









456. 132模式
题目内容】:给定一个整数序列:a1, a2, …, an,一个132模式的子序列 ai, aj, ak 被定义为:当 i < j < k 时,ai < ak < aj。设计一个算法,当给定有 n 个数字的序列时,验证这个序列中是否含有132模式的子序列。
示例1:
输入: [1, 2, 3, 4]
输出: False
解释: 序列中不存在132模式的子序列。
示例 2:
输入: [3, 1, 4, 2]
输出: True
解释: 序列中有 1 个132模式的子序列:[1, 4, 2].
示例 3:
输入: [-1, 3, 2, 0]
输出: True
解释: 序列中有 3 个132模式的的子序列: [-1, 3, 2], [-1, 3, 0] 和 [-1, 2, 0].
解法示例
解法 1:暴力解
感觉平时写各种python小程序都能写得很快,但是一轮到这种考题就瞬间愣逼,只剩下暴力解了。有点像大学时的期末考试感觉。
class Solution(object):
def find132pattern(self, nums):
if len(nums) < 3:
return False
for i in range(len(nums)):
first = nums[i]
for j in range(i + 1, len(nums)):
if nums[j] > first:
mid = nums[j]
for k in range(j+1,len(nums)):
if first < nums[k] < mid:
return True
return False
暴力解根据题意还是能很快地写出来,也能成功解决题目的几个例子,但是LeetCode测试样例中肯定有些变态的异常场景,果然运行超时。
解法 2:调用 itertools库
不得不说,python各类封装库对用户的友好。对于这个问题,直接调用 itertools库,只需要5行代码就能解决。
import itertools
class Solution(object):
def find132pattern(self, nums):
if len(nums) < 3:
return False
res = itertools.combinations(nums, 3)
for i in res:
if i[0] < i[2] < i[1]:
return True
return False
这里我简单解释一下itertools库的两个牛逼函数:combinations和permutations。话说我第一次看到有人用这两个函数进行求题时,我就觉得好牛逼,惊为天人。Python还有这种库!把很复杂的逻辑思考转为现成的几行代码。我觉得要是面试时,有考官出组合求解类型的题时,用这个方法肯定也会让他大吃一惊,然后继续问你有没有其他方法。
combinations:用法是itertools.combinations(mylist,num),对mylist列表取出 任意num个元素进行组合;
permutations:用法是itertools.combinations(mylist),对mylist列表所有元素进行排列
因此上述代码就是将nums列表中所有三元素组合都遍历求解。当然结果也是运行超时。
解法 3:一维单调栈
这个解法是在讨论区里看到的。大神所用的解法,不像二维栈一样,用stack[[min,max]]来存储过程数据,而是用栈保存最大值,将弹出的次大值与输入值比较。只要输入值比次大值小,就说明成功了!
不得不说,大神就是大神,想法新颖,代码精简,减少了计算空间!
class Solution:
def find132pattern(self, nums: List[int]) -> bool:
stack=[]
_Min=float("-inf")
for i in range(len(nums)-1,-1,-1):
if nums[i]<_Min:
return True
while stack and nums[i]>stack[-1]:
_Min=stack.pop()
stack.append(nums[i])
return False
下面我把我自己遇到的一些让人惊艳代码记录下,给有需要的同学参考。闻道有先后,请大神们勿喷。
1、带索引、值的遍历(这个应该很常见)
for i,k in enumerate(mylist)
2、求列表排序后,之前的索引值列表
[i for i,k in sorted(enumerate(mylist),reverse=True,key=lambda x:x[1])]
3、求列表某值的索引位置
[i for i,k in enumerate(mylist) if k == num]
4、三元表达式
return True if x>y else False
5、将字符串大小写进行转换
mystr.swapcase()
6、将列表中的字符串按数字进行排序,如 ['b3','a10','c1']
return sorted(mylist,key=lambda x:int(re.search('\d+').group(0)))
7、对两个列表进行元素交接,使两列表的和差值最小
list3 = list2 + list1
list1 = min(itertools.combinations(list3,len(list1)),key=lambda x:abs(sum(x)-sum(list3)/2))
8、求列表各元素的频度
return {i:mylist.count(k) for i,k in enumerate(set(mylist))}
剑指 Offer 12. 矩阵中的路径
请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一格开始,每一步可以在矩阵中向左、右、上、下移动一格。如果一条路径经过了矩阵的某一格,那么该路径不能再次进入该格子。例如,在下面的3×4的矩阵中包含一条字符串“bfce”的路径(路径中的字母用加粗标出)。
[[“a”,“b”,“c”,“e”],
[“s”,“f”,“c”,“s”],
[“a”,“d”,“e”,“e”]]
但矩阵中不包含字符串“abfb”的路径,因为字符串的第一个字符b占据了矩阵中的第一行第二个格子之后,路径不能再次进入这个格子。
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCCED”
输出:true
class Solution(object):
def exist(self, board, word):
"""
:type board: List[List[str]]
:type word: str
:rtype: bool
"""
if not board:
return False
rows = len(board)
cols = len(board[0])
visited = [[0]*cols for _ in range(rows)]
for row in range(rows):
for col in range (cols):
if self.dfs(row, col, rows, cols, board, word, visited):
return True
return False
def dfs(self, row, col, rows, cols, board, word, visited):
if not word:
return True
flag = False
if row>=0 and row<rows and col>=0 and col<cols \
and (visited[row][col] == 0) and word[0] == board[row][col]:
visited[row][col] =1
flag = self.dfs( row-1, col, rows, cols, board, word[1:], visited) \
or self.dfs( row+1, col, rows, cols, board, word[1:], visited) \
or self.dfs( row, col-1, rows, cols, board, word[1:], visited) \
or self.dfs( row, col+1, rows, cols, board, word[1:], visited)
if not flag:
visited[row][col] = 0
return flag
剑指 Offer 14- I. 剪绳子
给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]…k[m-1] 。请问 k[0]k[1]…*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
示例 1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1
示例 2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36
提示:
2 <= n <= 58
题解:动态规划
1.如果输入n=2,返回1,输入n=3,返回2.
2.dp[i]表示长度为i可以得到的最大乘积,dp[1]=1,dp[2]=2,dp[3]=3,因为对于n=2 3的情况,最大值是不做切分,如果输入n<3,已经直接返回,dp是为了确定n>=4的最大乘积。
3.n>=4时,对于i取值从1到i//2,取最大的dp[i-j]*dp[j]
class Solution:
def cuttingRope(self, n: int) -> int:
if n==2:
return 1
if n==3:
return 2
dp = [0 for i in range(n+1)]
dp[1] = 1
dp[2] = 2
dp[3] = 3
for i in range(4,n+1):
for j in range(1,i//2+1):
dp[i] = max(dp[i],dp[j]*dp[i-j])
return dp[n]
523. 连续的子数组和
题目
给你一个整数数组 nums 和一个整数 k ,编写一个函数来判断该数组是否含有同时满足下述条件的连续子数组:
子数组大小 至少为 2 ,且
子数组元素总和为 k 的倍数。
如果存在,返回 true ;否则,返回 false 。
如果存在一个整数 n ,令整数 x 符合 x = n * k ,则称 x 是 k 的一个倍数。0 始终视为 k 的一个倍数。
示例 1:
输入:nums = [23,2,4,6,7], k = 6
输出:true
解释:[2,4] 是一个大小为 2 的子数组,并且和为 6 。
示例 2:
输入:nums = [23,2,6,4,7], k = 6
输出:true
解释:[23, 2, 6, 4, 7] 是大小为 5 的子数组,并且和为 42 。
42 是 6 的倍数,因为 42 = 7 * 6 且 7 是一个整数。
示例 3:
输入:nums = [23,2,6,4,7], k = 13
输出:false
提示:
1 <= nums.length <= 105
0 <= nums[i] <= 109
0 <= sum(nums[i]) <= 231 - 1
1 <= k <= 231 - 1
思路和代码
这题我用了回溯用了暴力用了哈希和前缀和,都没有通过,我怎么那么优秀啊。
首先暴力很好想,就是枚举所有长度大于2的连续子数组,在判断一下是否满足条件,这很好写啊,超时。
回溯其实本质也就是暴力,但对于连续子数组的回溯(现在不会)我没写出来,写的有点问题,只能从第一个数开始试探情况。
最后看到了题目提示的关键词哈希表和前缀和,这我熟啊。但是不知道具体怎么用,就算求得到前缀和,那怎么得到不同连续子数组的情况,不还是要两层for循环遍历么?好的,吭哧吭哧写出来,调调调,漂亮,还是超时。
放弃,看别人的题解,太优秀了。
首先,这里面有一个一个概念——同余定理:
当两个数除以某个数的余数相等,那么二者相减后肯定可以被该数整除。
所以,哈希表怎么用?key是前缀和对k的余数,value是当前值的索引。(这谁啊,怎么那么聪明啊)
总体思路就是遍历数组,先求前缀和,然后求余res,判断余数是不是已经在字典dic中,且dic[res]和当前的索引i相差大于等于2,是则返回True。否则,注意,要判断余数在不在dic中,不在的话dic[res]=i。
为什么要多判断在不在,而不是直接赋值?
因为有种情况如[5,0,0,0],k=3。如果直接赋值,dic[2]前后等于0,1,2,本来后面三个0满足条件的,但这样一写,结果就会返回False。
此外,还有一种情况就是当前前缀和对k取余等于0,可以在for循环的时候判断一下,也可以在一开始的时候加入0:-1。
class Solution:
def checkSubarraySum(self, nums: List[int], k: int) -> bool:
# 前缀和
# 哈希表中 key是余数 value是下标
# 对nums进行遍历,一边求前缀和,一边求余数
# 判断余数是否已经在dic中 在的话 比较当前索引和dic[余数]相差是否大于等于2
# 逻辑漏洞5,0,0,0 k=3 5,5,5,5 2对应的value一直在变 结果返回false
dic = {0:-1}
pre = 0
for i in range(len(nums)):
pre += nums[i]
res = pre % k
# 前i个数正好整除k 要么在这写一个判断句 要么在初始时加0:-1
# if res == 0:
# return True
if res in dic and i - dic[res] >=2:
return True
#加入这样的一个判断句 如果2已经存在 不改变其值
if res not in dic:
dic[res] = i
return False
99. 恢复二叉搜索树
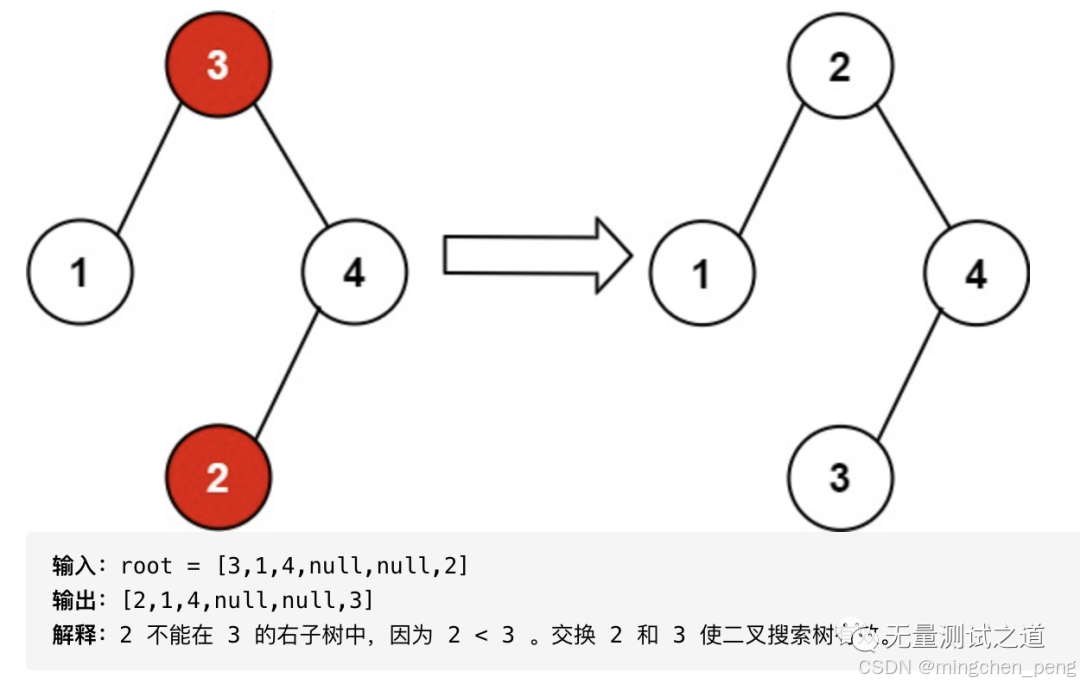
题解:
二叉搜索树的特征是任何一个节点的左子树中的所有节点的值都小于当前节点,其右子树中所有节点的值都大于当前节点。二叉搜索树的中序遍历结果应该是一个升序序列。
1.定义一个midorder函数,保存二叉树中序遍历结果midorder。
2.对midorder内的所有节点按照节点的val值升序排列,得到ordered_list。
3.对比midorder和ordered_list,用node_change保存ordered_list和midorder中不同的节点。
4.交换node_change中的节点的val值
class Solution(object):
def recoverTree(self, root):
midorderlist = self.midorder(root)
ordered_list = sorted([node.val for node in midorderlist])
print(ordered_list)
node_num = len(midorderlist)
node_change = []
for i in range(node_num):
if midorderlist[i].val!=ordered_list[i]:
node_change.append(midorderlist[i])
node_change[0].val,node_change[1].val = node_change[1].val,node_change[0].val
return root
def midorder(self,root):
res = []
if root==None:
return res
res = res + self.midorder(root.left)
res.append(root)
res = res + self.midorder(root.right)
return res
974. 和可被 K 整除的子数组
给定一个整数数组 A,返回其中元素之和可被 K 整除的(连续、非空)子数组的数目。
示例:
输入:A = [4,5,0,-2,-3,1], K = 5
输出:7
解释:
有 7 个子数组满足其元素之和可被 K = 5 整除:
[4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3]
思路:前缀和
首先这里要提前说明一下,关于除法取整,Python 采用的是向下取整。这里可能跟预想出现偏离的情况,比如,除数为负数的情况。看以下示例:
>>> 10 // 3
3
>>> 10 % 3
1
>>> 10 // -3
-4
>>> 10 % -3
-2
这里可以看到,关于正数取整,取模跟预想都不会有太大的偏离。但是对于负数,出现的结果可能就跟预想的不太一样。这里是因为前面说,Python 采用的是向下取整。
对于 10 ÷ -3 = -3.3333,这时向下取整就会得到 -4,那么余数就是 -2。这就是为什么会出现上面结果的原因。这部分内容仅做一些提示。
在本题当中 K,这里是除数,题目中说明 【2 <= K <= 10000】,所以不会有上面所的情况。但是 Python 当中负数取余所得的结果是正数,这里跟一些其他编程语言不同。有些语言负数取余的结果是负数,所以要额外进行处理。
本篇幅使用的是前缀和的思想。关于前缀和,大致说明下。
如果要求前 i 项的和,那么:
P[i] = A[0]+A[1]+…+A[i]
相应的前 i-1 项的和为:
P[i-1] = A[0]+A[1]+…+A[i-1]
那么,A[i] 的值也可以表示为
A[i] = P[i] - P[i-1]
那么相应的,如果要计算 i 项到 j 项连续子数组的和,也可用写成如下的形式:
sum[i…j] = P[j] - P[i-1],其中 (0 < i < j)
那么题目中要求,判断子数组的和是否能够被 K 整除,现在就等同于判断 (P[j]-P[i-1]) mod K == 0 是否成立。
在这里,额外提及一个定理:同余定理。
同余定理:给定一个正整数 m,如果两个整数 a 和 b 满足 a-b 能够被 m 整除,即 (a-b)/m 得到一个整数,那么就称整数 a 与 b 对模 m 同余。
那么上面需要判断的式子也就可以转换为求 P[j] mod K == P[i-1] mod K 式子是否成立。
具体的方法:
维护哈希表,其中哈希表键为前缀和模 K 的值,值为出现的次数。
遍历数组每项,求当前前缀和模 K,存入哈希表中
当不存在表中,则将键跟值存入
存在时,对应键的值 +1
遍历的同时,进行统计,如果哈希表中存在 key 与当前前缀和模 k 的值相等时:
说明前面存在前缀和模 K 的值与此次计算的值相同
将满足条件的 key 出现的次数,累加到结果中
具体的代码实现如下。
class Solution:
def subarraysDivByK(self, A: List[int], K: int) -> int:
# 这里是考虑前缀和本身被 K 整除的情况
hashmap = {0: 1}
pre_sum = 0
cnt = 0
for i in range(len(A)):
pre_sum += A[i]
# 取模
mod = pre_sum % K
# 这里使用字典的 get 方法
# 当存在相同的键时,累加到 cnt
if mod in hashmap:
cnt += hashmap[mod]
hashmap[mod] += 1
# 如果键在哈希表中,则次数加 1,
# 否则初始化为 1
else:
hashmap[mod] = 1
return cnt
340. 至多包含 K 个不同字符的最长子串
- 至多包含两个不同字符的最长子串

1)滑动窗口
动态地维护一个滑动窗口,如果检测到窗口内出现了超过两个不同的字符,则将窗口整体右移一格。
否则,将滑动窗口向右扩张一格。
最后返回滑动窗口的长度 -1。因为最后滑动窗口会比应该返回的长度多一格。
class Solution {
public int lengthOfLongestSubstringTwoDistinct(String s) {
if (s.length() < 3) {
return s.length();
}
// map 储存一个滑动窗口中每个字符的出现次数
// 一个滑动窗口的左右边界 [left, right]
Map<Character, Integer> map = new HashMap<>();
int left = 0, right = 0;
while (right < s.length()) {
// 将最新的 c[right] 更新 map
char c = s.charAt(right);
map.put(c, map.getOrDefault(c, 0) + 1);
if (map.size() > 2) {
// 如果某个滑动窗口内超过了两个不同的字符,整体右移一格,
// 并将 left 所指的字符出现的次数减 1
char leftChar = s.charAt(left);
map.put(leftChar, map.get(leftChar) - 1);
if (map.get(leftChar) == 0) {
// 如果减 1 之后该字符出现次数为 0,则删除该字符对应的 key
map.remove(leftChar);
}
++left;
++right;
} else {
// 如果某个滑动窗口内的不同的字符数没有超过 2,则向右扩张滑动窗口
++right;
}
}
//最后返回滑动窗口的长度 -1。因为最后滑动窗口会比应该返回的长度多一格。
// return right - left + 1 - 1;
return right - left;
}
}
(2)滑动窗口优化
class Solution {
public int lengthOfLongestSubstringTwoDistinct(String s) {
Map<Character, Integer> map = new HashMap<>(); // map 储存一个滑动窗口中每个字符的出现次数
int res = 0;
int left = 0, right = 0;
while (right < s.length()) {
char c = s.charAt(right);
map.put(c, map.getOrDefault(c, 0) + 1);
// 如果某个滑动窗口内超过了两个不同的字符,左边界右移一格,
while(map.size() > 2) {
char leftChar = s.charAt(left++);
int value = map.get(leftChar) - 1;
if(value == 0) {
map.remove(leftChar);
}else {
map.put(leftChar, value);
}
}
right++;
res = Math.max(res, right - left + 1);
}
return res - 1; //循环结束时,right++导致,滑动窗口的长度一定会比正确的字串长一格
}
}
- 至多包含K个不同字符的最长子串
1)滑动窗口
上面的代码稍微修改即可
class Solution {
public int lengthOfLongestSubstringKDistinct(String s, int k) {
if (k == 0) {
return 0;
}
if (s.length() <= k) {
return s.length();
}
// map 储存一个滑动窗口中每个字符的出现次数
// 一个滑动窗口的左右边界 [left, right]
Map<Character, Integer> map = new HashMap<>();
int left = 0, right = 0;
while (right < s.length()) {
// 将最新的 c[right] 更新 map
char c = s.charAt(right);
map.put(c, map.getOrDefault(c, 0) + 1);
if (map.size() > k) {
// 如果某个滑动窗口内超过了两个不同的字符,整体右移一格,
// 并将 left 所指的字符出现的次数减 1
char leftChar = s.charAt(left);
map.put(leftChar, map.get(leftChar) - 1);
if (map.get(leftChar) == 0) {
// 如果减 1 之后该字符出现次数为 0,则删除该字符对应的 key
map.remove(leftChar);
}
++left;
++right;
} else {
// 如果某个滑动窗口内的不同的字符数没有超过 2,则向右扩张滑动窗口
++right;
}
}
return right - left; // 上面的循环结束后,滑动窗口的长度一定会比正确的字串长一格
}
}
(2)优化
class Solution {
public int lengthOfLongestSubstringKDistinct(String s, int k) {
if (k == 0) {
return 0;
}
if (s.length() <= k) {
return s.length();
}
Map<Character, Integer> map = new HashMap<>(); // map 储存一个滑动窗口中每个字符的出现次数
int res = 0;
int left = 0, right = 0;
while (right < s.length()) {
char c = s.charAt(right);
map.put(c, map.getOrDefault(c, 0) + 1);
// 如果某个滑动窗口内超过了两个不同的字符,左边界右移一格,
while(map.size() > k) {
char leftChar = s.charAt(left++);
int value = map.get(leftChar) - 1;
if(value == 0) {
map.remove(leftChar);
}else {
map.put(leftChar, value);
}
}
right++;
res = Math.max(res, right - left + 1);
}
return res - 1; //循环结束时,right++导致,滑动窗口的长度一定会比正确的字串长一格
}
}
73. 矩阵置零
题目:
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
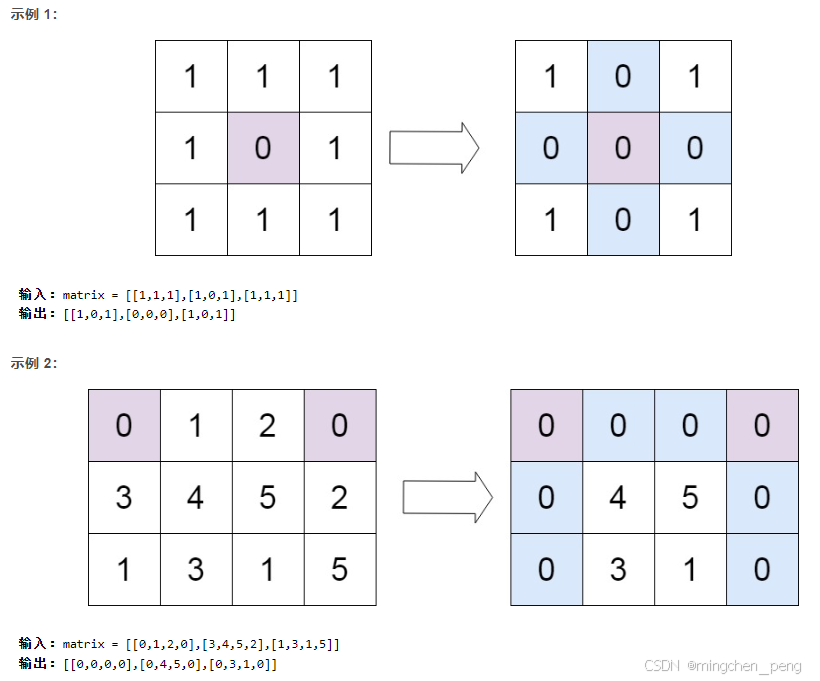
解题思路:
用两个数组l1和l2分别存放0元素的横坐标和纵坐标,后面再用for循环分别将横坐标和纵坐标进行零化(所对应的纵坐标和横坐标的元素全部变成零)
matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
l1 = [] #用来存放0元素的横坐标
l2 = [] #用来存放0元素的纵坐标
for i in range(len(matrix)):
for j in range(len(matrix[0])):
if matrix[i][j] == 0:
l1.append(i)
l2.append(j)
for i in set(l1): #将还有零的行给零化
matrix[i] = [0 for j in range(len(matrix[0]))]
for i in set(l2):
for j in range(len(matrix)):
matrix[j][i] = 0
print(matrix)
补充题8. 计算数组的小和
334. 递增的三元子序列
给定一个未排序的数组,判断这个数组中是否存在长度为 3 的递增子序列。
数学表达式如下:
如果存在这样的 i, j, k, 且满足 0 ≤ i < j < k ≤ n-1,
使得 arr[i] < arr[j] < arr[k] ,返回 true ; 否则返回 false 。
说明: 要求算法的时间复杂度为 O(n),空间复杂度为 O(1) 。
示例 1:
输入: [1,2,3,4,5]
输出: true
示例 2:
输入: [5,4,3,2,1]
输出: false
解题思路:题目要求使用O(n)的时间复杂度和O(1)的空间复杂度。那么LIS就不能用了(O(n2)的时间复杂度和O(n)的空间复杂度)。从前向后遍历数组,使用两个变量分别存储当前为止所观察到的最小值和次小值,当存在第三个值大于次小值时,返回True。
class Solution(object):
def increasingTriplet(self, nums):
"""
:type nums: List[int]
:rtype: bool
"""
first,second = float('inf'),float('inf')
for num in nums:
if num <= first:
first = num
elif num <= second:
second = num
else:
return True
return False
面试题 16.25. LRU缓存
223. 矩形面积
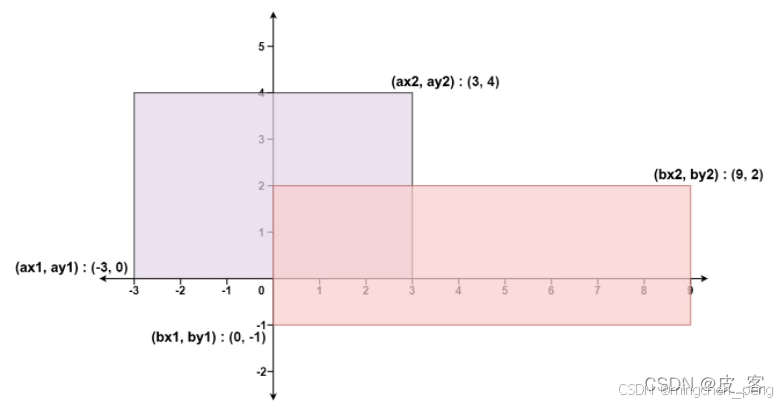
给你 二维 平面上两个 由直线构成且边与坐标轴平行/垂直 的矩形,请你计算并返回两个矩形覆盖的总面积。
每个矩形由其 左下 顶点和 右上 顶点坐标表示:
第一个矩形由其左下顶点 (ax1, ay1) 和右上顶点 (ax2, ay2) 定义。
第二个矩形由其左下顶点 (bx1, by1) 和右上顶点 (bx2, by2) 定义。
输入:ax1 = -3, ay1 = 0, ax2 = 3, ay2 = 4, bx1 = 0, by1 = -1, bx2 = 9, by2 = 2
输出:45
解析:
如果有重叠部分,有边界一定是两个长方形右边界靠左的一个,另外的三条边同理。然后右边界减左边界,上边界减下边界,如果小于0则代表没有重合部分。
class Solution(object):
def computeArea(self, ax1, ay1, ax2, ay2, bx1, by1, bx2, by2):
"""
:type ax1: int
:type ay1: int
:type ax2: int
:type ay2: int
:type bx1: int
:type by1: int
:type bx2: int
:type by2: int
:rtype: int
"""
s1 = (ax2 - ax1) * (ay2 - ay1) # 第一个面积
s2 = (bx2 - bx1) * (by2 - by1) # 第二个面积
overw = min(ax2, bx2) - max(ax1, bx1) # 重合宽=靠左的右边界-靠右的左边界
overh = min(ay2, by2) - max(ay1, by1) # 重合高=靠下的上边界-靠上的下边界
overs = max(overw, 0) * max(overh, 0) # 小于0说明没有重合
return s1 + s2 - overs # 两个面积减去重叠部分
486. 预测赢家
题目
给你一个整数数组 nums 。玩家 1 和玩家 2 基于这个数组设计了一个游戏。玩家 1 和玩家 2 轮流进行自己的回合,玩家 1 先手。开始时,两个玩家的初始分值都是 0 。每一回合,玩家从数组的任意一端取一个数字(即,nums[0] 或 nums[nums.length - 1]),取到的数字将会从数组中移除(数组长度减 1 )。玩家选中的数字将会加到他的得分上。当数组中没有剩余数字可取时,游戏结束。如果玩家 1 能成为赢家,返回 true 。如果两个玩家得分相等,同样认为玩家 1 是游戏的赢家,也返回 true 。你可以假设每个玩家的玩法都会使他的分数最大化。
示例
输入:nums = [1,5,2]
输出:false
解释:一开始,玩家 1 可以从 1 和 2 中进行选择。如果他选择 2(或者 1 ),那么玩家 2 可以从 1(或者 2 )和 5 中进行选择。如果玩家 2 选择了 5 ,那么玩家 1 则只剩下 1(或者 2 )可选。 所以,玩家 1 的最终分数为 1 + 2 = 3,而玩家 2 为 5 。因此,玩家 1 永远不会成为赢家,返回 false 。
动态规划解法
该方法也可以利用动态规划实现,动态规划第一步肯定要确定问题。上面方法其实已确定了子问题,子问题就是上述递归函数dfs计算的问题,根据列表计算当前玩家与对手玩家的得分差。这里定义二维数据dp[i][j]表示针对nums[i:j]这个子列表,当前玩家与对手玩家的得分差。我们可以写出如下的状态转移方程:
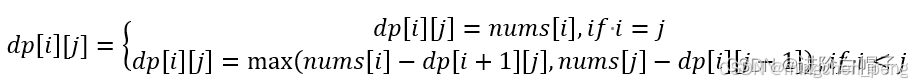
由于i,j表示nums的下标,因此i<=j。i=j表示只有一个数可选,这种情况只有当前玩家有分,另一玩家将没有可选的数据,因此当前玩家与对手玩家得分差为nums[i]。
当i<j的情况下,当前玩家有两种选择,一种是选择i数据,这样两玩家差就通过当前玩家的选择nums[i]与对手玩家在nums[i+1:j]的情况下的得分差得到。这个我表达不是特别清楚。大家可以琢磨一下。根据状态转移方程可以很容易写出如下代码:
class Solution:
def PredictTheWinner(self, nums: List[int]) -> bool:
if len(nums)<=2 and nums[0]>=nums[-1]:
return True
n=len(nums)
dp=[[0]*n for i in range(n)]
#初始化对角线 i=j
for i,num in enumerate(nums):
dp[i][i]=num
#i<j,i从大到小,j从小到大
for i in range(n-2,-1,-1):
for j in range(i+1,n):
#状态转移方程
dp[i][j]=max(nums[i]-dp[i+1][j],nums[j]-dp[i][j-1])
return dp[i][j]>=0
面试题 17.14. 最小K个数
class Solution:
def smallestK(self, arr: List[int], k: int) -> List[int]:
arr.sort()
return arr[:k]
利用python小根堆
小根堆就是一个上一层节点一定小于等于下一层的节点,当插入或者弹出小根堆时,小根堆会进行维护,继续满足上一层节点小于等于下一层的节点(自己的)。
#一个一个加入小根堆
from heapq import *
arr = [10,20,30,40,2,8,6,4,3,3,3,1,7,5,60]
heap = []
for i in range(len(arr)):
heappush(heap, arr[i])
print(heap)
本题题解:直接heapify放里面排序,就像排序一样,再一个个弹出来
class Solution:
def smallestK(self, arr: List[int], k: int) -> List[int]:
if k==0:
return list()
heapq.heapify(arr)
res = []
for i in range(k):
c = heapq.heappop(arr)
res.append(c)
return res
标准答案:复杂度要更低一些
思想就是转换为大根堆,把大的都给弹出去,最后留下的就是结果,一开始没有吧整个长度都放进堆里,放入k个之后做比较。目前这种掌握的还不好,日后再见到再理解消化两种的差异。
class Solution:
def smallestK(self, arr: List[int], k: int) -> List[int]:
if k == 0:
return list()
hp = [-x for x in arr[:k]]
heapq.heapify(hp)
for i in range(k, len(arr)):
if -hp[0] > arr[i]:
heapq.heappop(hp)
heapq.heappush(hp, -arr[i])
ans = [-x for x in hp]
return ans
剑指 Offer 43. 1~n整数中1出现的次数
给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。
示例1:
输入:n = 13
输出:6
示例2:
输入:n = 0
输出:0
提示:
0 <= n <= 2 * 109
思路
动态规划
我首先想到的是枚举,但是毫无疑问超时了,数位dp看的是题解写的。
枚举
思路:dp[i]表示1~i里已经出现的1的总数,状态方程:dp[i] = dp[i - 1] + 这个数中出现的1的次数
class Solution {
public:
int cacul_1(int num) {
int ans = 0;
while(num) {
ans += num % 10 == 1 ? 1 : 0;
}
return ans;
}
int countDigitOne(int n) {
vector<int>dp(n + 1,0);
for(int i = 1; i <= n; i++) {
dp[i] = dp[i - 1] + cacul_1(i);
}
return dp[n];
}
};
数位dp
这个思路是考虑每一个数位的情况,分别有0,1,其它三种情况。假设有220,则个位出现1的数有:1,11,21…211一共22个;如果是221,则有1,11,21…211 + 221共23个;如果是223则也是23个
解题
class Solution:
def digitOneInNumber(self, num: int) -> int:
digit, res = 1, 0
high, cur, low = num // 10, num % 10, 0
while high != 0 or cur != 0:
if cur == 0: res += high * digit
elif cur == 1: res += high * digit + low + 1
else: res += (high + 1) * digit
low += cur * digit
cur = high % 10
high //= 10
digit *= 10
return res
658. 找到 K 个最接近的元素
给定一个排序好的数组,两个整数 k 和 x,从数组中找到最靠近 x(两数之差最小)的 k 个数。返回的结果必须要是按升序排好的。如果有两个数与 x 的差值一样,优先选择数值较小的那个数。
示例 1:
输入: [1,2,3,4,5], k=4, x=3
输出: [1,2,3,4]
示例 2:
输入: [1,2,3,4,5], k=4, x=-1
输出: [1,2,3,4]
说明:
k 的值为正数,且总是小于给定排序数组的长度。
数组不为空,且长度不超过 104
数组里的每个元素与 x 的绝对值不超过 104
主要有两种方法做这道题:
方法一:
由于最后要保留 K 个元数,我们就需要删除 n - k个元数,并且,这些被删除的元数都在两端,所以可以使用左右两边相互碰撞的方法。从最左端和最右端开始碰撞对比,谁的差值小,谁就保留,另一个数则删除。
经过 n - k次重复之后就找到了左边界,输出 arr[left, left+k]。
class Solution:
def findClosestElements(self, arr: List[int], k: int, x: int) -> List[int]:
# 排除法(双指针)
size = len(arr)
left = 0
right = size - 1
# 我们要排除掉 size - k 这么多元素
remove_nums = size - k
while remove_nums:
# 调试语句
# print(left, right, k)
# 注意:这里等于号的含义,题目中说,差值相等的时候取小的
# 因此相等的时候,尽量缩小右边界
if x - arr[left] <= arr[right] - x:
right -= 1
else:
left += 1
remove_nums -= 1
return arr[left:left + k]
方法二:
二分查找最优区间的左边界(因为列表需要的长度已知,所以只找到左边界即可)
上一种方法的结论:
“排除法”的结论:(这个结论对于这道问题来说非常重要,可以说是解题的关键)
如果 x 的值就在长度为 size 区间内(不一定相等),要得到 size - 1 个符合题意的最接近的元素,此时看左右边界:
1、如果左边界与 x 的差值的绝对值较小,删除右边界;
2、如果右边界与 x 的差值的绝对值较小,删除左边界;
3、如果左、右边界与 x 的差值的绝对值相等,删除右边界。
讨论“最优区间的左边界”的取值范围:
首先我们讨论左区间的取值范围,使用具体的例子,就很很清楚地找到规律:
1、假设一共有 5 个数,[0, 1, 2, 3, 4],找 3 个数,左边界最多到 2;
2、假设一共有 8 个数,[0, 1, 2, 3, 4, 5, 6, 7],找 5 个数,左边界最多到 3。
因此,“最优区间的左边界”的索引的搜索区间为 [0, size - k],注意,这个区间的左右都是闭区间,都能取到。
定位左区间的索引,有一点技巧性,但并不难理解。由排除法的结论,我们先从 [0, size - k] 这个区间的任意一个位置(用二分法就是当前候选区间的中位数)开始,定位一个长度为 (k + 1) 的区间,根据这个区间是否包含 x 开展讨论。
1、如果区间包含 x,我们尝试删除 1 个元素,好让区间发生移动,便于定位“最优区间的左边界”的索引;
2、如果区间不包含 x,就更简单了,我们尝试把区间进行移动,以试图包含 x,但也有可能区间移动不了(极端情况下)。
说明一下,这里代码的意思就是首先确定一个整个区间,再来移动整个区间的起始位置,我也不是很理解,以后再看这种解法。
from typing import List
class Solution:
def findClosestElements(self, arr: List[int], k: int, x: int) -> List[int]:
size = len(arr)
left = 0
right = size - k
while left < right:
# mid = left + (right - left) // 2
mid = (left + right) >> 1
# 尝试从长度为 k + 1 的连续子区间删除一个元素
# 从而定位左区间端点的边界值
if x - arr[mid] > arr[mid + k] - x:
left = mid + 1
else:
right = mid
return arr[left:left + k]
912. 排序数组
选择排序
class Solution:
def sortArray(self, nums):
n = len(nums)
for i in range(n):
for j in range(i, n):
if nums[i] > nums[j]:
nums[i], nums[j] = nums[j], nums[i]
return nums
冒泡排序
class Solution:
def sortArray(self, nums):
n = len(nums)
for c in range(n):
for i in range(1, n - c):
if nums[i-1] > nums[i]:
nums[i - 1] , nums[i] = nums[i], nums[i - 1]
return nums
插入排序
class Solution:
def sortArray(self, nums):
n = len(nums)
for i in range(1, n):
while i > 0 and nums[i - 1] > nums[i]:
nums[i-1], nums[i] = nums[i], nums[i-1]
i -= 1
return nums
运行运行
希尔排序
class Solution:
def sortArray(self, nums):
n = len(nums)
gap = n//2
while gap:
for i in range(gap, n):
while i - gap >= 0 and nums[i-gap] > nums[i]:
nums[i - gap], nums[i] = nums[i], nums[i - gap]
i -= gap
gap //= 2
return nums
归并排序
def merge_sort(nums):
if len(nums) <= 1:
return nums
mid = len(nums) // 2
# 分
left = merge_sort(nums[:mid])
right = merge_sort(nums[mid:])
# 合并
return merge(left, right)
def merge(left, right):
res = []
i = 0
j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
res.append(left[i])
i += 1
else:
res.append(right[j])
j += 1
res += left[i:]
res += right[j:]
return res
快速排序
def quick_sort(nums):
n = len(nums)
def quick(left, right):
if left >= right:
return nums
pivot = left
i = left
j = right
while i < j:
while i < j and nums[j] > nums[pivot]:
j -= 1
while i < j and nums[i] <= nums[pivot]:
i += 1
nums[i], nums[j] = nums[j], nums[i]
nums[pivot], nums[j] = nums[j], nums[pivot]
quick(left, j - 1)
quick(j + 1, right)
return nums
return quick(0, n - 1)
堆排序
def heap_sort(nums):
# 调整堆
# 迭代写法
def adjust_heap(nums, startpos, endpos):
newitem = nums[startpos]
pos = startpos
childpos = pos * 2 + 1
while childpos < endpos:
rightpos = childpos + 1
if rightpos < endpos and nums[rightpos] >= nums[childpos]:
childpos = rightpos
if newitem < nums[childpos]:
nums[pos] = nums[childpos]
pos = childpos
childpos = pos * 2 + 1
else:
break
nums[pos] = newitem
# 递归写法
def adjust_heap(nums, startpos, endpos):
pos = startpos
chilidpos = pos * 2 + 1
if chilidpos < endpos:
rightpos = chilidpos + 1
if rightpos < endpos and nums[rightpos] > nums[chilidpos]:
chilidpos = rightpos
if nums[chilidpos] > nums[pos]:
nums[pos], nums[chilidpos] = nums[chilidpos], nums[pos]
adjust_heap(nums, pos, endpos)
n = len(nums)
# 建堆
for i in reversed(range(n // 2)):
adjust_heap(nums, i, n)
# 调整堆
for i in range(n - 1, -1, -1):
nums[0], nums[i] = nums[i], nums[0]
adjust_heap(nums, 0, i)
return nums
计数排序
def counting_sort(nums):
if not nums: return []
n = len(nums)
_min = min(nums)
_max = max(nums)
tmp_arr = [0] * (_max - _min + 1)
for num in nums:
tmp_arr[num - _min] += 1
j = 0
for i in range(n):
while tmp_arr[j] == 0:
j += 1
nums[i] = j + _min
tmp_arr[j] -= 1
return nums
桶排序
def bucket_sort(nums, bucketSize):
if len(nums) < 2:
return nums
_min = min(nums)
_max = max(nums)
# 需要桶个数
bucketNum = (_max - _min) // bucketSize + 1
buckets = [[] for _ in range(bucketNum)]
for num in nums:
# 放入相应的桶中
buckets[(num - _min) // bucketSize].append(num)
res = []
for bucket in buckets:
if not bucket: continue
if bucketSize == 1:
res.extend(bucket)
else:
# 当都装在一个桶里,说明桶容量大了
if bucketNum == 1:
bucketSize -= 1
res.extend(bucket_sort(bucket, bucketSize))
return res
10.基数排序
def Radix_sort(nums):
if not nums: return []
_max = max(nums)
# 最大位数
maxDigit = len(str(_max))
bucketList = [[] for _ in range(10)]
# 从低位开始排序
div, mod = 1, 10
for i in range(maxDigit):
for num in nums:
bucketList[num % mod // div].append(num)
div *= 10
mod *= 10
idx = 0
for j in range(10):
for item in bucketList[j]:
nums[idx] = item
idx += 1
bucketList[j] = []
return nums

















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









