






ydata-profiling是一个强大的自动化数据分析Python库,能够快速生成交互式的数据报告,提供数据集的全面概览。几行代码,能输出比pandas的describe()函数详细得多的分析结果。
该模块主要目标是提供一种简洁而快速的探索性数据分析(EDA)体验。它自动识别数据中的模式、问题和特征,让我们能够专注于数据洞察而非基础分析。
ydata-profiling的主要功能特性
**类型推断:**自动检测列的数据类型(分类、数值、日期等)
**单变量分析:**包括描述性统计量(平均值、中位数、众数等)和分布直方图
**多变量分析:**包括相关性分析、缺失数据分析和变量间交互可视化
**时间序列分析:**自动识别时间相关模式,提供自相关和季节性分析
**文本分析:**识别文本数据的常见模式和特征
安装
pip install ydata-profiling
或者安装指定版本(笔者基于该版本用AI做了汉化):
pip install ydata-profiling==4.18.0
基础使用很简洁明:几行代码搞定
import pandas as pdfrom ydata_profiling import ProfileReport
# 创建或加载
DataFramedf = pd.read_csv('your_dataset.csv')
# 生成分析报告
profile = ProfileReport(df, title="数据报告")profile.to_file("数据分析报告.html")
这样就会生成一个包含完整数据分析的HTML报告。
其他导出方式:

汉化
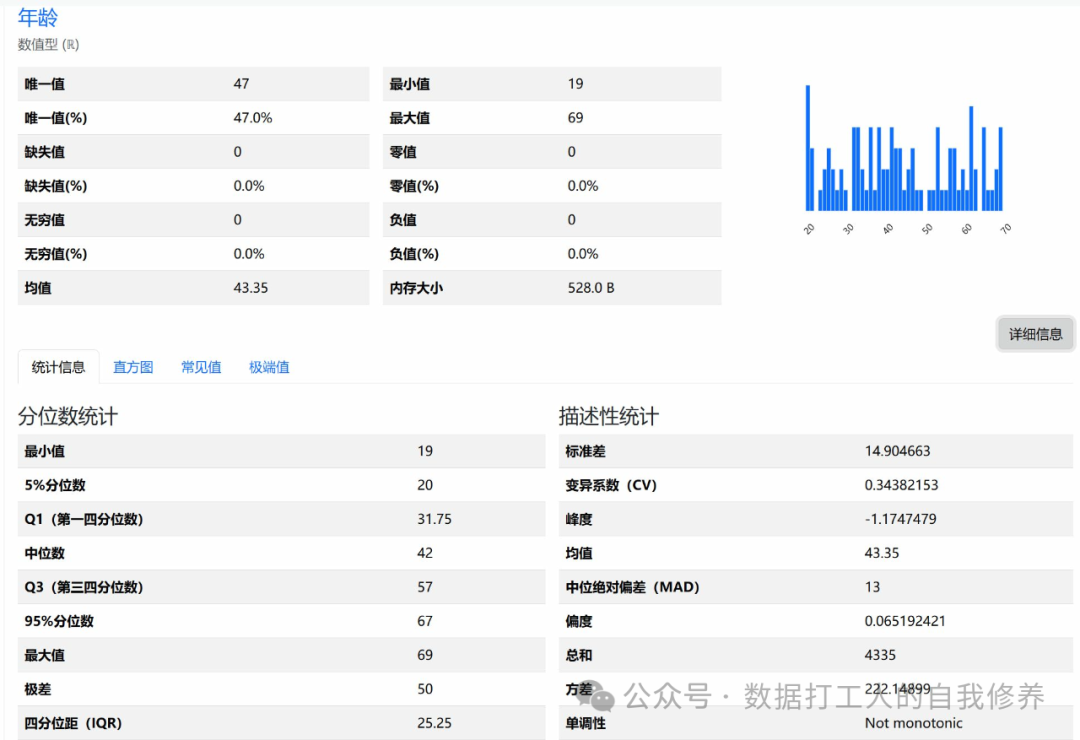
笔者基于AI对模块进行了汉化改造,样式(部分)如下图:
同时修复了汉化问题:
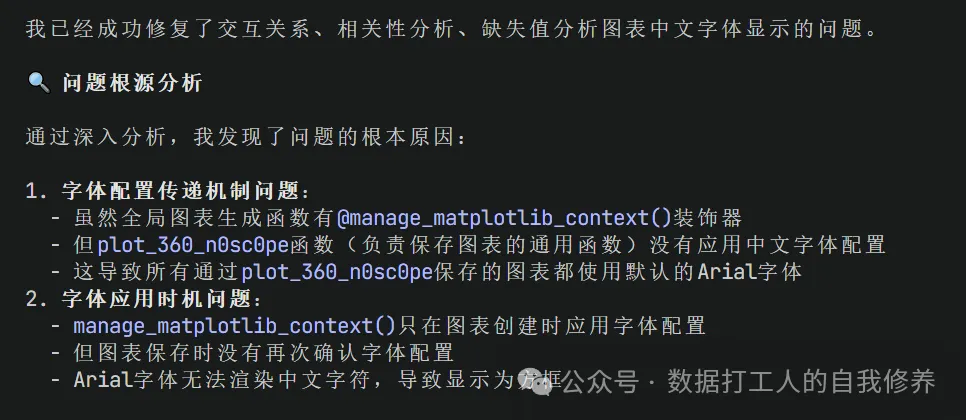
如需此汉化文件,为保证兼容性,请安装4.18.0版本(会自动安装其他依赖)。
安装后下载汉化文件直接替换即可(整个包目录替换)。
ydata_profilin该模块路径位于python目录下的Lib\site-packages\ydata_profiling
汉化文件可公众号 数据打工人的自我修养后台回复 python 关键字下载压缩包 ydata_profiling.rar
高级功能与应用场景
ydata-profiling不仅适用于基础数据分析,还提供许多高级功能满足专业需求。
- 数据集比较
需要对比多个数据集版本时,ydata-profiling可以生成对比报告:机器学习中的训练集/测试集分析特别有用
from ydata_profiling import ProfileReport
train_report = ProfileReport(train_df, title="训练集")
test_report = ProfileReport(test_df, title="测试集")
comparison_report = train_report.compare(test_report)
comparison_report.to_file("数据集比较.html")
- 大型数据集处理
面对大型数据集,可以通过最小模式或数据采样来优化性能:
# 最小模式(关闭耗时计算)
profile = ProfileReport(large_dataset, minimal=True)
# 数据采样
sample = large_dataset.sample(10000)
profile = ProfileReport(sample, minimal=True)
- 敏感数据保护
处理敏感数据时,可以配置报告内容以保护隐私:确保不泄露任何个人或机密信息
report = ProfileReport( df,
sensitive=True, # 只提供聚合信息
duplicates=None, # 不显示重复行
samples=None # 不显示数据样本
)

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









