




 英伟达发布H100GPU,采用先进N4工艺,集成800亿晶体管,专为AI训练设计。蓝海大脑服务器支持多至9个H100GPU,提供强大算力。通过对比强制风冷与间接液冷,后者在高负荷下散热效果更佳。
英伟达发布H100GPU,采用先进N4工艺,集成800亿晶体管,专为AI训练设计。蓝海大脑服务器支持多至9个H100GPU,提供强大算力。通过对比强制风冷与间接液冷,后者在高负荷下散热效果更佳。
导语
1.GPU的价值不止体现在深度学习,在高性能计算、人工智能、生物信息、分子模拟、计算化学、材料力学、系统仿真、流体力学、机械设计、生物制药、航空动力、地质勘探、气候模拟等领域,算法越来越复杂,需要处理的海量数据越来越巨大,高性能计算能力就显得尤为重要。近日为满足GPU服务器、高性能服务器、深度学习服务器、水冷工作站、水冷服务器、液冷工作站、液冷服务器等的高速运转,英伟达发布产品——H100 GPU。
2.随着信息技术的快速发展,高性能服务器的需求不断增长。为保障服务器长期可靠稳定运行,合适的散热技术显得至关重要。
3.基于蓝海大脑超融合平台的水冷GPU服务器及水冷GPU工作站采用绿色冷却技术,Gluster 分布式架构设计,提供大存储量,拥有开放融合的特性和超能运算的能力。
1 蓝海大脑服务器于 NVIDIA H100 GPU
蓝海大脑宣布服务器产品线全力支持最新的 NVIDIA H100 GPU。蓝海大脑服务器产品在单机上最多可支持4、8甚至9个H100 GPU,可为多种人工智能场景提供超强算力、灵活的资源调度和成熟的生态支持。

搭载NVIDIA H100 GPU的蓝海大脑服务器具有更强计算性能、更高的GPU间通信带宽和创新的计算架构,支持用户对更大、更复杂的模型进行训练和推理。同时,搭配蓝海大脑算力资源管理平台,用户可以更加便捷高效地使用AI集群算力资源。
基于GH100 GPU
据官方数据显示,全新的NVIDIA GH100 GPU不是基于之前传闻的台积电 N5工艺,而是使用更先进的N4工艺。整个芯片面积814mm²,相比GA100要小,但集成800亿晶体管,并采用更高频率的设计。
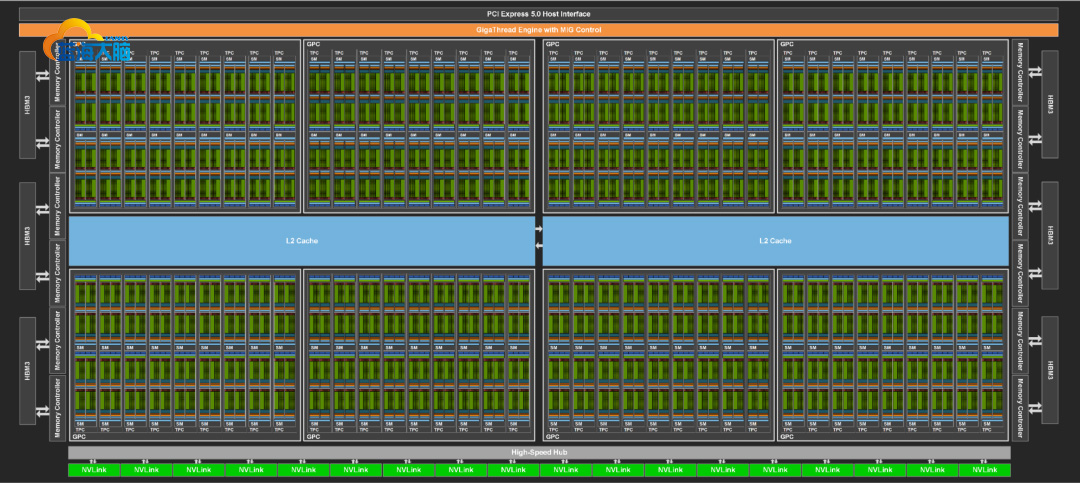
完整版GH100 GPU架构框图
完整规格的GH100 GPU规格,包含总计8个GPC图形集群,72个TPC纹理集群,144个SM流式多处理器,共计18432个FP32 CUDA核心(与目前传闻中AD102完整版完全吻合),专用于AI训练的第四代张量核心TensorCore为每组SM配备4个,共计528个。显存方面最大支持6个HBM3或HBM2e堆栈,6144bit显存位宽,L2缓存提升到60MB,并支持第四代NVLink和PCIe Gen5。</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









