




 本文围绕Faster R-CNN展开,它抛弃Selectave Search,引入RPN网络,使用区域提名加速检测。介绍了其思想,如Anchor思想、RoI Pooling层等;阐述损失函数和训练方法;通过PASCAL VOC和COCO数据集实验,表明该方法提升检测效率,效果优于以往方法。
本文围绕Faster R-CNN展开,它抛弃Selectave Search,引入RPN网络,使用区域提名加速检测。介绍了其思想,如Anchor思想、RoI Pooling层等;阐述损失函数和训练方法;通过PASCAL VOC和COCO数据集实验,表明该方法提升检测效率,效果优于以往方法。
https://blog.youkuaiyun.com/whz1861/article/details/78768398
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network(RPN) that shares full-image net
Faster R-CNN 抛弃了 Selectave Search, 引入了 RPN 网络,使用区域提名,使得分类,回归一起共用卷积特征,从而进一步加速了检测过程。其中Faster RCNN使用了Anchor的思想对在Feature map上进行预处理,产生2w左右的候选框,使得RPN的回归变成了回归到anchor的相对位置,使得网络更加稳定。
思想
首先,Fast RCNN检测网络的主要思想:
- 使用一个简化的 SPP 层— RoI Pooling 层,操作与 SPP 相似 2. 训练和测试不再分多步
- a. 不用存储中间特征结果,可使得梯度通过 RoI Pooling 层直接传播
- b. 分类与回归用 Multi-task 的方式一起训练
- SVD :使用 SVD 分解全连接层的参数矩阵,压缩为两个规模小很多的全连接层
解决 R-CNN 和 SPP-Net 中 2000 左右候选框带来的重复计算问题。
然后,overfeat虽然是一个端到端的训练过程,最终的网络进行了分类和回归网络多任务,但在预测的时候,仍然采用的是sliding window的思想。计算复杂度同样很大,因此作者提出了一种RPN网络,共享特征提取,使得网络的效率大大提升。
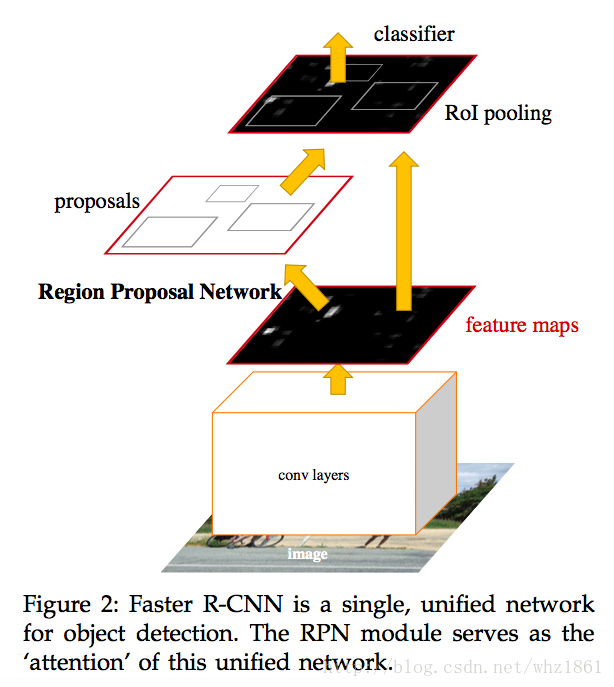
Region Proposal Networks
- 基础网络采用ZF或者VGG,则feature层的深度为256-d和512-d
- 然后将feature作为reg和cls的基础特征进行预测

| 数字 | 解释 |
|---|---|
| 171 | ZF模型在feature层的感受野 |
| 228 | VGG模型在feature层的感受野 |
| 256-d | ZF模型feature层的深度 |
| 512-d | VGG模型feature层的深度 |
| 3x3/1x1 | feature层后接nxn(n=3)卷积进行特征提取,后面接两个1x1卷积分别对应reg和cls层 |
| k | anchor的个数,论文k=9k=9,由3个scale和3个apect ratios组层 |
| 4k | 对应RPN回归reg层输出的深度:[(x1,y1,w1,h1x1,y1,w1,h1),(x2,y2,w2,h2x2,y2,w2,h2) … (xk,yk,wk,ykxk,yk,wk,yk)] |
| 2k | 对应RPN分类cls层输出的深度:[(bg1,fg1bg1,fg1),(bg2,fg2bg2,fg2) … (bgk,fgkbgk,fgk)] |
| ~2400 | 对于feature层上,一般会产生大约2400个特征点W∗H=60∗40=2400W∗H=60∗40=2400(对于1000x600的图像来说) |
| ~20000 | 对于feature层上,一般会产生大约20000个anchor候选区域W∗H∗k=60∗40∗9=21600W∗H∗k=60∗40∗9=21600 |
| ~6000 | 特征层产生的2w个anchor,去掉超过边界的区域,剩下大约6000个区域用于训练 |
| ~2000 | 对于产生的6000个区域,采用NMS(0.7),将剩余2000个左右候选区域 |
Translation-Invariant Anchors
对于区域候选区域的产生,之前有过很多方法:
| 方法 | 输出层数 | 参数个数 | 说明 |
|---|---|---|---|
| MultiBox | (4+1)*800 | 6.1∗1066.1∗106 | 1536*(4+1)*800 for GoogleNet |
| FasterRCNN | (4+2)*9 | 2.8∗1042.8∗104 | 512*(4+2)*9 for VGG |
- 注:对于anchor的提出,其具有一个非常重要的性质:平移不变形。
- 因为最终的回归框,是相对于anchor进行计算的,如果图像上的物体进行了平移,相对应的anchor提取的候选区域也可以进行相应的平移,从而可保障物体能够被检测出来。
Multi-Scale Anchors as Regression References
对于多尺度检测,以前也有很多方法:
- 金字塔pyramids:比如DPM,Fast RCNN,SPPnet,Overfeat等
- 该方法对图像和特征层进行不同的尺度缩放,然后在每一个尺寸下,进行sliding window
- 多尺度滤波器(multiple filter sizes)
本文提出了一种完全不同的多尺度检测方法:pyramids of anchors。该方法基于multi-scales和multi-aspect-ratios
损失函数Loss Function
-
RPN:
- cls:二分类binary class label
- 正样本:
- i) highest Intersection-over-Union(IoU) overlap with a ground-truth box
- ii) IoU overlap higher than 0.7 with any ground-truth box
- 注:有可能一个ground-truth box被多个anchor赋予正样本
- 负样本:
- i) IoU is lower than 0.3 for all ground-truth boxes.
- 其他样本:
- 其他anchor不作为正负样本,不参与训练
- 正样本:
-
reg:
- 采用Fast RCNN的Smooth L1Smooth L1函数
SmoothL1(x)={0.5∗|x|2|x|−0.5 if|x|<1 otherwiseSmoothL1(x)={0.5∗|x|2 if|x|<1|x|−0.5 otherwise
-
坐标转换:
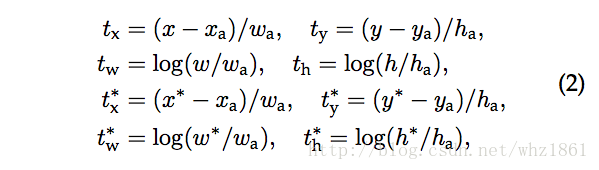
-
其中变量x,xa,x∗分别代表:
变量 含义 x predicted box xa anchor box x∗ ground-truth box 注:对于y,w,h同理
-
- 采用Fast RCNN的Smooth L1Smooth L1函数
- cls:二分类binary class label
从而损失函数定义为:

其中:
| 变量 | 含义 |
|---|---|
| i | 对于每一个mini-batch中的anchor索引【正负样本】 |
| pi | 对于每一个anchor ii被预测为物体的概率 |
| p∗ | ground-truth:如果为正样本则为1,如果为负样本则为0 |
| ti | 代表回归层中的4个坐标点x,y,w,hx,y,w,h |
| t∗ | 代表回归层中的的ground-true box,但是其坐标是相对于positive anchor【做过坐标转换的】 |
| Lcls | 分类的损失函数,log loss,分为两类(object vs. not object) |
| Lreg(ti,t∗) | 采用Fast RCNN中的Smooth L1Smooth L1函数,如上所述 |
| p∗Lreg | 表示回归的loss只针对postive anchor |
| - | (p∗=1p∗=1for positive anthor; p∗=0p∗=0 for otherwise) |
| Ncls | 分类权重系数,Ncls=256Ncls=256,所有正负样本的数量 |
| Nreg | 回去权重系数,Nreg≈2400Nreg≈2400,对于所有的特征点【anchor的位置,特征图大小为60x40】 |
| λ | 分类与回归损失函数的平衡系数,λ=10λ=10【实验证明该系数最好,能够把分类和回归损失平衡到一个数量级】 |
-
注:
-
就近原则
This can be thought of as bounding-box regression from an anchor box to a nearby ground-truth box
-
基于之前RoI 提取方法:Fast RCNN,SPPnet
- bounding-box regression基于任意的RoI大小,从而具有多尺度性质
- 在feature层上,采用3x3的卷积核进行特征提取,然后接两个1x1卷机进行cls和reg输出
- 每一个feature map上的特征点输出,都有k【anchor数量】个bounding-box regressior需要学习,并且相互之间独立,不共享权重
-
RPN训练过程
- anchor选取方式:在训练过程中,一种可能就是对所有anchor进行loss反向传播,但是由于负样本占据绝大多数,从而导致训练方向向negative sample发生偏移,从而,作者从所有的positive anchor和negative anchor中随机挑选了256个样本进行loss计算和反向传播。其中positive anchor和negative anchor比例为1:1。如果正本样个数少于128个,则用负样本补齐。
- 学习参数:
- 初始化:
- 所有feature特征提取层,采用预训练模型参数初始化
- 其他层采用zero-mean Gaussian distribution with standard deviation 0.01
- 对于ZF来说,所有参数都进行学习,对于VGG来说,只训练conv3-1之后的参数
- 学习率:分阶段学习对于PASCAL VOC
- 前60K:0.001
- 后20K:0.0001
- momentum:0.9
- decay:0.0005
- 初始化:
训练方法
论文提供了三种训练方法:
- Alternating training: 交替训练RPN和Fast RCNN
- 首先训练RPN
- 然后利用RPN参数初始化网络,在进行Fast RCNN训练
- Approminate joint training: 端到端学习,同时学习RPN和Fast RCNN网络
- 虽然该方法忽略了proposal boxes坐标的可导性,但是通过逼近,也可以得到比较好的结果,最终的训练时间可以缩短25-50%。
- Non-appromixate joint training:
- 考虑RPN作为Fast RCNN的输入,在反向传播过程中,需要考虑box coorinate的梯度,因此在该方法中,论文采用了一种可微的RoI Pooling层。参考论文[Instance-aware semantic segmentation via multi-task network cascades]中的“RoI warping”层。
4-Step Alternating Training:
- 训练RPN网络:加载预训练模型,进行端到端训练
- 训练Fast RCNN网络:同样加载完全预训练模型【参数不是RPN网络训练之后的参数】,采用RPN输出的proposal进行训练
- 训练RPN网络:但是利用Fast RCNN的参数对RPN进行初始化,但是训练过程中,固定特征层的提取参数【the shared convolutional layers】只训练RPN区域提取过程中的参数。
- 训练Fast RCNN网络:固定与RPN共享的卷积特征提取层,如上,只训练Fast RCNN最中的分类回归部分。
- 上面的4步不断交替训练,多迭代几次,效果更好
| 参数 | 描述 |
|---|---|
| 600 | 将图像的短边缩放到600大小 |
| 16 | 对于VGG来说,最终的特征层上的尺度放缩比例为原图的1/16大小 |
| 3 scales | 对于anchor有3种尺寸面积:1282,256,51221282,256,5122,对应feature层为6,16,32 |
| 3 aspect ratios | 对于anchor有3中比例关系:1:1,1:2,2:1 |
| 20000 | 对于1000x600的图像,将在特征层产生20000个左右的anchor区域(≈60∗40∗9≈60∗40∗9) |
| 6000 | 去掉超出边界的anchor,2w个u区域剩余6000个左右【否则,这些区域将导致网络不收敛,但是在检测的时候,将超出边界的anchor区域进行裁剪,保留图像内的部分】 |
| 2000 | 为了避免anchor区域过剩,采用NMS(0.7)后,将6000anchor区域降低到2000左右【在检测的时候,采用不同数量的anchor候选框进行评估】 |
Anchor与网络对应关系:
对于anchor的大小,从尺度和比例两个角度考虑:
-
对于ZF模型
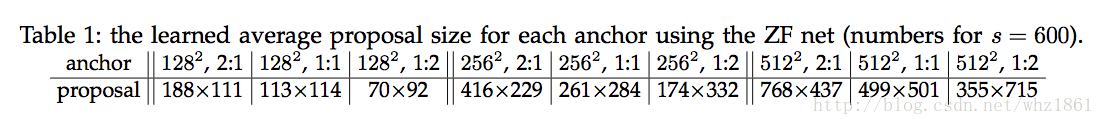
-
对于VGG模型:
scale\ratios 1:1 1:2 2:1 128*128 [-55,-55,72,72]->127*127 [-35,-79,52,96]->87*175 [-83,-39,100,56]->183*95 256*256 [-119,-119,136,136]->255*255 [-79,-167,96,184]->175*351 [-175,-87,192,104]->367*191 512*512 [-247,-247,264,264]->511*511 [-167,-343,184,360]->351*703 [-359,-183,376,200]->735*383
实验
PASCAL VOC数据集
实验一:
<span style="color:#000000"><code>基础网络ZF的效果及RPN网络的作用分析
</code></span>- 1

说明:
- Faster RCNN在Pascal Voc2007的测试集上,达到了59.9%的AP,超过了之前的方法
- 训练:采用RPN+ZF模型【共享基础网络】,RPN中采用2000个anchor区域进行训练
- 测试:采用RPN+ZF模型【共享基础网络】,RPN生成300个候选框进行预测
-
采用消除法进行网络分析:
- 分析共享基础网络参数的作用
- 达到了58.7%
- 分析测试中RPN生成的候选区域个数的作用
- 在RPN生成300个候选框的时候,效果最好,达到了56.8%
- 分析RPN中回归网络的作用
- 因为没有cls分类概率,采用随机选取的方式
- RPN生成的候选区域越多,效果越好,但在随机选择的300个候选框时候,mAP仍能达到51.5%
- 分析RPN中的分类网络的作用
- 因为没有reg回归,产生proposal,采用anchor作为候选框
- 在候选框个数300好于1000,说明候选框不适越多越好。300的时候,达到了52.1%
- 分析VGG基础网络的作用
- 能够比较轻松的达到59.2%【mAP】
实验二
<span style="color:#000000"><code>基础模型VGG的效果分析 </code></span>- 1
- 分析共享基础网络参数的作用
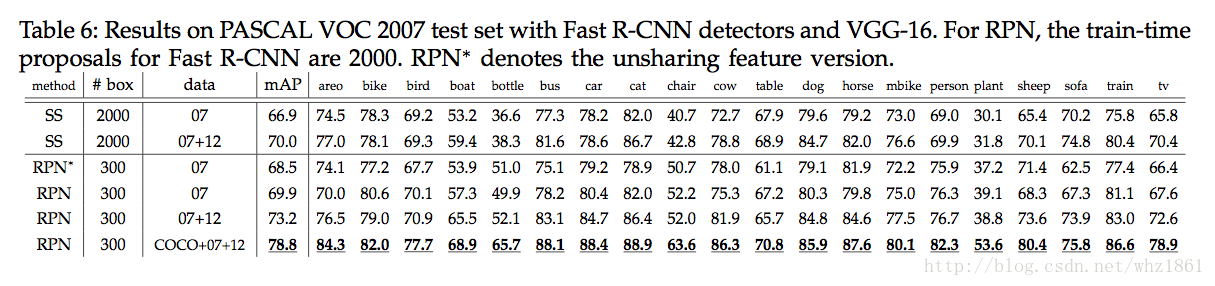

说明:
- 通过分析VGG基础网络模型,发现其效果比ZF模型要高很多,说明VGG模型的特征表达能力要好很多
- 如果训练集越大,网络训练的效果越好

说明:
- Faster RCNN检测框架的速度要比Fast RCNN快很多
实验三
<span style="color:#000000"><code>分析不同的anchor对于检测的影响
</code></span>- 1
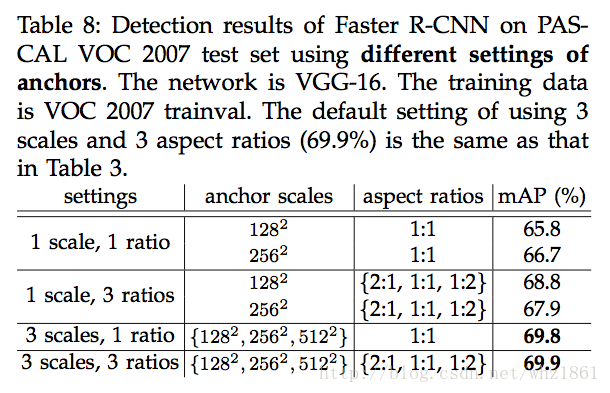
说明:
- scale与aspect ratios相比,scale的作用更大
实验四
<span style="color:#000000"><code>分析RPN的Loss函数中的cls与reg损失的权衡参数lambda的作用
</code></span>- 1

说明:
- 实验表明当λ=10λ=10的时候,网络效果最好。
- 因为λ=10λ=10,使得网络的损失函数中的cls部分与reg部分在归一化后是同一个两级的。
实验五
<span style="color:#000000"><code>分析Recall-to-IoU的作用
</code></span>- 1
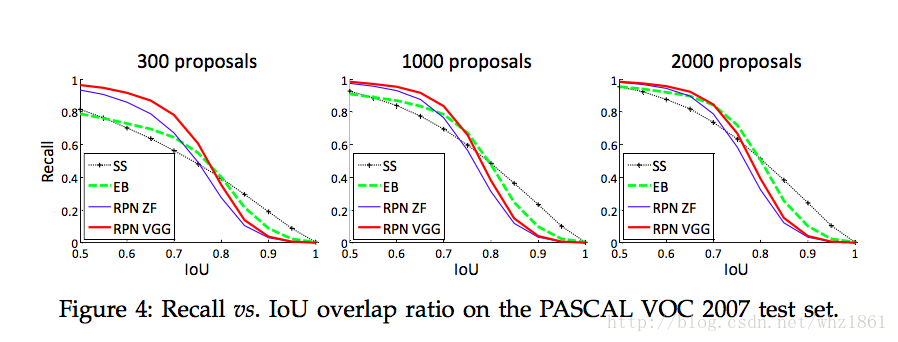
The plots show that the RPN method behaves gracefully when the number of proposals drops from 2000 to 300.
说明:
- 上图说明,当proposal个数从2000降到300的时候, 相对于SS,EB候选框提取方法,RPN网络表现的更加稳定
实验六
<span style="color:#000000"><code>One-Stage Detection vs. Two-Stage Proposal + Detection
</code></span>- 1

说明:
- One-Stage:类似于Overfeat网络
- Two-Stage:类似于Faster RCNN
- dense,3 scales, 3 aspect ratios 2000:
- In this system, the ‘proposals’ are dense sliding windows of 3 scales(128,256,512) and 3 aspect ratios(1:1,1:2,2:1)
- Fast RCNN训练预测class-specific scores和regress box locations,通过sliding window
- 实验表明:本文提出的Two-Stage方法效果更好,将近6%的提升
COCO数据集
实验一
<span style="color:#000000"><code>对比分析Faster RCNN网络在COCO数据集上的效果
</code></span>- 1

说明:
- Faster RCNN结构采用RPN区域提名后,效果要比SS区域提名方法要好很多
- 训练数据的增加,对检测的效果有帮助
实验二
<span style="color:#000000"><code>Faster RCNN in ILSVRC & COCO 2015 competitions
</code></span>- 1
如果将框架中的基础网络部分替换成Resnet101,在COCO数据集上的效果能有进一步提升。
实验三
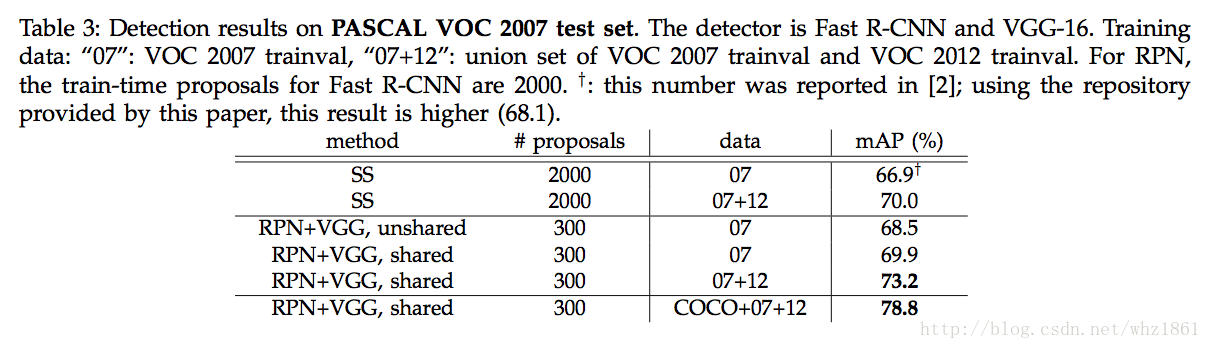
<span style="color:#000000"><code>from MS COCO to PASCAL VOC
</code></span>- 1
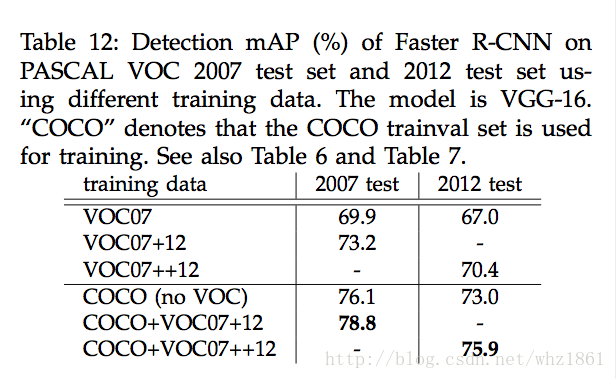
说明:
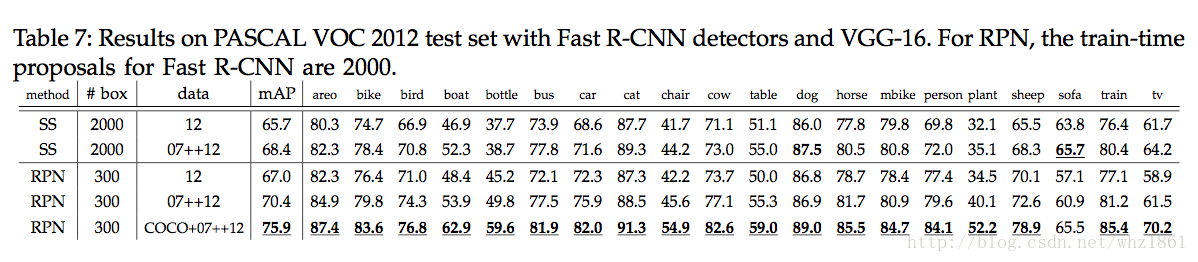
- 直接利用COCO上的训练结果去检测VOC的数据,最终的mAP提高了很多,从69.9%提升到了73.2%【mAP】
- 因为COCO的数据集种类包含VOC的所有类别
- 如果将COCO数据集和VOC数据集联合训练,最终的效果更好78.8%
结论
论文基于Fast RCNN,提出了一种区域生成方法RPN:
- 消除了之前的SS,ES候选框提名的方法【之前的方法速度极慢】
- 有效的提高了检测效率,能够达到5fps。【其中RPN需要10ms的时候】

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









