



一 前言介绍
Hugging Face 是一个以自然语言处理(NLP)和机器学习为核心的开源社区与技术平台,被称为 “机器学习界的 GitHub”,主要提供以下服务和功能:
模型仓库
包含数万种预训练模型,覆盖文本、图像、音频等多模态任务,支持主流框架(PyTorch、TensorFlow 等)。开发者可直接下载使用或微调模型(如 BERT、GPT、Stable Diffusion 等)。
1.数据集平台
提供大量公开数据集,涵盖翻译、分类、生成等任务,支持一键加载到模型训练流程中,降低数据准备门槛。
2.开源工具库
开发了著名的 transformers 库,简化了预训练模型的调用和微调;还有 datasets(数据处理)、accelerate(分布式训练)等工具,大幅降低机器学习应用的开发难度。
利用Hugging Face开发的transformers库,结合上面众多的预训练好的众多模型,可以让我们轻松搭建AI应用,下面是实践。
二 实践
本次试验过程发现, transformers加载模型的时候,需要依赖torch库2.6版本。
ValueError: Due to a serious vulnerability issue in `torch.load`, even with `weights_only=True`,
we now require users to upgrade torch to at least v2.6 in order to use the function.
This version restriction does not apply when loading files with safetensors.可气的是,我机器是macbook,intel芯片版本,最高只支持torch版本到2.2.2.
❯ pip install --trusted-host download.pytorch.org torch==2.3.0
--index-url https://download.pytorch.org/whl/cpu
Looking in indexes: https://download.pytorch.org/whl/cpu
ERROR: Could not find a version that satisfies the requirement torch==2.3.0 (from versions: 2.0.0, 2.0.1, 2.1.0, 2.1.1, 2.1.2, 2.2.0, 2.2.1, 2.2.2)没办法,好在找了一个jupyter环境来运行简单的测试,下面开始。
2.1 模型选择
hugging face 上模型很多,我们如何选择那,首先可以通过Task,选择不同的种类的AI模型,如下: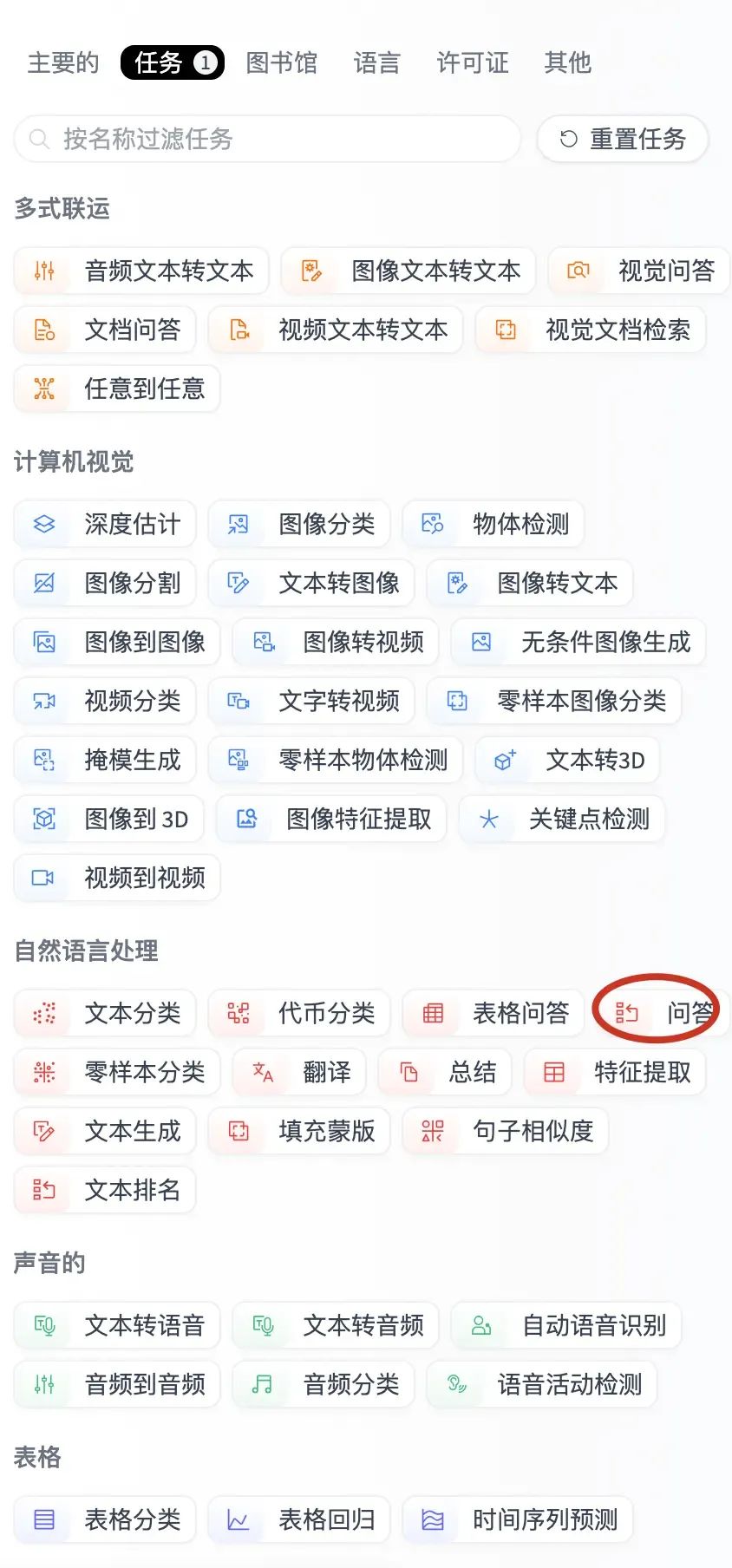 比如点选“问答”后,右边自动过滤出问答AI模型,然后我们可以根据下载量和最多赞排序,然后选择合适的模型。
比如点选“问答”后,右边自动过滤出问答AI模型,然后我们可以根据下载量和最多赞排序,然后选择合适的模型。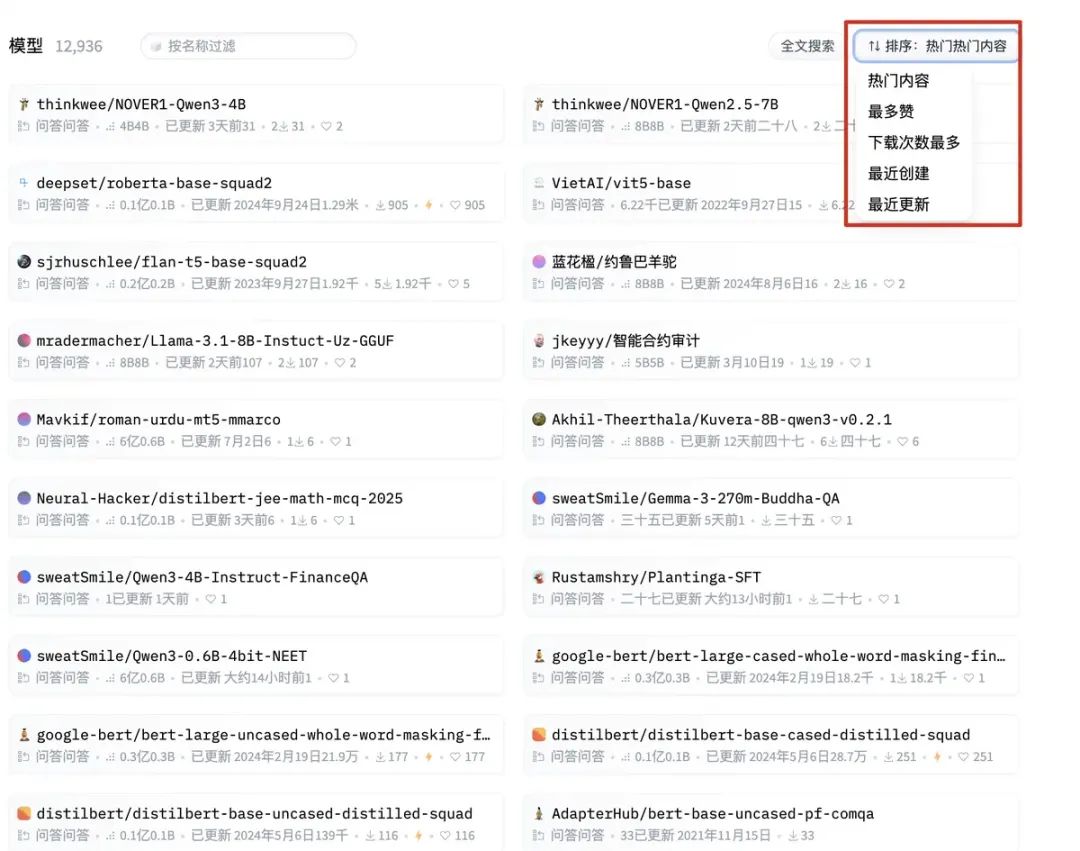
需要根据硬件选择,简单评估,来说模型运行需要内存为模型文件的1.2倍左右。
2.2 自然语言处理-构建聊天机器人
准备阶段,默认需要安装好:pip install transformers 这个开源库。
transformers 是 Hugging Face 开发的一个非常流行的 Python 自然语言处理库,主要作用是提供各种预训练的 Transformer 模型(如 BERT、GPT、T5 等)及其相关工具,帮助开发者快速实现自然语言处理任务。
提供丰富的预训练模型: 包含数百种预训练模型,支持多语言处理,涵盖文本分类、命名实体识别、机器翻译、问答系统、文本生成等多种任务。简化模型使用流程: 封装了复杂的模型构建和训练细节,通过简单的 API 即可加载预训练模型并进行推理,无需从零开始构建模型。
支持模型微调:可以基于预训练模型,使用自定义数据集进行微调,快速适配特定任务需求。
from transformers import pipeline
from transformers import logging
# 设置日志输出级别为错误,只有错误才输出 减少日志量
logging.set_verbosity_error()
chatbot = pipeline(task="conversational",
model="facebook/blenderbot-400M-distill")
#在hugging face上找到合适的模型,用pipeline直接加载模型
# 这个中文机器人模型还是大,经常失败
#chatbot = pipeline("question-answering", model="FlagAlpha/Llama2-Chinese-7b-Chat")
user_message="""I plan to visit Shanghai recently. How's the weather there lately? And what are the interesting places to visit and delicious foods to try? """
conversation = Conversation(user_message)
conversation = chatbot(conversation)
print(conversation)
conversation.add_message(
{"role": "user",
"content": """What delicious food is there? """
})
print(chatbot(conversation))运行结果:
Conversation id: 52fef548-3b79-4dd5-be11-68958b246d72
user: I plan to visit Shanghai recently. How's the weather there lately? And what are the interesting places to visit and delicious foods to try?
assistant: It is very hot and humid. I would love to try some of the food there.代码解释:
1. conversation = Conversation(user_message)
作用:创建一个对话对象,封装用户输入的消息,用于跟踪对话状态。
细节:
Conversation 是 transformers 库专门设计的类,用于管理多轮对话的上下文(包括用户消息和模型回复)。
初始化时传入用户当前输入的消息(user_message),会将其存储为对话的起始内容。
此时的 conversation 对象中仅包含用户的提问,还没有模型的回复。
2. conversation = chatbot(conversation)
作用:将对话对象传入对话管道(chatbot),让模型生成回复,并更新对话状态。
细节:
chatbot 是通过 pipeline("conversational", model=...) 创建的对话管道,内部封装了模型调用逻辑。
当把 conversation 对象传入 chatbot 时,管道会:
解析对话历史(首次调用时只有用户的初始消息);
调用模型生成针对当前对话的回复;
自动将生成的回复添加到 conversation 对象中,更新对话状态。
赋值操作 conversation = ... 是为了接收更新后的对话对象(包含了模型回复)。
3. conversation.add_message(...)
conversation 是之前创建的对话对象(transformers.Conversation 类的实例)。
add_message() 是该类的方法,用于向对话历史中追加新消息(可以是用户输入或模型回复),确保后续对话能基于完整上下文生成回复。
消息格式:{"role": "user", "content": "..."}
这是一个遵循对话角色规范的字典,包含两个关键键值对:
role: "user":表示这条消息的发送者是 “用户”(提问方)。
(对应的,模型回复的角色通常是 "assistant")
content: "What delicious food is there? ":表示消息的具体内容(这里是用户询问 “有什么美食?”)。
作用
向对话历史中手动添加用户的新提问,替代了直接创建新 Conversation 对象的方式。这样做的好处是:
保留之前的对话上下文(比如用户之前问过 “推荐一个旅游城市”,现在接着问当地美食,模型能关联起来)。
配合后续的 chatbot(conversation) 调用,模型会基于包括这条新消息在内的完整历史生成回复。输出内容: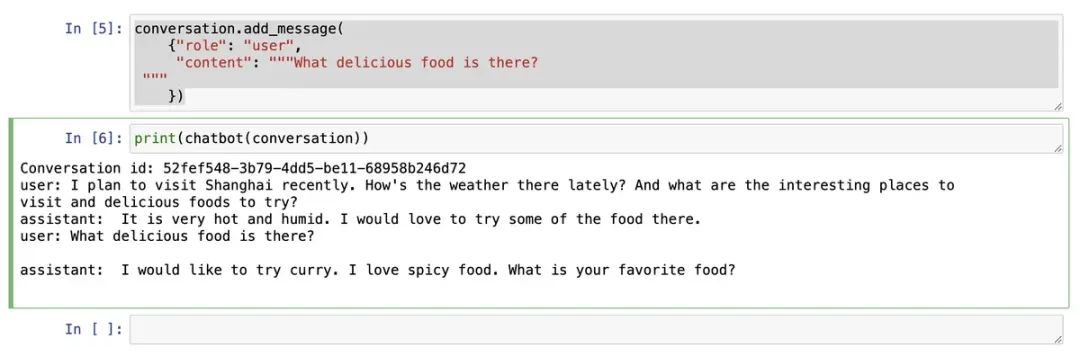
2.3 自然语言处理-构建AI翻译器
自然语言翻译,应用非常广泛,现在AI更强大了,用AI做语言翻译,也变的非常简单。 利用Hugging face上的模型可以轻松创建一个AI翻译应用。
需要安装库:
pip install transformers
pip install torch代码如下:
from transformers import pipeline
# 加载翻译模型
translator = pipeline(
"translation",
model="Helsinki-NLP/opus-mt-zh-en")
chinese_texts = [
"我爱自然语言处理。",
"今天天气很好,适合去公园散步。",
"Hugging Face的transformers库非常实用。",
"人工智能正在改变我们的生活。"
]
results = translator(chinese_texts, max_length=100)
for chinese, result in zip(chinese_texts, results):
print(f"中文: {chinese}")
print(f"英文: {result['translation_text']}\n")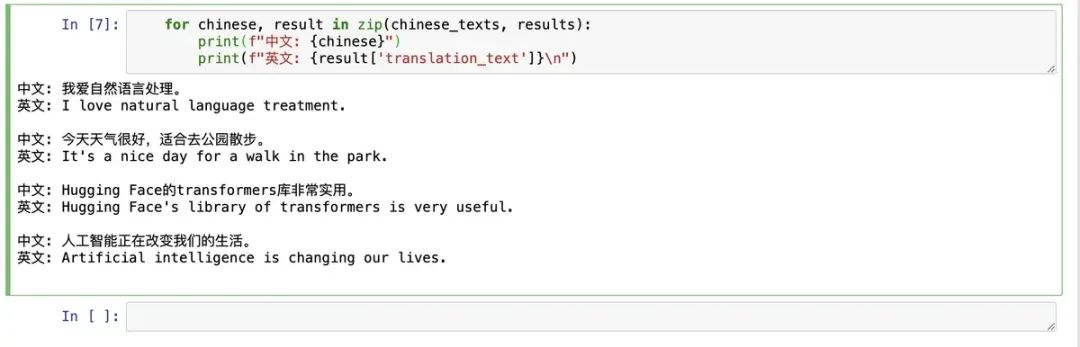
2.4 自动语音识别
语音识别,现在应用非常广泛,比如我们开会的时候,需要将语音内容自动转成文字,然后再进一步存档,总结。以前需要人工做会议纪要,现在可以简单的通过AI进行语音识别,并通过AI做会议内容总结。
需要安装库:
pip install transformers
pip install -U datasets
pip install soundfile
pip install librosa
pip install gradio说明:
datasets库:用于加载和处理各种机器学习数据集(尤其是 NLP 领域),支持自动下载、格式转换、数据清洗和预处理。
soundfile库:用于读取和写入音频文件(支持 WAV、FLAC、OGG 等格式),提供简单的 API 处理音频数据。
librosa库:专业的音频分析库,用于提取音频特征(如梅尔频谱、音高、节奏等),支持音频可视化和预处理。
gradio库:快速构建机器学习模型的交互式 Web 界面,无需前端知识,几行代码即可生成可交互的演示页面。
代码:
from transformers.utils import logging
logging.set_verbosity_error()
from datasets import load_dataset
#加载一个专门用于语音识别的经典公开数据集(LibriSpeech ASR),
#该数据集包含大量带文本标注的英语语音片段,来自公共领域的有声书籍朗读录音。
#split="train.clean.100",指定加载数据集的子集,最清晰的100小时子集。
#streaming =True 采用流式加载,减少内存占用,按需加载
#rust_remote_code=True 允许执行数据集附带的远程代码
dataset = load_dataset("librispeech_asr",
split="train.clean.100",
streaming=True,
trust_remote_code=True)
examples = dataset.take(3)
list(examples)加载后,可以看到数据集中不光有录音,还有标签,以及应该识别到的内容: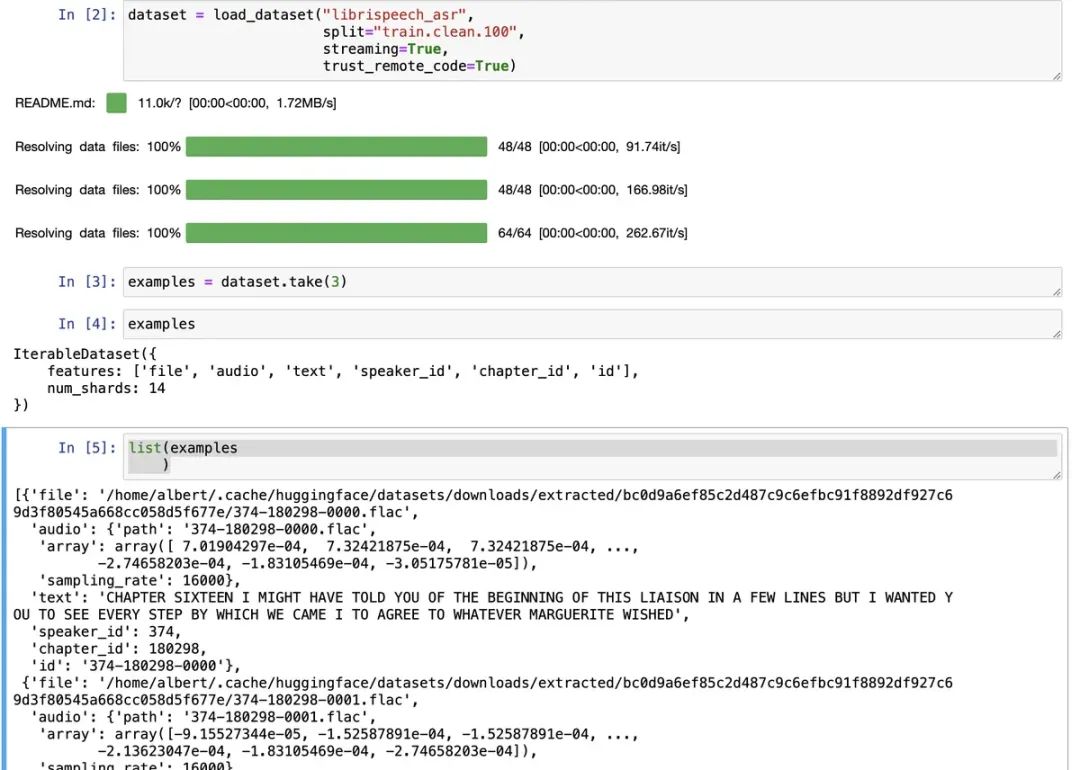
语音数据集的每条数据结构如下:
{
'file': '/home/albert/.cache/huggingface/datasets/downloads/extracted/bc0d9a6ef85c2d487c9c6efbc91f8892df927c69d3f80545a668cc058d5f677e/374-180298-0000.flac',
'audio': {
'path': '374-180298-0000.flac',
'array': array([7.01904297e-04, 7.32421875e-04, 7.32421875e-04, ..., -2.74658203e-04, -1.83105469e-04, -3.05175781e-05]),
'sampling_rate': 16000
},
'text': 'CHAPTER SIXTEEN I MIGHT HAVE TOLD YOU OF THE BEGINNING OF THIS LIAISON IN A FEW LINES BUT I WANTED YOU TO SEE EVERY STEP BY WHICH WE CAME I TO AGREE TO WHATEVER MARGUERITE WISHED',
'speaker_id': 374,
'chapter_id': 180298,
'id': '374-180298-0000'
}我们其实需要里面的audio中内容,先来放下这个录音,停下效果:
from IPython.display import Audio as IPythonAudio
IPythonAudio(example["audio"]["array"],
rate=example["audio"]["sampling_rate"])解释:
example["audio"]["array"]:通常是一个音频波形数据的数组(numpy 数组或 Python 列表),
存储了语音信号的振幅信息(即 “原始音频数据”)。
rate=...:指定音频的采样率(见下文详细解释)。
这行代码会创建一个音频播放器控件,在 IPython 环境中显示,点击即可播放array中的语音数据。这里面音频的采样率非常重要:
rate(采样率,单位:赫兹 Hz)是音频处理中的核心参数,定义为每秒对模拟语音信号的采样次数。
其作用包括:
决定音频的 “时间精度”例如: 16000 Hz(语音识别常用):每秒采样 16000 次,每次采样间隔约 0.0000625 秒。 44100 Hz(CD 音质):每秒采样 44100 次,精度更高。 采样率越高, 音质越好,但数据量也越大。
决定音频的可播放频率范围:
采样率必须至少是音频中最高频率的 2 倍才能准确还原信号。 人类语音的频率范围通常在 300Hz~3400Hz,因此 8000Hz 或 16000Hz 的采样率足以覆盖(16000Hz > 2×3400Hz)。
接着我们加载语音识别模型:
from transformers import pipeline
asr = pipeline(task="automatic-speech-recognition",
model="distil-whisper/distil-small.en")解释:
distil-whisper:是对 OpenAI 的 Whisper 模型进行蒸馏(Distillation)得到的轻量版模型,保留了大部分性能但体积更小、速度更快。
distil-small.en:表示 “小型”(small)的英语(.en)专用版本,适合英语语音识别场景,资源占用较低(相比原 Whisper 模型更易部署)
在使用模型之前,我们需要检查模型的默认采用率,采用率不同,会导致数据失真,无法准确识别, 检查方法:
asr.feature_extractor.sampling_rate
#输出
16000
example["audio"]["sampling_rate"]
#输出
16000可以看到录音的采用频率和模型默认的一样,可以直接使用。 通过下面的语句自动识别:
asr(example["audio"]["array"]) 和原文相比,语句加了标点符号,适配了合适的大小写,更易读了。
和原文相比,语句加了标点符号,适配了合适的大小写,更易读了。
除了处理数据集里面的数据,当然我们还可以录音,让模型识别:
import os
import gradio as gr
# 创建一个高级界面容器,用于组合多个组件
demo = gr.Blocks()
def transcribe_speech(filepath):
if filepath is None:
gr.Warning("No audio found, please retry.")
return ""
# 调用之前定义的asr语音识别管道
output = asr(filepath)
return output["text"]
# 界面1:麦克风录音识别
mic_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(sources="microphone", # 输入源为麦克风
type="filepath"), # 输出格式为音频文件路径(而非原始数据)
outputs=gr.Textbox(label="Transcription", # 文本框标签
lines=3), # 文本框显示行数
allow_flagging="never")
# 界面2:音频文件上传识别
file_transcribe = gr.Interface(
fn=transcribe_speech,
inputs=gr.Audio(sources="upload",
type="filepath"),
outputs=gr.Textbox(label="Transcription",
lines=3),
allow_flagging="never",
)
# 使用with语法向Blocks容器中添加内容
with demo:
gr.TabbedInterface(
[mic_transcribe,
file_transcribe],
["Transcribe Microphone",
"Transcribe Audio File"], # 放入两个界面
)
demo.launch(share=True, # 生成公共链接,允许其他人访问(有效期约72小时)
server_port=int(os.environ['PORT1']))# 从环境变量获取端口(常用于服务器部署)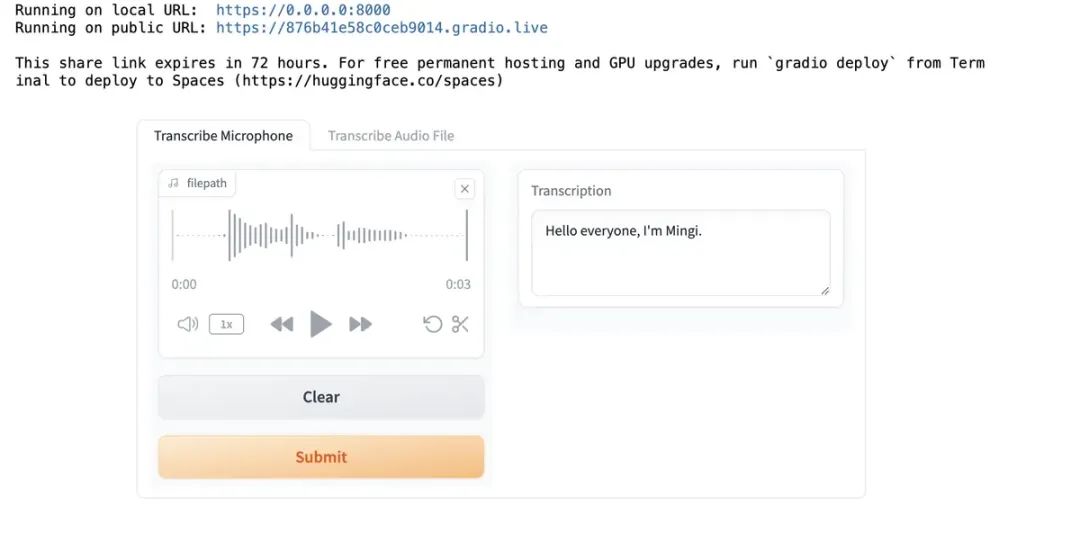
但是上面界面的录音,只能最长30s,这对我们的会议来说显然是不够的,但是仍然可以通过pipeline来实现语音识别。
让我们来测试个长的录音:
import soundfile as sf
import io
audio, sampling_rate = sf.read('narration_example.wav')
print(sampling_rate)
print(audio.shape)会发现打印结果如下,会发现采样频率和库的默认不一样,而且维度竟然是2维的,因为是立体双通道原因,可以变换成单通道,因为双通道除了精度高,对我们识别没什么帮助的。
 代码:
代码:
import numpy as np
import librosa
from IPython.display import Audio as IPythonAudio
#矩阵转置
audio_transposed = np.transpose(audio)
print(audio_transposed.shape)
#将多声道(如立体声,通常为左、右两个声道)的音频数据转换为单声道,合并所有声道的音频信息为一个声道。
audio_mono = librosa.to_mono(audio_transposed)
#播放下听听效果
IPythonAudio(audio_mono,
rate=sampling_rate)
#核心功能:改变音频的采样率(每秒采样次数),将原始音频的采样率转换为 16000Hz。
audio_16KHz = librosa.resample(audio_mono,
orig_sr=sampling_rate,
target_sr=16000)
asr(audio_16KHz)
asr(
audio_16KHz,
chunk_length_s=30, # 30 seconds
batch_size=4,
return_timestamps=True,
)["chunks"]返回结果:
核心代码是:
asr(
audio_16KHz,
chunk_length_s=30, # 30 seconds
batch_size=4,
return_timestamps=True,
)["chunks"]作用:
对预处理后的 16KHz 单声道音频(audio_16KHz)进行语音识别,并返回按时间分段的识别结果(包含每个片段的文本和对应时间戳)。
1. chunk_length_s=30 指定音频分块长度为 30 秒。对于长音频(超过模型单次处理上限),模型会自动按 30 秒为单位分割成多个片段(chunk),逐段处理后再拼接结果,
避免因音频过长导致内存不足或识别精度下降。
2. batch_size=4:
批处理大小为 4,即同时处理 4 个 30 秒的音频片段,加速长音频的识别效率(利用并行计算能力)。
3. return_timestamps=True:
启用时间戳功能,让模型返回每个识别片段在原始音频中的起始和结束时间(单位:秒),方便定位文本对应的语音位置。
4. 模型输出是一个字典,其中 ["chunks"] 键对应的值是一个列表,包含所有分块的识别结果,每个元素是一个带时间戳的片段信息超过30s的在线录音,可以通过上面切分文件的思路来进行识别,如下:
def transcribe_long_form(filepath):
if filepath is None:
gr.Warning("No audio found, please retry.")
return ""
output = asr(
filepath,
max_new_tokens=256,
chunk_length_s=30,
batch_size=8,
)
return output["text"]其他的不用变,即可以处理超过30s的录音识别了,其中:
max_new_tokens=256 是控制语音识别模型生成文本长度的关键参数,这里的 256 表示模型针对单次语音识别结果时,最多生成 256 个 token(词元)。
即我们在30s内,支持多大识别的token为256个。总结
总的来说啊,Hugging Face这东西是真挺好用的。你看,不管管是想整个能聊天的机器人,还是做个翻译工具,甚至把语音转成文字,用它家的工具和模型,几行代码就能搞定,根本不用自己从头攒模型,省老事儿了。
当然了,用的时候也可能碰到些小麻烦,比如电脑配置不够啊,软件版本不兼容啥的,但好在办法总比困难多,换个环境试试,或者用个轻量点的模型,基本都能解决。
对咱们普通开发者来说,这就意味着不用死磕那些复杂的算法,也能快速搭出能用的AI小工具。以后这东西肯定会越来越厉害,能做的事儿也越来越多。不管是想试试手,还是真要做个实用的小应用,借着它入门肯定错不了,能少走不少弯路呢。
参考:https://learn.deeplearning.ai/courses/open-source-models-hugging-face/lesson/wcnno/automatic-speech-recognition

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









