







 超级会员免费看
超级会员免费看
 本文详细解读YOLOv1物体检测算法,包括原理、损失函数定义和训练技巧。每个7x7网格预测两个边界框,重点讨论了坐标表示优化和非极大值抑制策略,适用于大物体检测,但对于小物体和重叠物体表现有限。
本文详细解读YOLOv1物体检测算法,包括原理、损失函数定义和训练技巧。每个7x7网格预测两个边界框,重点讨论了坐标表示优化和非极大值抑制策略,适用于大物体检测,但对于小物体和重叠物体表现有限。
论文地址: https://arxiv.org/pdf/1506.02640.pdf

说明
- 这个系列会总结关于yolo的解读,为本人理解,还望交流指正。
V1版本:
- v1版本的结构为
img --》VGGNET–》4096-》7730
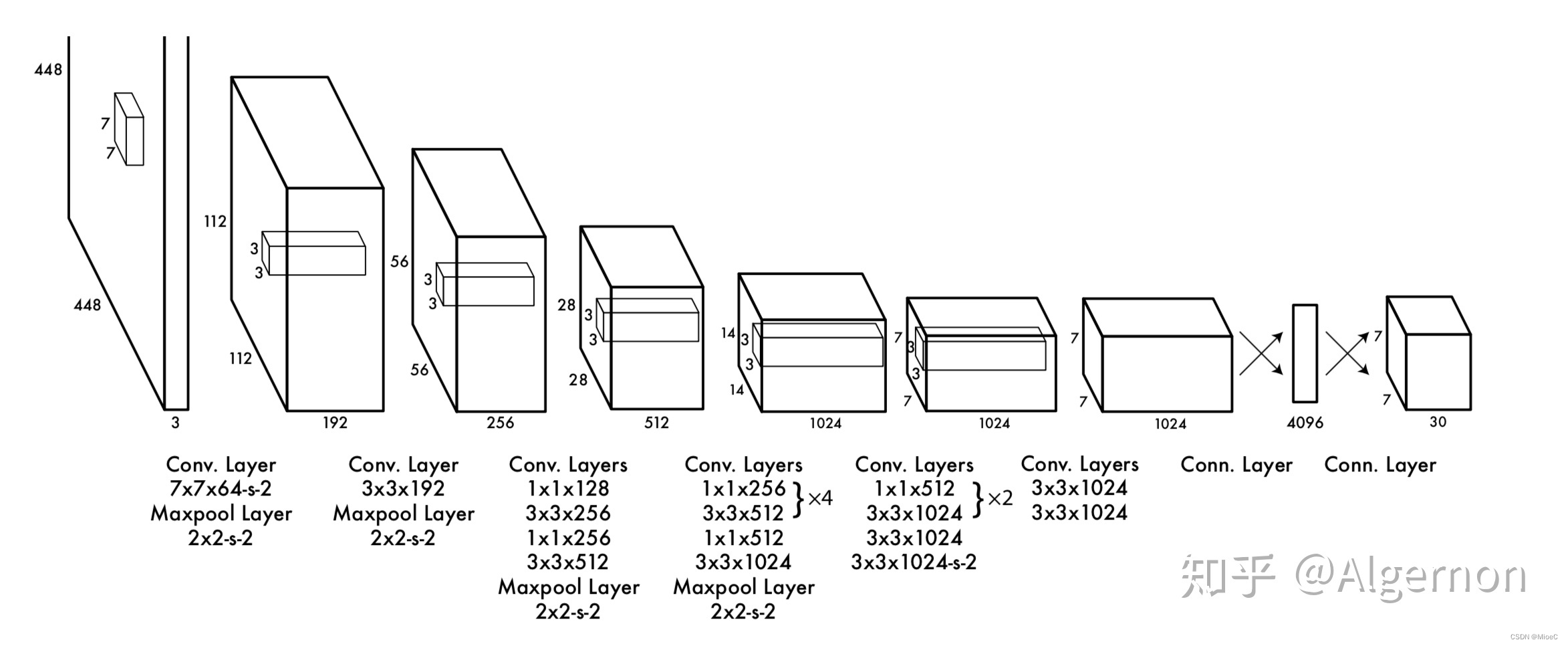
原理
- 将图像分为7*7 的格子,每个格子预测两个先验框
- 一开始会初始化GT的中心点,那些落在中心点的格子负责预测物体,并且一个格子只负责一个物体的预测,那些没落到中心点的格子,不负责预测物体。(简单说有中心点的格子负责预测物体,没有格子的不负责预测)
- 通过训练进行预测框的更新
解析
7 * 7 * 30
7cell* cell * ((x,y, w,h ,confi

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











