的双重输出,图像描述生成的文本又能作为图文检索的输入依据,不同模型的组合搭配,正在构建出更立体、更智能的应用闭环。例如,在无障碍辅助场景中,盲人用户上传一张照片后,系统可先通过物品检测识别物体、用自然语言总结结果,再通过文本转语音播报内容,真正打通 “看见 - 理解 - 传递” 的全流程。
Hugging Face 生态的魅力,在于其降低了 AI 技术的使用门槛 —— 无论是本地加载预训练模型,还是用 Gradio 快速搭建交互界面,开发者无需从零训练模型,即可聚焦于场景创新。未来,我们还可进一步探索模型的优化方向:比如为物品检测模型补充小物体识别能力、为文本转语音模型切换更多音色,或是将多模态能力整合进更复杂的系统(如智能监控、自动图文编辑工具)。 AI 技术的价值,终究要回归到对人的服务中。而这些轻量化、易落地的模型应用,正是让 AI 从 “实验室” 走向 “日常生活” 的重要桥梁。


















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









