







1 简介
此电路使用同相放大器电路配置来放大麦克风输出信号。此电路的幅度稳定性非常好,在整个音频范围内仅具有微小的频率响应偏差。此电路旨在使用 5V 单电源来运行。
2 设计目标
2.1 输入电压最大值
2.2 输出电压最大值
-
2.3 电源
2.4 频率响应偏差
3 电路设计
根据设计目标,最终设计的电路结构和参数如下图:
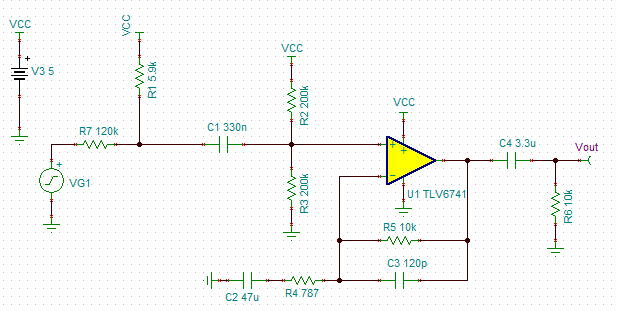
注意事项:
- 使用膝点电压低的电容器(钽、C0G,等等)和薄膜电阻器来帮助降低失真度
- 使用电池为此电路供电,以消除因切换电源而导致的失真
- 使用低电阻值电阻器和低噪声运算放大器实现低噪声的设计
- 共模电压等于使用电阻分压器设置的直流偏置电压加上麦克风输出电压导致产生的全部差异。对于具有互补对输入级的运算放大器,建议使共模电压保持远离交叉区域,以消除交叉失真的可能性
- 电阻器 R 1 用于偏置麦克风内置 JFET 晶体管,以实现麦克风指定的偏置电流
- 等效输入电阻由 R 1 、R 2 、R 3 确定。为 R 2 和 R 3 使用高电阻值电阻器,以增大输入电阻
- 为了偏置麦克风而连接到 R 1 的电压不必与运算放大器的电源电压相同。通过为实现麦克风偏置而使用电压较高的电源,将可以使用较低的偏置电阻器值
4 麦克风规格
| 麦克风参数 | 值 |
| 灵敏度 -94dB SPL(1Pa) | -35±4dBV |
| 电流消耗最大值 | 0.5mA |
| 阻抗 | 2.2kΩ |
| 标准工作电压 | 2Vdc |
5 设计计算
- 将灵敏度转换为每帕斯卡的电压
- 将每帕斯卡的电压转换为每帕斯卡的电流
- 压力达到 2Pa 这一最大值时会出现最大输出电流
- 计算偏置电阻器。在以下公式中,Vmic 是麦克风标准工作电压
- 将放大器的输入共模电压设置为中位电压。与 R3 并联的 R2 的等效电阻应该比 R1大10倍,以麦克风电流的绝大部分流经 R1
- 计算最大输入电压
- 计算生成最大输出电压摆幅所需的增益
- 计算 R 4 以设置步骤 7 中计算的增益。选择 10kΩ 作为反馈电阻器 R 5 的值
- 根据 20Hz 时的允许偏差计算低频转角频率。在以下公式中,G_pole1 是由所有频率为“f”的极点生成的增益。请注意,一共有三个极点,所以需要除以三
- 计算的截止频率计算 C1
- 计算的截止频率计算 C2
- 根据 20kHz 时的允许偏差计算高频极点。在以下公式中,G_pole2 是由所有频率为“f”的极点生成的增益
- 计算 C3
- 计算输出电容器 C4 。假设输出负载 R6 为 10kΩ
6 电路仿真
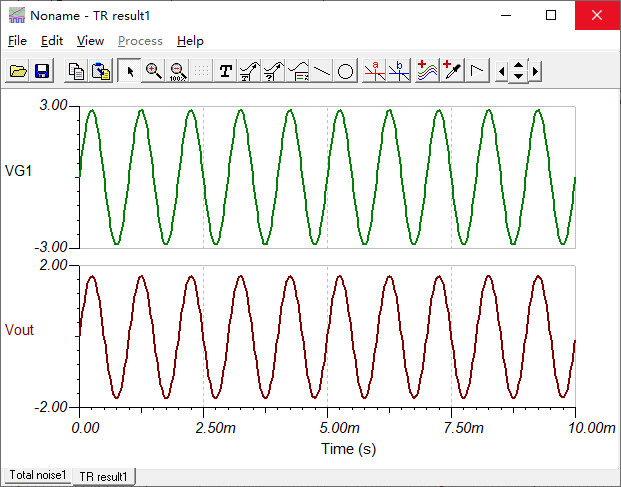
时域仿真:
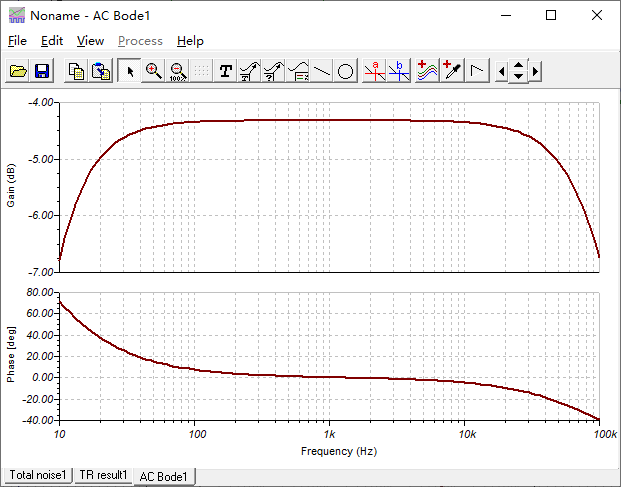
频率仿真:
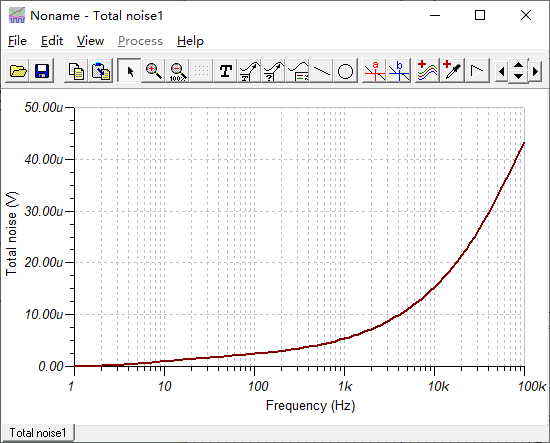
噪声仿真:



















 8607
8607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











