






TPVFormer代码复现与部署
1.conda环境配置
我的环境:
- Ubuntu 20.04
- Python 3.8
- Pytorch 1.10.0
- CUDA 11.3
Conda虚拟环境生成:
conda create -n tpvformer python=3.8
配置Pytorch(由于conda没有安装库到正确位置需要进行手动指定):
pip install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio==0.10.0 /
-f https://download.pytorch.org/whl/cu113/torch_stable.html /
-t ./anaconda3/envs/tpvformer/lib/python3.8/site-packages /
-i https://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn /
测试Pytorch:
>>> import torch
>>> print(torch.__version__)
1.10.0+cu113r
安装依赖库:在requirment.txt中删除torch加入mmengine
pip install -r requirment.txt -t ./anaconda3/envs/tpvformer/lib/python3.8/site-packages -i https://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
Looking in indexes: https://pypi.mirrors.ustc.edu.cn/simple/
安装mmcv库时出现问题:
/home/thedh/anaconda3/envs/tpvformer/lib/python3.8/site-packages/torch/include/c10/util/Optional.h:672:23:
error: passing ‘const std::vector<c10::optionalc10::Stride,
std::allocator<c10::optionalc10::Stride > >’ as ‘this’ argument of
‘std::vector<_Tp, _Alloc>& std::vector<_Tp,
_Alloc>::operator=(std::vector<_Tp, _Alloc>&&) [with _Tp = c10::optionalc10::Stride; _Alloc =
std::allocator<c10::optionalc10::Stride >]’ discards qualifiers
[-fpermissive]
error: command ‘/usr/bin/g++’ failed with exit code 1
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for mmcv_full
Running setup.py clean for mmcv_full Failed to build mmcv_full ERROR:
ERROR: Failed to build installable wheels for some pyproject.toml
based projects (mmcv_full)
问题产生原因:直接安装mmcv与 cuda 和 pytorch版本不符合导致g++编译失败,去https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html查询版本信息:
需要制定详细的版本信息:
pip install mmcv-full==1.4.7 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html -t ./anaconda3/envs/tpvformer/lib/python3.8/site-packages
报错:AttributeError: module 'numpy' has no attribute 'int64' AttributeError: module 'numpy' has no attribute 'long'
由于numpy版本共存导致pip管理失效 ,需要手动删除并且更换版本:
cd ./anaconda3/envs/tpvformer/lib/python3.8/site-packages
sudo rm -r ./numpy
cd ~
pip install numpy==1.23.1 -t ./anaconda3/envs/tpvformer/lib/python3.8/site-packages -i https://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
Looking in indexes: https://pypi.mirrors.ustc.edu.cn/simple/
2.配置网络
由于代码使用mmdetection框架基于脚本构建,无法直接看到全局的model,对模型结构进行输出
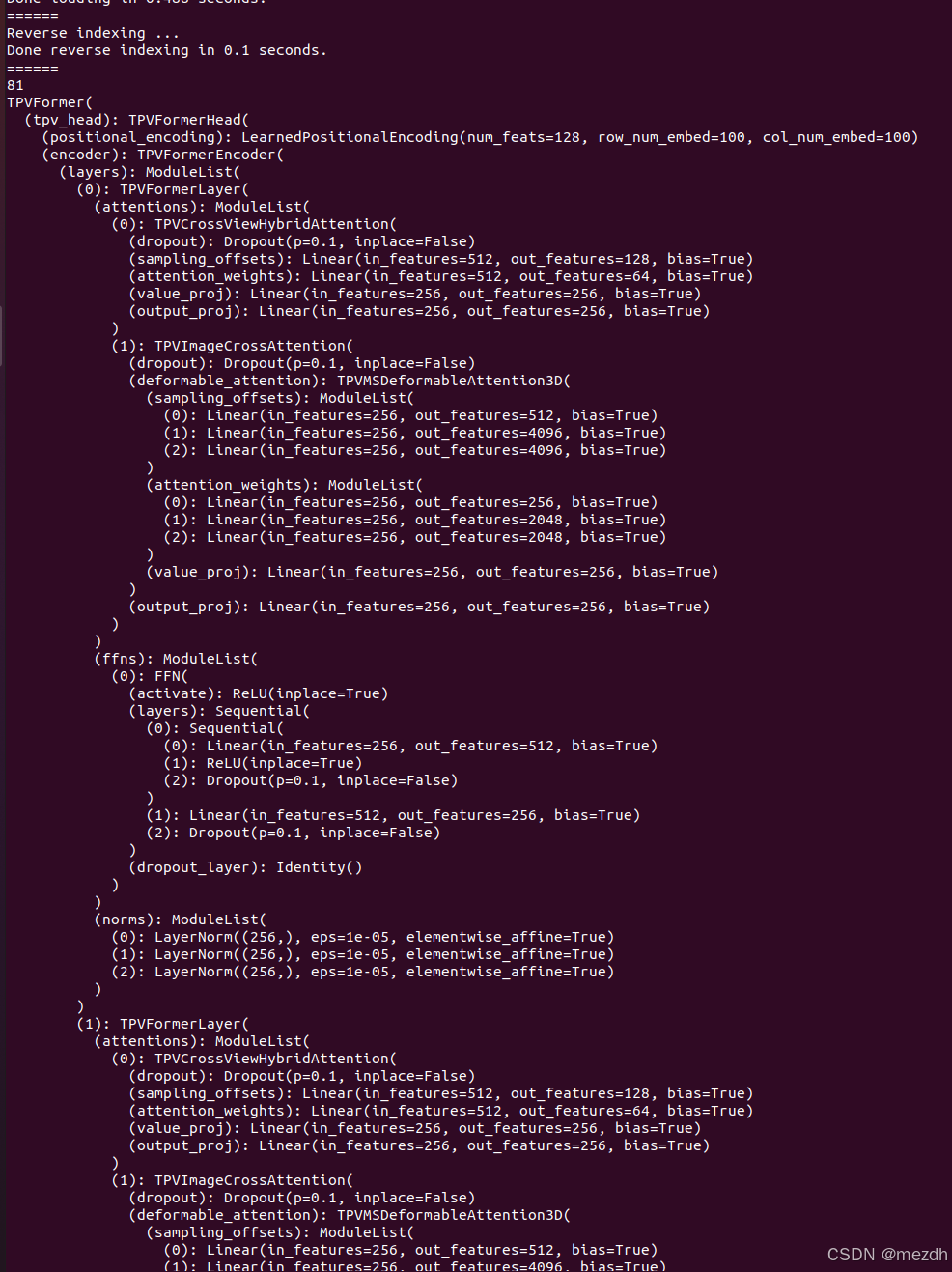
可以找到网络的入口为TPVFormer,:
根据输入要求编写代码对网络进行配置,对数据集进行配置(作者提供的pkl为基于完整数据集,本次复现使用mini数据集,需要修改):
import argparse, torch, os, json
import shutil
import numpy as np
import mmcv
from mmcv import Config
from collections import OrderedDict
def revise_ckpt(state_dict):
tmp_k = list(state_dict.keys())[0]
if tmp_k.startswith('module.'):
state_dict = OrderedDict(
{k[7:]: v for k, v in state_dict.items()})
return state_dict
if __name__ == "__main__":
torch.cuda.empty_cache()
import sys; sys.path.insert(0, os.path.abspath('.'))
device = torch.device('cuda:0')
# device = torch.device('cpu')
## prepare config
parser = argparse.ArgumentParser(description='convert_to_ONNX')
parser.add_argument('--py-config', default='config/tpv04_occupancy.py')
parser.add_argument('--ckpt-path', type=str, default='ckpts/tpv04_occupancy_v2.pth')
parser.add_argument('--frame-idx', type=int, default=0, nargs='+',
help='idx of frame to visualize, the idx corresponds to the order in pkl file.')
cfg = Config.fromfile(args.py_config)
dataset_config = cfg.dataset_params
#配置模型
logger = mmcv.utils.get_logger('mmcv')
logger.setLevel("WARNING")
if cfg.get('occupancy', False):
from builder import tpv_occupancy_builder as model_builder
else:
from builder import tpv_lidarseg_builder as model_builder
my_model = model_builder.build(cfg.model).to(device)
if args.ckpt_path:
ckpt = torch.load(args.ckpt_path, map_location='cpu')
if 'state_dict' in ckpt:
ckpt = ckpt['state_dict']
print(my_model.load_state_dict(revise_ckpt(ckpt)))
my_model.eval()
#配置数据集
from nuscenes import NuScenes
from visualization.dataset import ImagePoint_NuScenes_vis, DatasetWrapper_NuScenes_vis
if args.vis_train:
pkl_path = './data/nuscenes_infos_train_mini.pkl'
else:
pkl_path = './data/nuscenes_infos_val_mini.pkl'
data_path = 'data/nuscenes'
label_mapping = dataset_config['label_mapping']
nusc = NuScenes(version='v1.0-mini', dataroot=data_path, verbose=True)
pt_dataset = ImagePoint_NuScenes_vis(
data_path, imageset=pkl_path,
label_mapping=label_mapping, nusc=nusc)
#输出测试
dataset = DatasetWrapper_NuScenes_vis(
pt_dataset,
grid_size=cfg.grid_size,
fixed_volume_space=dataset_config['fixed_volume_space'],
max_volume_space=dataset_config['max_volume_space'],
min_volume_space=dataset_config['min_volume_space'],
ignore_label=dataset_config["fill_label"],
phase='val'
)
print(len(dataset))
batch_data, filelist, scene_meta, timestamp = dataset[0]
imgs, img_metas, vox_label, grid, pt_label = batch_data
imgs = torch.from_numpy(np.stack([imgs]).astype(np.float32)).to(device)
grid = torch.from_numpy(np.stack([grid]).astype(np.float32)).to(device)
torch_inputs_dict = {'img': imgs, 'img_metas': [img_metas], 'points': grid.clone()}
torch_inputs_tuple=(grid.clone(),[img_metas],imgs)
# with torch.no_grad():
# outputs_vox, outputs_pts = my_model(**torch_inputs)
运行代码无报错,输出正确尺寸的tensor复现完成。
3.格式转化
由于网络包括IF和LOOP需要在转化ONNX前对计算图进行处理,记录trace或者转化为脚本:
traced_cell = torch.jit.trace(my_model, torch_inputs_1)
出现报错:(发现是由于img_metas 中有一些键对应的数值转化发生在模型内部,将其转移到i模型外部进行转化,转化发生在点云对其投影函数point_smaple函数中)
 改变img_metas的值数据类型,并验证转换结果:
改变img_metas的值数据类型,并验证转换结果:
for key, value in img_metas.items():
print(key)
img_metas[key]=torch.from_numpy(np.stack([value]).astype(np.float32)).to(device)
print(img_metas["lidar2img"].shape)
print(img_metas["img_shape"].shape)
再次运行:出现CUDA内存不足报错

关闭梯度再次尝试:
with torch.no_grad():
torch.cuda.empty_cache()
torch.onnx.export(my_model,((grid.clone(),img_metas,imgs)),'model.onnx',input_names=input_names,output_names=output_names,opset_version=11)
出现报错,ONNX未知的数据类型和不支持的算符

 定位问题:
定位问题:
 将torch.maximum改为torch.max。再次运行出现相同类型报错。
将torch.maximum改为torch.max。再次运行出现相同类型报错。
 找到 onnx定义算符的文件,在其中op14中自定义算符
找到 onnx定义算符的文件,在其中op14中自定义算符_nan_to_num
#cunstom
@parse_args("v", "f", "f", "f")
def nan_to_num(g, input, nan, posinf, neginf):
from torch.onnx.symbolic_opset9 import isnan, lt, gt, logical_and
# Cannot create a int type tensor with inf/nan values, so we simply
# return the original tensor
if not sym_help._is_fp(input):
return input
input_dtype = sym_help.pytorch_name_to_type[input.type().scalarType()]
if nan is None:
nan = 0.0
nan_cond = isnan(g, input)
nan_result = g.op("Where", nan_cond,
g.op("Constant", value_t=torch.tensor([nan], dtype=input_dtype)), input)
# For None values of posinf, neginf we use the greatest/lowest finite
# value representable by input’s dtype.
finfo = torch.finfo(input_dtype)
if posinf is None:
posinf = finfo.max
posinf_cond = logical_and(g, isinf(g, nan_result),
gt(g, nan_result, g.op("Constant", value_t=torch.LongTensor([0]))))
nan_posinf_result = g.op("Where", posinf_cond,
g.op("Constant", value_t=torch.tensor([posinf], dtype=input_dtype)), nan_result)
if neginf is None:
neginf = finfo.min
neginf_cond = logical_and(g, isinf(g, nan_posinf_result),
lt(g, nan_posinf_result, g.op("Constant", value_t=torch.LongTensor([0]))))
return g.op("Where", neginf_cond,
g.op("Constant", value_t=torch.tensor([neginf], dtype=input_dtype)), nan_posinf_result)
再次运行遇到grid_smaple缺失的问题,查询文档发现从op16开始支持,需要重新配置pytorch环境


















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











