









68. 文本左右对齐
给定一个单词数组和一个最大宽度 maxWidth,格式化文本使其每行恰好有 maxWidth 个字符并完全(左右两端)对齐。
你应该使用贪心算法来放置尽可能多的单词在每一行。行中的单词之间用空格隔开,增加的空格应尽量均匀分配在单词之间。若行中只有一个单词,或者是最后一行,则左对齐,并在行的末尾填充空格。
每个单词只能出现在新的一行中,单词不能分解。
输入格式
words:一个字符串列表,每个字符串表示一个单词。
maxWidth:一个整数,表示每行的最大宽度。
输出格式
返回格式化后的字符串列表。
示例
示例 1
输入:
words = ["This", "is", "an", "example", "of", "text", "justification."]
maxWidth = 16
输出:
[
"This is an",
"example of text",
"justification. "
]
方法一:模拟行填充
解题步骤
初始化变量:设置当前行的单词列表和当前行的字符长度。
填充行:遍历所有单词,将单词添加到当前行直到超出最大宽度。
处理空格:对于非最后一行,均匀分配空格。如果只有一个单词或是最后一行,则左对齐。
生成最终文本:将处理后的行添加到结果列表中。
def fullJustify(words, maxWidth):
"""
文本左右对齐
:param words: List[str], 输入的单词列表
:param maxWidth: int, 最大行宽
:return: List[str], 对齐后的文本行列表
"""
res, cur, num_of_letters = [], [], 0
for w in words:
if num_of_letters + len(w) + len(cur) > maxWidth:
for i in range(maxWidth - num_of_letters):
cur[i % (len(cur) - 1 or 1)] += ' '
res.append(''.join(cur))
cur, num_of_letters = [], 0
cur += [w]
num_of_letters += len(w)
return res + [' '.join(cur).ljust(maxWidth)]
# 示例调用
words = ["This", "is", "an", "example", "of", "text", "justification."]
maxWidth = 16
print(fullJustify(words, maxWidth)) # 输出见上例
方法二:贪心算法
解题步骤
遍历单词:使用贪心算法尽量多地填充每一行。
调整空格:确保空格分布均匀或符合题目要求。
构造结果:根据每行的单词和空格构造最终的字符串。
def fullJustify(words, maxWidth):
"""
使用贪心算法进行文本左右对齐
:param words: List[str], 输入的单词列表
:param maxWidth: int, 最大行宽
:return: List[str], 对齐后的文本行列表
"""
cur, num_of_letters = [], 0
res = []
for word in words:
if num_of_letters + len(word) + len(cur) > maxWidth:
if len(cur) == 1:
res.append(cur[0].ljust(maxWidth))
else:
num_spaces = maxWidth - num_of_letters
space_between_words, extra = divmod(num_spaces, len(cur) - 1)
for i in range(extra):
cur[i] += ' '
res.append((' ' * space_between_words).join(cur))
cur, num_of_letters = [], 0
cur.append(word)
num_of_letters += len(word)
# Handle the last line
res.append(' '.join(cur).ljust(maxWidth))
return res
# 示例调用
words = ["This", "is", "an", "example", "of", "text", "justification."]
maxWidth = 16
print(fullJustify(words, maxWidth)) # 输出见上例
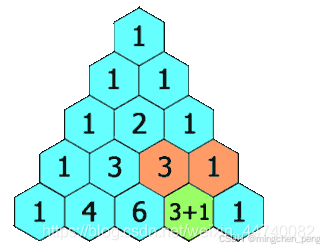
119. 杨辉三角 II
给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行。
class Solution:
def getRow(self, rowIndex: int) -> List[int]:
res=[]
for i in range(0,rowIndex+1):
t=[1]*(i+1)#将每一行的元素初始化为1
if i>1:#从第三行开始
for j in range(1,i):#除了第一个元素和最后一个元素
t[j]=res[i-1][j]+res[i-1][j-1] #每个元素是它左上方和右上方的数的和
res.append(t)
return res[-1]
补充题3. 求区间最小数乘区间和的最大值
1293. 网格中的最短路径
57. 插入区间
给出一个无重叠的 ,按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
示例 1:
输入: intervals = [[1,3],[6,9]], newInterval = [2,5]
输出: [[1,5],[6,9]]
示例 2:
输入: intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval =[4,8]
输出: [[1,2],[3,10],[12,16]]
解释: 这是因为新的区间[4,8]与[3,5],[6,7],[8,10]重叠。
解题思路
感觉此题和56题合并区间基本一样,就多了一个插入区间。把插入的区间添加进原来的区间集合,然后就是合并区间的问题,就和56题一样了,合并区间的解题思路见56题解(56.合并区间)。
# Definition for an interval.
# class Interval:
# def __init__(self, s=0, e=0):
# self.start = s
# self.end = e
class Solution:
def insert(self, intervals, newInterval):
"""
:type intervals: List[Interval]
:type newInterval: Interval
:rtype: List[Interval]
"""
intervals.append(newInterval)#比56题多的一行代码
ans=[]
intervals = sorted(intervals,key = lambda start: start.start)
ans.append(intervals[0])
for i in range(1,len(intervals)):
if ans[-1].end<intervals[i].start:
ans.append(intervals[i])
elif intervals[i].end>ans[-1].end:
ans[-1].end=intervals[i].end
return ans
29. 两数相除
722. 删除注释
30. 串联所有单词的子串
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。注意子串要包含所有的单词,且不能有重复和遗漏。
示例 1:
输入:
s = “barfoothefoobarman”,
words = [“foo”,“bar”]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 “barfoo” 和 “foobar”。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = “wordgoodgoodgoodbestword”,
words = [“word”,“good”,“best”,“word”]
输出:[]
1.滑动窗口+哈希表
这是一个查找子串的问题,可以通过滑动窗口配合哈希表来解决。主要思路是:
建立词频表:首先统计 words 数组中各单词的频率。
滑动窗口搜索:由于单词长度固定,我们可以每次移动一个单词的长度,而不是逐个字符移动。对于每个可能的单词起始位置(0 到单词长度),使用滑动窗口检查是否可以匹配 words 中的所有单词。
匹配验证:使用另一个哈希表记录窗口中单词的出现次数,如果与 words 的词频表相匹配,则记录当前开始位置。
def findSubstring(s: str, words: list) -> list:
from collections import Counter
if not s or not words:
return []
word_len = len(words[0])
word_count = len(words)
total_len = word_len * word_count
words_count = Counter(words)
def check(start):
seen = Counter()
# 检查每个窗口内的单词频率
for i in range(start, start + total_len, word_len):
word = s[i:i + word_len]
if word in words_count:
seen[word] += 1
if seen[word] > words_count[word]:
return False
else:
return False
return True
results = []
# 只需要检查 word_len 种情况
for i in range(word_len):
for j in range(i, len(s) - total_len + 1, word_len):
if check(j):
results.append(j)
return results
# 测试代码
s1 = "barfoothefoobarman"
words1 = ["foo","bar"]
print(findSubstring(s1, words1)) # Output: [0, 9]
s2 = "wordgoodgoodgoodbestword"
words2 = ["word","good","best","word"]
print(findSubstring(s2, words2)) # Output: []
# encoding = utf-8
# 开发者:xxx
# 开发时间: 15:01
# "Stay hungry,stay foolish."
class Solution(object):
def findSubstring(self, s, words):
import itertools
res = []
len(words)
permutations_lst = list(itertools.permutations(words, len(words)))
for i in permutations_lst:
str1 = ''.join(i)
s1 = s
for _ in range(len(s)+1):
index = s1.find(str1)
if index != -1:
if index not in res:
res.append(index)
s1 = s1[:index]+"_"+s1[index+1:]
res.sort()
return res
if __name__ == '__main__':
sol = Solution()
print(sol.findSubstring("aaaaaaaaaaaaaaaaaaaaa", ["aa","aa"]))
剑指 Offer 25. 合并两个排序的链表
方法一:迭代
注意到题目中要求的空间复杂度为O(1),因此只能使用迭代的方法来实现,因为迭代不使用额外的空间,只利用几个额外的指针来完成链表节点的重新连接。
思路:
1.使用ListNode(0)构造一个虚拟链表,其头节点值pHead为0,后面节点为空;
2.使用cur指针构建新链表,cur指向pHead,后续其他排完序的节点都会接在cur之后;
3.迭代条件:pHead1和pHead2都不为空。比较pHead1和pHead2的大小,cur指针指向较小者,同时头节点的值较小的链表,其头节点需向后移一个节点(因为原先的头节点已经接在cur之后)。由于现在cur指向虚拟节点pHead的位置,因此迭代结束后cur指向下一个节点,即新链表的首元节点。
4.当最初的两个链表有一个排列完后,迭代结束,如果某个链表还有剩余,则直接将其接到新链表的末尾,最后返回虚拟头结点的下一个节点,即合并后的链表头。
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
#
# 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
#
#
# @param pHead1 ListNode类
# @param pHead2 ListNode类
# @return ListNode类
#
class Solution:
def Merge(self, pHead1: ListNode, pHead2: ListNode) -> ListNode:
pHead = ListNode(0) # 创建一个虚拟头结点
cur = pHead # 使用 cur 指针来构建新链表
while pHead1 and pHead2:
if pHead1.val < pHead2.val:
cur.next = pHead1
pHead1 = pHead1.next
else:
cur.next = pHead2
pHead2 = pHead2.next
cur = cur.next
# 如果某个链表还有剩余,则直接将其接到新链表的末尾
if pHead1:
cur.next = pHead1
if pHead2:
cur.next = pHead2
return pHead.next # 返回虚拟头结点的下一个节点,即合并后的链表头
方法二:递归
使用递归的方法不满足题目中对于空间复杂度的限制,但其解题的方式值得学习。
思路:
1.递归条件:比较当前两个链表中值较小的头节点,把它链接到已经合并的链表中,然后对两个链表剩余的节点依旧做排序操作,也就是再次比较两个链表的剩余部分的头节点的值;
2.基线条件:两个链表都为空.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
#
# 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
#
#
# @param pHead1 ListNode类
# @param pHead2 ListNode类
# @return ListNode类
#
class Solution:
def Merge(self , pHead1: ListNode, pHead2: ListNode) -> ListNode:
# write code here
if pHead1 is None: #对空链表的特殊分析
return pHead2
if pHead2 is None:
return pHead1
pHead = None
if pHead1.val < pHead2.val:
pHead = pHead1
pHead.next = self.Merge(pHead1.next,pHead2)
else:
pHead = pHead2
pHead.next = self.Merge(pHead1,pHead2.next)
return pHead
1109. 航班预订统计
每次预定的时候只有两个地方会导致预定位置数发生变化,即
「预定开始的航班」 和 「预定结束的航班号+1的航班」
开始的地方会导致这个地方增加m个航班,结束的地方不再需要这些位置,所以会减去m个航班。
我们并不需要真的记录每个位置的状态,只需要记录有变化的位置即可,他们所持有的信息其实是一样的。
在「有变化的位置」添加变化的状态,之后以【叠加前面状态】的方式,来持续这个变化的状态
在「变化结束的位置」减去这个变化的状态,还原原来的状态
这里有 n 个航班,它们分别从 1 到 n 进行编号。
有一份航班预订表 bookings ,表中第 i 条预订记录 bookings[i] = [firsti, lasti, seatsi] 意味着在从 firsti 到 lasti (包含 firsti 和 lasti )的 每个航班 上预订了 seatsi 个座位。
请你返回一个长度为 n 的数组 answer,里面的元素是每个航班预定的座位总数。
示例 1:
输入:bookings = [[1,2,10],[2,3,20],[2,5,25]], n = 5
输出:[10,55,45,25,25]
解释:
航班编号 1 2 3 4 5
预订记录 1 : 10 10
预订记录 2 : 20 20
预订记录 3 : 25 25 25 25
总座位数: 10 55 45 25 25
因此,answer = [10,55,45,25,25]
示例 2:
输入:bookings = [[1,2,10],[2,2,15]], n = 2
输出:[10,25]
解释:
航班编号 1 2
预订记录 1 : 10 10
预订记录 2 : 15
总座位数: 10 25
因此,answer = [10,25]
//官方题解 python 篇
class Solution:
def corpFlightBookings(self, bookings: List[List[int]], n: int) -> List[int]:
nums = [0] * n
for left, right, inc in bookings:
nums[left - 1] += inc
if right < n:
nums[right] -= inc
for i in range(1, n):
nums[i] += nums[i - 1]
return nums
剑指 Offer 41. 数据流中的中位数
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
void addNum(int num) - 从数据流中添加一个整数到数据结构中。
double findMedian() - 返回目前所有元素的中位数。
示例 1:
输入:
[“MedianFinder”,“addNum”,“addNum”,“findMedian”,“addNum”,“findMedian”]
[[],[1],[2],[],[3],[]]
输出:[null,null,null,1.50000,null,2.00000]
示例 2:
输入:
[“MedianFinder”,“addNum”,“findMedian”,“addNum”,“findMedian”]
[[],[2],[],[3],[]]
输出:[null,null,2.00000,null,2.50000]
思路
要求随时可以提取一段数据流中的中位数,由题意可知,分两种情况:数据流个数为奇数,或者数据流个数为偶数。
我们可以想像,一串数据,我们以中间为节点切成两段,我们要求随时可以提取其中一段的顶部,或者两端的顶部求平均值。
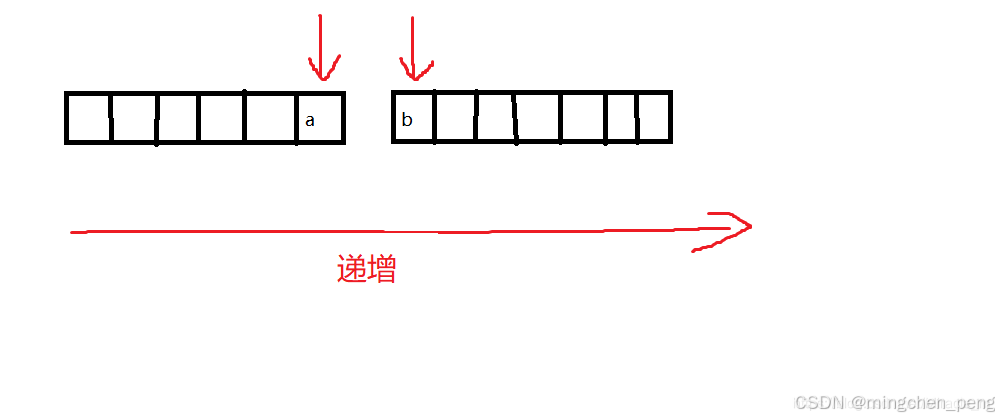
如上图所示,如果保持整个数据有序(这里设置为递增)则,a比左边都大,b比左边都小。维护某一段数据,保持有序,最常用的办法就是堆排序。
那么,我们分别用两个堆,维护左边较小的数,使之成为大顶堆;右边较大的数,使之成为小顶堆。
由于python中自带的堆为小顶堆,那么要构建大顶堆,只需要对需要维护的数据取反即可。(值得注意的是,进入堆和出堆的时候,都要取反)
class MedianFinder:
def __init__(self):
"""
initialize your data structure here.
"""
self.A = []#维护较小数的大顶堆
self.B = []#维护较大数的小顶堆
def addNum(self, num: int) -> None:
# if self.A is None and self.B is None:
# heappush(self.A,-num)
# elif len(self.A)==len(self.B):
# heappush(self.B,num)
# heappush(self.A,-heappop(self.B))
# else:
# heappush(self.A,-num)
# heappush(self.B,-heappop(self.A))
############优化########################
if len(self.A)==len(self.B):
heappush(self.A,-heappushpop(self.B,num))
else:
heappush(self.B,-heappushpop(self.A,-num))
def findMedian(self) -> float:
if len(self.A)==len(self.B):
return (-self.A[0]+self.B[0])/2
else:return -self.A[0]
1438. 绝对差不超过限制的最长连续子数组
补充题17. 两个有序数组第k小的数
eg1:
A=[1,3,4,5,7,13,19]
B=[2,6,7,9,13,15,20]
k=6
啥意思呢?
请你找到第k小的数是多少?返回的结果是A/B中的某一个值,这个值,是AB融合之后再排序的数组C中,第k小那个数。
AB融合排序:1,2,3,4,5,6,7,7,9,13,13,19,20;
显然,第6小就是6,返回6即可。
二、笔试AC普通解法
1.双指针移动计数法
先别急着融合,我们不需要将整体数组全部融合,再去遍历求,那样速度将是o(N+M),太慢。
笔试为了简单编写代码,还能快速AC,怎么办呢?
设立2个指针,p1指着A的0位置,p2指着B的0位置;
然后领count==0做计时器,在指针滑动过程中,count计数,count计数到k就停止,说明找到了第k小的数。
p1,p2怎么滑动呢?
比较A[p1]和B[p2]的大小,谁小谁滑动,说明小的先排前面,做的工作就相当于融合AB数组为C。
但是count计数到了k就停
public static int findKthMinNum(int[] A, int[] B, int k){
int p1 = 0;
int p2 = 0;
int m = A.length;
int n = B.length;
int count = 0;//计数器
int ans = A[p1] <= B[p2] ? A[p1++] : B[p2++];//先定为这个
if (k == 1) return ans;
count++;//刚刚已经排好了一个了
while (p1 < m && p2 < n){
//同时不越界,其中一个越界,就只会剩另一个,之前有讲过merge代码就这样
ans = A[p1] <= B[p2] ? A[p1++] : B[p2++];//谁小谁移动
count++;
if (count == k) return ans;
}
while (p1 < m){
//如果A还没有搞定全
ans = A[p1++];//谁小谁移动
count++;
if (count == k) return ans;
}
while (p1 < m){
//如果B还没有搞定全
ans = B[p2++];//谁小谁移动
count++;
if (count == k) return ans;
}
//全部都越界了还没有搞定,那只能是k过大
return -1;
}
补充题13. 中文数字转阿拉伯数字
214. 最短回文串
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
示例 1:
输入: “aacecaaa”
输出: “aaacecaaa”
示例 2:
输入: “abcd”
输出: “dcbabcd”
class Solution:
def shortestPalindrome(self, s: str) -> str:
#思路:直觉:从第一个字符开始找回文串,剩下的再反转到前面,必然是正确答案,不可能通过在开头插入字符来得到更短的回文。
rev = s[::-1]
idx = 0
n = len(s)
for i in range(n):
if s[:n-i] == rev[i:]:
return rev[:i]+s
return ""
716. 最大栈
设计一个最大栈数据结构,既支持栈操作,又支持查找栈中最大元素。
实现 MaxStack 类:
MaxStack() 初始化栈对象
void push(int x) 将元素 x 压入栈中。
int pop() 移除栈顶元素并返回这个元素。
int top() 返回栈顶元素,无需移除。
int peekMax() 检索并返回栈中最大元素,无需移除。
int popMax() 检索并返回栈中最大元素,并将其移除。如果有多个最大元素,只要移除 最靠近栈顶 的那个。
示例:
输入
["MaxStack", "push", "push", "push", "top", "popMax", "top", "peekMax", "pop", "top"]
[[], [5], [1], [5], [], [], [], [], [], []]
输出
[null, null, null, null, 5, 5, 1, 5, 1, 5]
解释
MaxStack stk = new MaxStack();
stk.push(5); // [5] - 5 既是栈顶元素,也是最大元素
stk.push(1); // [5, 1] - 栈顶元素是 1,最大元素是 5
stk.push(5); // [5, 1, 5] - 5 既是栈顶元素,也是最大元素
stk.top(); // 返回 5,[5, 1, 5] - 栈没有改变
stk.popMax(); // 返回 5,[5, 1] - 栈发生改变,栈顶元素不再是最大元素
stk.top(); // 返回 1,[5, 1] - 栈没有改变
stk.peekMax(); // 返回 5,[5, 1] - 栈没有改变
stk.pop(); // 返回 1,[5] - 此操作后,5 既是栈顶元素,也是最大元素
stk.top(); // 返回 5,[5] - 栈没有改变
class MaxStack:
def __init__(self):
self.stack = []
self.max_stack = [-10000001]
def push(self, x: int) -> None:
self.stack.append(x)
self.max_stack.append(max(x, self.max_stack[-1]))
def pop(self) -> int:
self.max_stack.pop()
return self.stack.pop()
def top(self) -> int:
return self.stack[-1]
def peekMax(self) -> int:
return self.max_stack[-1]
def popMax(self) -> int:
val = self.max_stack.pop()
temp = [self.stack.pop()]
while temp[-1] != val:
self.max_stack.pop()
temp.append(self.stack.pop())
temp.pop()
while temp:
v = temp.pop()
self.stack.append(v)
self.max_stack.append(max(v, self.max_stack[-1]))
return val
381. O(1) 时间插入、删除和获取随机元素 - 允许重复
解题思路: 这道题其实就是考一些语言特性,对于Python 语言我们可以直接用list来完成,插入使用append,删除使用remove,随机取数就随机一个int作为下标直接取。
import random
class RandomizedCollection:
def __init__(self):
"""
Initialize your data structure here.
"""
self.val_list = []
def insert(self, val: int) -> bool:
"""
Inserts a value to the collection. Returns true if the collection did not already contain the specified element.
"""
if val in self.val_list:
self.val_list.append(val)
return False
else:
self.val_list.append(val)
return True
def remove(self, val: int) -> bool:
"""
Removes a value from the collection. Returns true if the collection contained the specified element.
"""
if val in self.val_list:
self.val_list.remove(val)
return True
else:
return False
def getRandom(self) -> int:
"""
Get a random element from the collection.
"""
list_len = len(self.val_list)
if list_len > 0:
index = random.randint(0, list_len - 1)
return self.val_list[index]
else:
return None
# Your RandomizedCollection object will be instantiated and called as such:
# obj = RandomizedCollection()
# param_1 = obj.insert(val)
# param_2 = obj.remove(val)
# param_3 = obj.getRandom()
273. 整数转换英文表示
示例 1:
输入:num = 123
输出:“One Hundred Twenty Three”
示例 2:
输入:num = 12345
输出:“Twelve Thousand Three Hundred Forty Five”
示例 3:
输入:num = 1234567
输出:“One Million Two Hundred Thirty Four Thousand Five Hundred Sixty Seven”
示例 4:
输入:num = 1234567891
输出:“One Billion Two Hundred Thirty Four Million Five Hundred Sixty Seven Thousand Eight Hundred Ninety One”
class Solution:
def numberToWords(self, num: int) -> str:
to19 = 'One Two Three Four Five Six Seven Eight Nine Ten Eleven Twelve ' \
'Thirteen Fourteen Fifteen Sixteen Seventeen Eighteen Nineteen'.split()
tens = 'Twenty Thirty Forty Fifty Sixty Seventy Eighty Ninety'.split()
def helper(num):
if num < 20:
return to19[num - 1:num]
if num < 100:
return [tens[num // 10 -2]] + helper(num % 10)
if num < 1000:
return [to19[num // 100 - 1]] + ["Hundred"] + helper(num % 100)
for p, w in enumerate(["Thousand", "Million", "Billion"], 1):
if num < 1000 ** (p + 1):
return helper(num // 1000 ** p) + [w] + helper(num % 1000 ** p)
return " ".join(helper(num)) or "Zero"

















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









