



在搭建高性能 AI 或 HPC(高性能计算)集群时,你可能会遇到两种不同形态的 NVIDIA GPU:PCIe 版和 SXM 版。虽然它们核心芯片(如 A100、H100)可能完全相同,但在性能、扩展性和适用场景上却有显著差异。今天我们就来深入聊聊这两者的区别。
一、物理形态:通用插卡 vs 专用模块
-
PCIe 版 GPU
就是我们最常见的“显卡”形态——通过标准 PCIe x16 插槽插入服务器主板,像消费级显卡一样可插拔。兼容性强,适用于大多数通用服务器(如 Dell、HPE、浪潮等)。 -
SXM 版 GPU
并非传统意义上的“显卡”,而是一种板载式模块,直接安装在 NVIDIA 定制的 DGX 或 HGX 服务器主板上,使用专用的 SXM 插槽(如 SXM4、SXM5)。它不可在普通服务器上使用,属于“封闭生态”产品。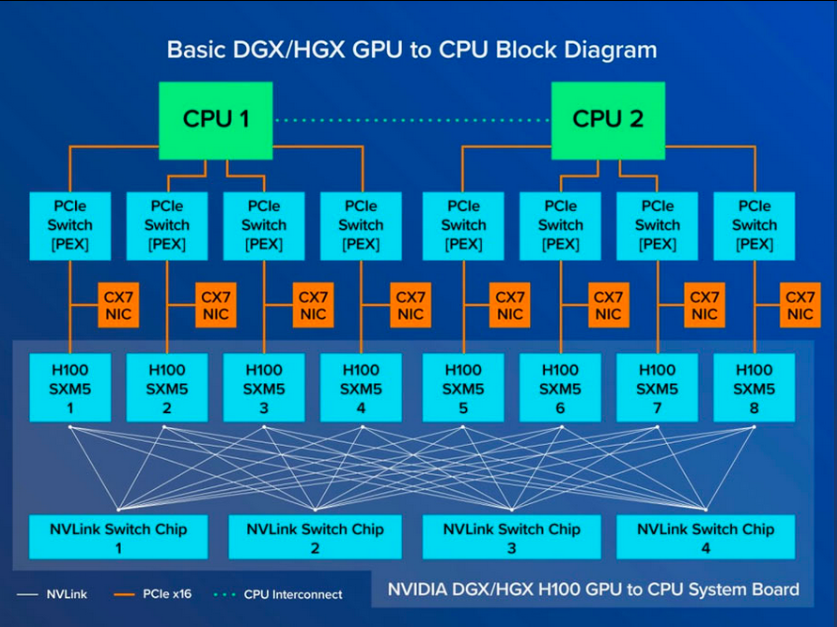
✅ 简单说:PCIe 版“即插即用”,SXM 版“专机专用”。
二、互连带宽:速度差距巨大
这是两者最核心的区别!
1. PCIe 版
- 默认通过 PCIe 总线通信(如 PCIe 4.0/5.0 x16)。
- 双向带宽最高约 64 GB/s(PCIe 4.0)或 128 GB/s(PCIe 5.0)。
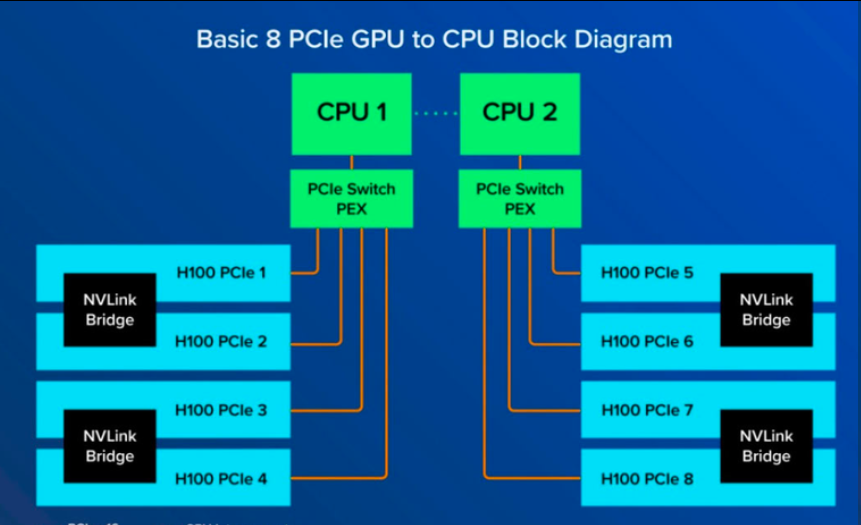
- 若需更高带宽,可搭配 NVLink 桥接器,但仅支持两两配对(例如 2 卡一组),无法实现多卡全互联。
- 多卡之间若无 NVLink,只能走 PCIe,速度受限。
2. SXM 版
- 原生集成 NVLink + NVSwitch 技术。
- 以 H100 SXM5 为例:单对 GPU 间带宽高达 900 GB/s。
- 在 DGX/HGX 系统中,8 张 GPU 通过 NVSwitch 实现全互联(All-to-All),任意两张卡都能高速通信。
- 显存可跨 GPU 访问,构建超大统一内存池(如 640GB 全局显存)。
🚀 举个例子:训练一个千亿参数大模型,SXM 架构的数据同步效率远高于 PCIe 方案。
三、性能对比(以 A100/H100 为例)
| GPU 型号 | 接口类型 | GPU-GPU 带宽 | 是否支持多卡全互联 | 典型平台 |
|---|---|---|---|---|
| A100 PCIe | PCIe 4.0 | 最高 64 GB/s(PCIe) 或 600 GB/s(NVLink 桥接,仅2卡) | ❌ 仅点对点 | 通用服务器 |
| A100 SXM4 | SXM4 + NVLink | 600 GB/s(全互联) | ✅ 8卡全连接 | DGX A100 / HGX A100 |
| H100 PCIe | PCIe 5.0 | 最高 128 GB/s(PCIe) 或 900 GB/s(NVLink 桥接,仅2卡) | ❌ | 通用服务器 |
| H100 SXM5 | SXM5 + NVLink 4.0 | 900 GB/s(全互联) | ✅ 8卡通过 NVSwitch 互联 | DGX H100 / HGX H100 |
⚠️ 注意:国内特供版 A800/H800 的 NVLink 带宽被限制为 400 GB/s,但仍保留 SXM 的全互联优势。
四、如何选择?看场景!
-
选 PCIe 版,如果你:
- 预算有限,使用通用服务器;
- 部署中小规模 AI 推理或训练任务;
- 需要灵活更换硬件或兼容多种设备。
-
选 SXM 版,如果你:
- 构建大规模 AI 训练集群(如 LLM、AIGC);
- 追求极致多卡通信效率;
- 有能力部署 DGX/HGX 系统,并接受高成本与封闭生态。
总结
| 维度 | PCIe 版 | SXM 版 |
|---|---|---|
| 通用性 | ✅ 高 | ❌ 仅限 NVIDIA 定制平台 |
| 带宽性能 | 中等(依赖 PCIe 或双卡 NVLink) | ⭐ 极高(全互联 NVLink + NVSwitch) |
| 扩展性 | 一般(多卡通信瓶颈明显) | 强(8卡高效协同) |
| 成本 | 相对较低 | 高(整机+服务绑定) |
💡 简单记忆:PCIe 是“经济适用型”,SXM 是“性能旗舰型”。
如果你正在规划 AI 基础设施,务必根据实际 workload 和预算权衡选择。对于超大规模训练,SXM 架构几乎是唯一选择;而对于大多数企业级应用,PCIe 版已足够胜任。
欢迎在评论区交流你的 GPU 选型经验!👇

















 5537
5537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









