






 本文介绍了SparkSQL在大数据处理中的核心角色,包括创建结构化数据、使用SQL进行交互式查询,以及DataFrame和DataSet操作的对比。通过实例展示了如何从不同数据源读取数据,执行SQL查询,以及常用的数据操作技巧。
本文介绍了SparkSQL在大数据处理中的核心角色,包括创建结构化数据、使用SQL进行交互式查询,以及DataFrame和DataSet操作的对比。通过实例展示了如何从不同数据源读取数据,执行SQL查询,以及常用的数据操作技巧。
Spark SQL
SparkSQL介绍
Spark SQL是用于结构化数据、半结构化数据处理的Spark高级模块,可用于从各种结构化数据源,例如JSON(半结构化)文件、CSV文件、ORC文件(ORC文件格式是一种Hive的文件存储格式,可以提高Hive表的读、写以及处理数据的性能)、Hive表、Parquest文件(新型列式存储格式,具有降低查询成本、高效压缩等优点,广泛用于大数据存储、分析领域)中读取数据,然后在Spark程序内通过SQL语句对数据进行交互式查询,进而实现数据分析需求,也可通过标准数据库连接器(JDBC/ODBC)连接传统关系型数据库,取出并转化关系数据库表,利用Spark SQL进行数据分析。
从Spark 2.0开始,Spark将DataFrame和DataSet的API融合到一起,提供了结构化的API,即用户可以通过一套标准的API完成对两者的操作。DataSet具有两个不同的API特性:带类型的API(静态类型)和不带类型的API(动态类型)。在概念上,DataFrame视为通用对象DataSet[Row]集合的别名,其中Row是不带类型的Java虚拟机对象,相比之下,DataSet是带类型的Java虚拟机对象集合,数据类型可以由Scala中的案例类定义或由Java中的类指定。由于Python和R语言在编译时类型是动态的,因此只有不带类型的API,即DataFrame,而无法使用DataSet。
Spark SQL可以三种方式操作数据,包括SQL、DataFrame API、DataSet API。如果从静态类型和运行时安全性的限制进行比较,SQL的限制最弱,DataSet API的限制最强。如果在代码中使用SQL语句进行查询,直到运行时才会发现语法错误,所以一般建议通过交互方式执行,而通过DataFrame和DataSet编程的方式,可以在编译时发现和捕获语法错误,所以编写应用代码时节省了开发人员的时间和成本。

创建结构化数据
Spark中所有功能的入口点是SparkSession。当启动spark-shell时,系统会自动启动一个SparkSession实例Spark,我们可以在创建DataFrame和DataSet时直接通过Spark调用其中的方法。从Spark 2.0开始,SparkSession提供了Hive功能的内置支持,包括使用HiveQL编写查询,访问Hive UDF以及从Hive表读取数据的功能。要使用这些功能,不需要具有现有的Hive设置。使用SparkSession,应用程序可以从现有的RDD、Hive表或Spark数据源创建DataFrame。
// 使用java.io对象生成json测试文件
import java.io._
import org.apache.spark.sql.SparkSession
// 创建sparkSession对象
val spark = SparkSession.builder()
.appName("sparkSQL")
.enableHiveSupport() // 如果是读hive表,添加hive支持
.getOrCreate() // get或者新建
// 创建测试文件:json_file.json
val writer = new PrintWriter(new File("json_file.json"))
writer.write("[{\"name\":\"bob\",\"age\":18},{\"name\":\"alice\",\"age\":116}]")
writer.close()
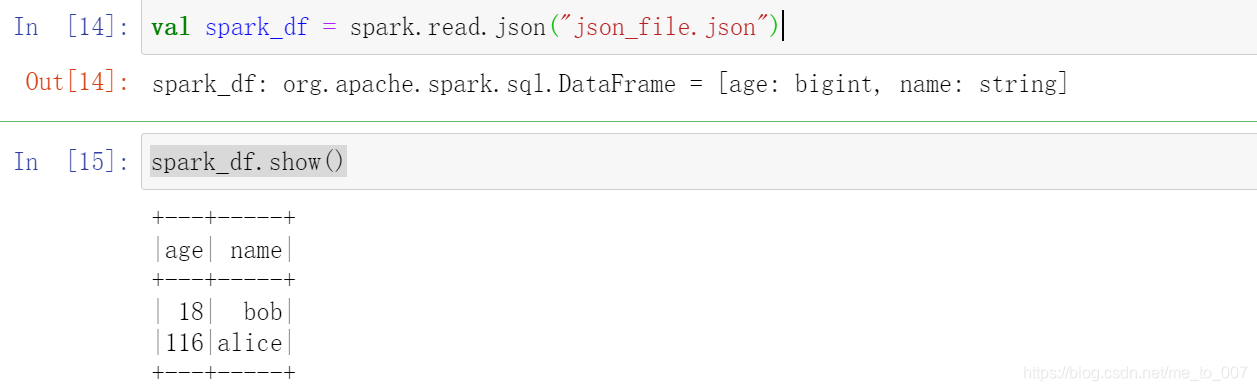
val spark_df = spark.read.json("json_file.json") // 返回DataFrame
spark_df.show()
// df结构信息,没有参数方法可以不带括号
spark_df.printSchema
使用SQL查询
def sql(sqlText : root.scala.Predef.String) : org.apache.spark.sql.DataFrame
spark.sql方法可以通过写sql查询返回DataFrame,查询的表需注册成临时表;
Spark SQL中的本地临时视图是基于会话范围的,如果创建它的会话终止,其也将消失。如果要在所有会话之间共享临时视图,并保持活动状态,直到Spark应用程序终止,可以创建一个全局临时视图。全局临时视图与系统保留的数据库global_temp绑定,必须使用global_temp限定名称引用它,例如SELECT∗FROMglobal_temp.spark_df。
sparkDF.createOrReplaceTempView("tbname")
spark.sql("select * from tbname")
// 注册全局临时表
sparkDF.createGlobalTempView("global_tbname")
spark.sql("select * from global_temp.tbname")
创建DataSet
Spark SQL的Scala接口支持自动将包含案例类的RDD转换为DataFrame。案例类定义了表的架构。案例类的参数名称通过反射机制读取,并成为列的名称。案例类也可以嵌套或包含复杂类型,例如Seqs或Arrays。可以将该RDD隐式转换为DataFrame,然后将其注册为表,可以在后续的SQL语句中使用。
// 创建样本类
case class Person(name:String,age:Long)
// 样本类反射推断创建DS
val caseClassDS = Seq(Person("bob",15)).toDS()
// 也可以使用Seq.toDS,字段名是_1,_2,_3
val seqDS = Seq((1,2,3)).toDS()
// 通过json创建ds
val jsonDS = spark.read.json("json_file.json").as[Person]
// 查看ds表结构
jsonDS.printSchema
// 通过rdd创建DataFrame
val rddDF = spark.sparkContext
.textFile("text_file.txt") // 读取txt文件
.map(_.split(",")) // 逗号分隔
.map(e -> Person(e(0),e(1).trim.toInt()) // 剔除空格,转化成int类型
.toDF() // rdd转化成DataFrame
rddDF.createOrReplaceTempView("rdd_tbname") // 注册临时表
val sparkDF = spark.sql("select name,age from rdd_tbname") // 使用spark.sql查询
常见的Spark SQL结构化数据操作
| 函数 描述 | |
|---|---|
| select | 类似于sql的select操作,选择一个或者多个列,可以对列进行变换投影map |
| selectExpr | 执行投影时支持强大的sql表达式对列进行转化 |
| filter | 和where相同,看使用习惯 |
| where | 类似sql中的where过滤记录行 |
| distinct/dropDuplicates | 从DataFrame中删除重复的行,distinct全字段去重 |
| sort/orderBy | 根据列对DataFrame进行排序 |
| limit | 获取前n行返回DF |
| union | 合并两个DF返回新的DF |
| withColumn | 用户在DF中添加新列或替换现有列 |
| withColumnRenamed | 列重命名 |
| drop | 从DF中删除一列或多列,如果指定的列名不存在,则不执行任何操作 |
| sample | 根据给定的参数随机选择 |
| randomSplit | 根据给定的权重将DF分为一个或者多个DF,在机器学习模型训练过程中,通常用于将数据集分为训练集和测试集 |
| join | 类似于sql的join,内连接,左连杰,右连接,全连接,交叉连接 |
| groupBy | 类似于sql的groupby ,返回groupby结构 |
| describe | 计算有关DF中的数字列和字符串列的通用统计信息,比如计数、平均值、标准差、最小值、最大值、任意近似的百分数 |

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









