







羽婕的毕设需要使用MASR模型进行训练,所以这里出一系列MASR模型的实践文章,希望对大家有帮助。本篇文章主要介绍以下4个部分:
目录
MASR环境安装
看羽婕的这篇 服务器部署MASR模型就好啦~
上传数据集
在MASR项目中,数据集的存放位置为dataset文件夹,所以要将数据集上传到dataset目录下。
羽婕使用的是ATCOSIM陆空对话数据集,获取请看陆空对话数据集(毕业设计数据集选取)_陆空通话数据集-优快云博客。
仍然使用FileZilla文件传输工具:
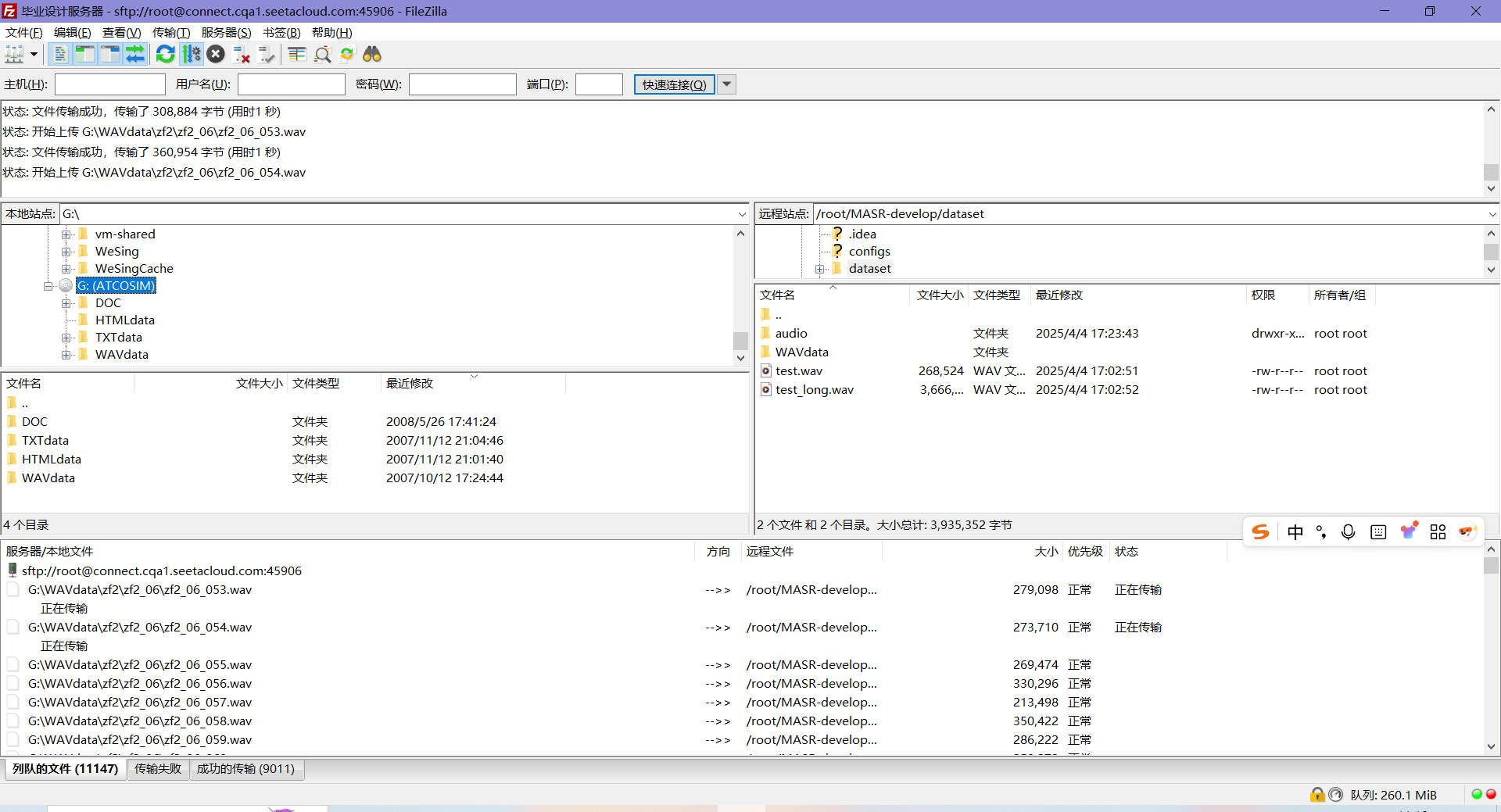
传输完成会显示:

处理数据集(处理成与MASR模型要求一致的结构)
【目标】将ATCOSIM数据集里的音频文件和标注文件分别放到同一个文件夹里。
原始下载的ATCOSIM数据集的文件结构是这样的:
WAVdata/ # 存放所有WAV文件,3层
├── gf1/
│ ├── gf1_01
│ │ ├── gf1_01_001.wav
│ │ └── ...
└── gm1/
│ ├── gm1_01
│ │ ├── gm1_01_001.wav
│ │ └── ...
TXTdata/ # 存放所有TXT文件,3层
├── gf1/
│ ├── gf1_01
│ │ ├── gf1_01_001.txt
│ │ └── ...
└── gm1/
│ ├── gm1_01
│ │ ├── gm1_01_001.txt
│ │ └── ...为了满足MASR训练的要求,即都是1层文件夹,于是羽婕将ATCOSIM数据集上传至服务器端后,先处理了一下数据集,使数据集文件夹变为只有WAV原始文件夹A和TXT标注文件夹B,且A,B文件夹下是直接放文件的,不再有文件夹的结构,即
dataset/
├── audio/ # 存放所有WAV文件,1层
│ ├── 1.wav
│ ├── 2.wav
│ └── ...
└── annotatin/ # 存放所有TXT标注,1层
├── 1.txt
├── 2.txt
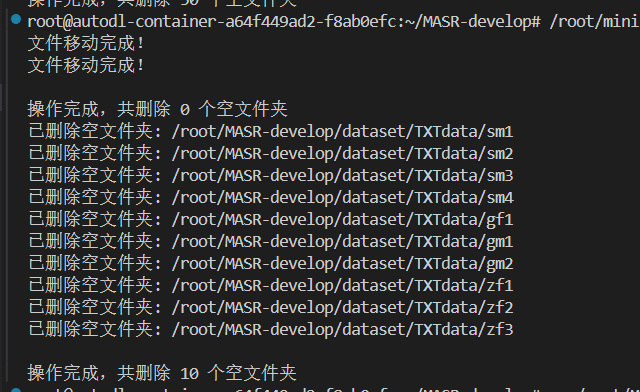
└── ...具体操作是建立ATCOSIM_moving.py脚本,放到了MASR-develop/dataset/ATCOSIM_moving.py目录下,并删除剩下的空文件夹:
# 处理数据集脚本,将多层文件结构改为1层,并删除空文件夹(需要运行2次才能彻底删除文件夹,请实时检查)
import os # 提供操作系统相关功能,如文件路径操作
import shutil # 提供高级文件操作功能,如文件移动
def move_files_to_root(root_folder):
"""
将root_folder下所有子文件夹中的文件移动到root_folder中
"""
for foldername, subfolders, filenames in os.walk(root_folder):
if foldername == root_folder: # 跳过根目录本身
continue
for filename in filenames:
src_path = os.path.join(foldername, filename) # 原始路径
dst_path = os.path.join(root_folder, filename) # 目标路径
counter = 1
while os.path.exists(dst_path): # 处理文件名冲突
name, ext = os.path.splitext(filename) # 先分离文件的命名和格式后缀
dst_path = os.path.join(root_folder, f"{name}_{counter}{ext}")
counter += 1 # 加入数字后拼凑
shutil.move(src_path, dst_path) # 文件移动
print(f"Moved: {src_path} -> {dst_path}") # 打印改变
print("文件移动完成!")
def remove_empty_folders(root_folder):
"""
递归删除root_folder下的所有空文件夹
"""
deleted = set()
# 自底向上遍历文件夹(先处理子文件夹)
for foldername, subfolders, filenames in os.walk(root_folder, topdown=False):
# 跳过根目录本身(可选,如需要删除根目录当它为空时可移除这个判断)
if foldername == root_folder:
continue
# 如果当前文件夹为空
if not subfolders and not filenames:
try:
os.rmdir(foldername)
deleted.add(foldername)
print(f"已删除空文件夹: {foldername}")
except OSError as e:
print(f"删除失败: {foldername} - {e}")
print(f"\n操作完成,共删除 {len(deleted)} 个空文件夹")
return deleted
root_folder1 = "/root/MASR-develop/dataset/WAVdata" # 这里替换为你的root文件夹的实际路径
move_files_to_root(root_folder1)
root_folder2 = "/root/MASR-develop/dataset/TXTdata" # 分别处理音频文件夹和标注文件夹
move_files_to_root(root_folder2)
folder_A = "/root/MASR-develop/dataset/WAVdata" # 这里替换为你想要遍历空文件夹的root文件夹路径
remove_empty_folders(folder_A)
folder_B = "/root/MASR-develop/dataset/TXTdata"
remove_empty_folders(folder_B)处理结果:
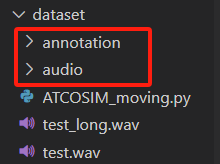
同时为了代码能更好地找到文件夹,将WAVdata文件夹更名为audio,将TXTdata更名为annotation:
mv /root/MASR-develop/dataset/WAVdata /root/MASR-develop/dataset/audio
mv /root/MASR-develop/dataset/TXTdata /root/MASR-develop/dataset/annotation处理结果:
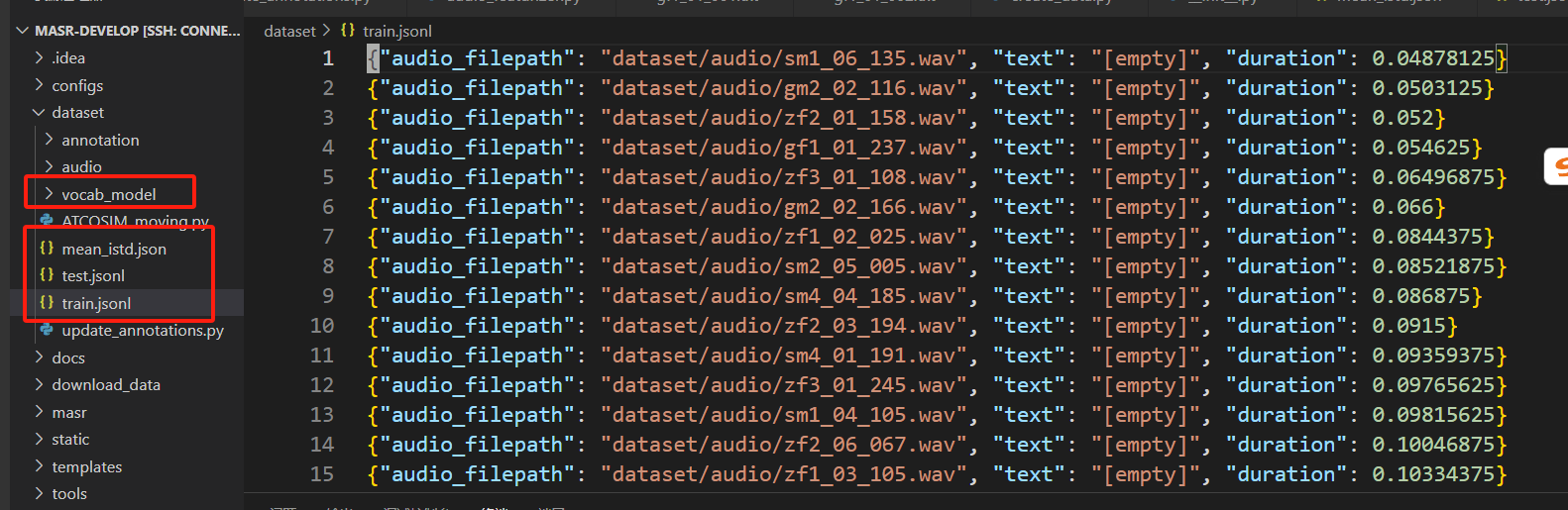
执行create_data.py程序,执行完成之后检查是否在dataset目录下生成了test.jsonl、train.jsonl、mean_istd.json、vocab_model/这四个文件,并确定里面已经包含数据。然后才能往下执行开始训练。
羽婕这里在执行create_data.py程序时遇到了一些问题:
File "/root/MASR-develop/masr/data_utils/normalizer.py", line 76, in compute_mean_istd for i in range(len(means)): ^^^^ TypeError: object of type 'NoneType' has no len()
发现没有正确生成jsonl文件,如下:
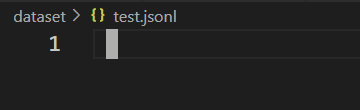
再翻看官方文档,发现其要求的标注文件格式是:
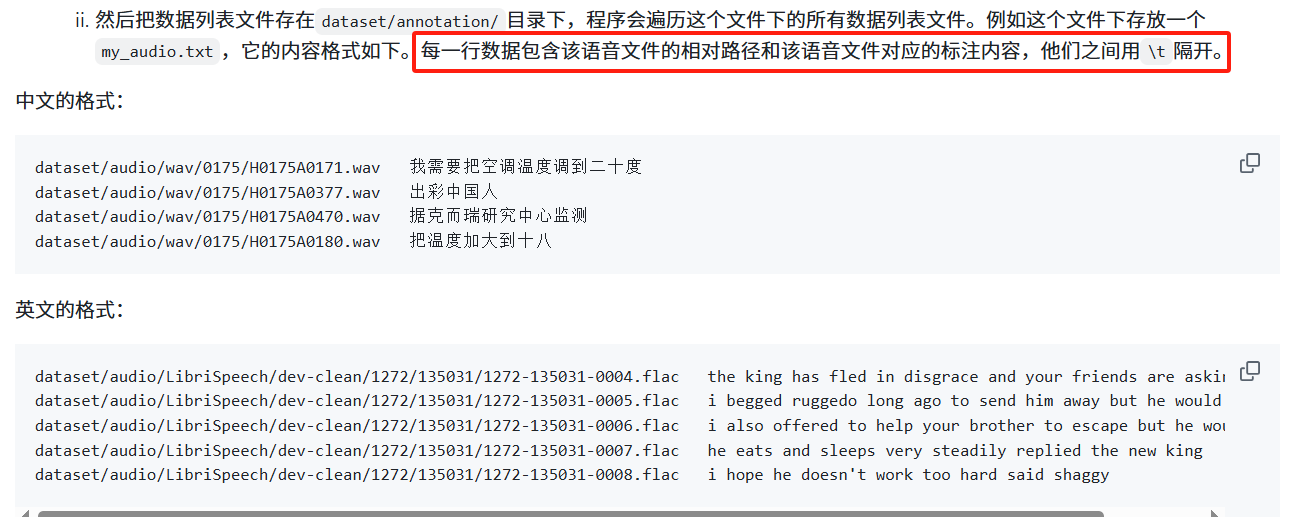
而我的数据集ATCOSIM的TXT标注文件里只有标注文字,没有音频路径和\t,于是我决定处理数据集:建立update_annotations.py文件,放在dataset目录下,文件内容如下:
import os
# 设置路径
audio_dir = 'dataset/audio' # 音频文件夹路径
annotation_dir = 'dataset/annotation' # 标注文件夹路径
def update_annotation_files():
# 遍历annotation目录下的所有TXT文件
for txt_file in os.listdir(annotation_dir):
if txt_file.endswith('.txt'):
# 获取文件名(不带扩展名)
base_name = os.path.splitext(txt_file)[0]
# 构建对应的音频文件路径
audio_path = os.path.join(audio_dir, f"{base_name}.wav")
# 读取原始文本内容
txt_path = os.path.join(annotation_dir, txt_file)
with open(txt_path, 'r', encoding='utf-8') as f:
original_text = f.read().strip()
# 写入新格式内容:音频路径\t文本
with open(txt_path, 'w', encoding='utf-8') as f:
f.write(f"{audio_path}\t{original_text}")
print(f"已更新: {txt_file}")
if __name__ == "__main__":
# 检查目录是否存在
if not os.path.exists(audio_dir):
print(f"错误: 音频目录 '{audio_dir}' 不存在")
elif not os.path.exists(annotation_dir):
print(f"错误: 标注目录 '{annotation_dir}' 不存在")
else:
update_annotation_files()
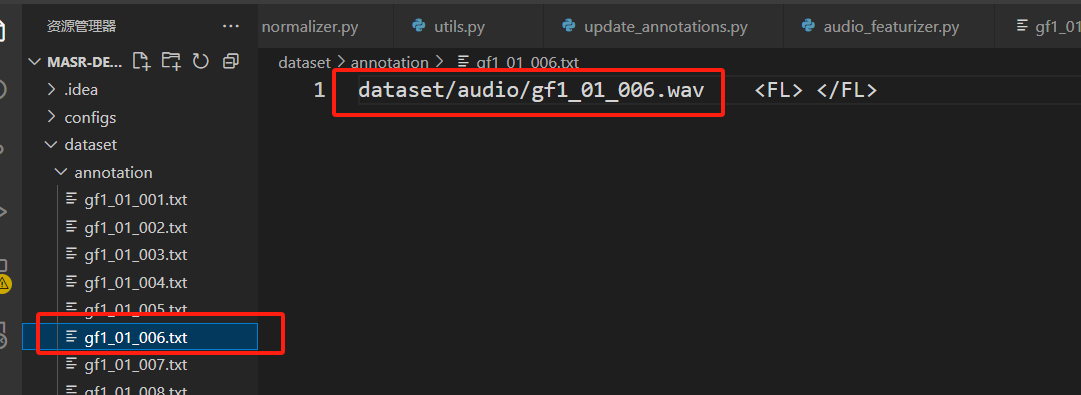
print("所有标注文件已更新完成!")执行完后,可以发现红框中的部分可以对应,满足annotation文件要求:
再次运行create_data.py代码:
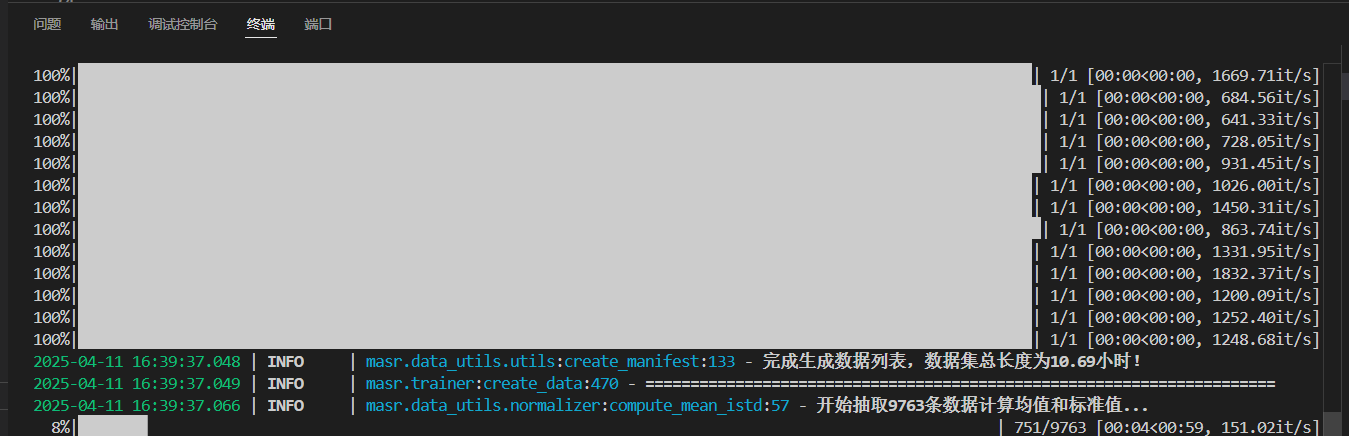
跑起来了,yes!!!到此jsonl文件(训练和测试数据列表)成功生成:
但在生成数据字典的过程中报了错:
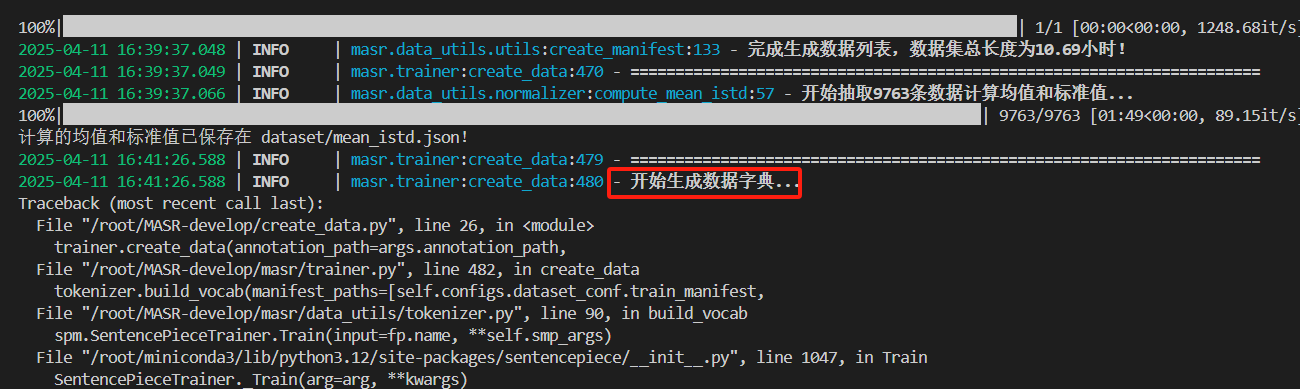
RuntimeError: Internal: src/trainer_interface.cc(662) [(trainer_spec_.vocab_size()) == (model_proto->pieces_size())] Vocabulary size too high (5000). Please set it to a value <= 879.
仔细阅读报错信息,发现是vocab size这个参数太大了,要将它减小到<=879。因此由报错信息中的masr/trainer.py文件我锁定了第481行的第2个参数,即self.configs.tokenizer_conf,由configs/conformer.yml看到了tokenizer_conf这个参数被设置为了5000,为了满足要求,我们把它设置为800。
继续重新执行create_data.py:
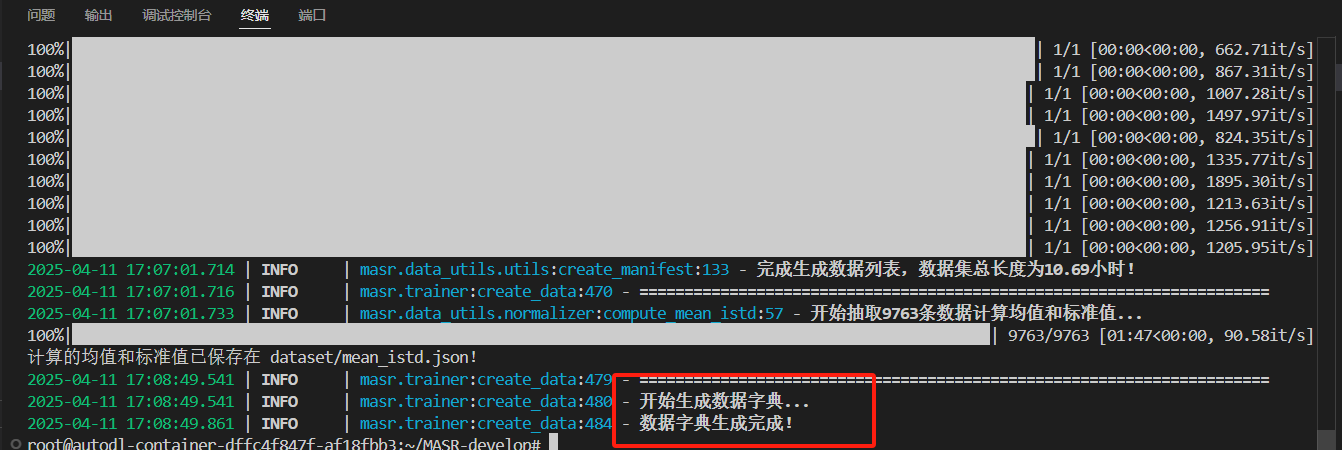
到此数据集处理完啦,马上可以跑通模型了。
跑通模型
开始训练语音识别模型,详细参数请查看configs下的配置文件。每训练一轮和每10000个batch都会保存一次模型,模型保存在models/<use_model>_<feature_method>/epoch_*/目录下,默认会使用数据增强训练。
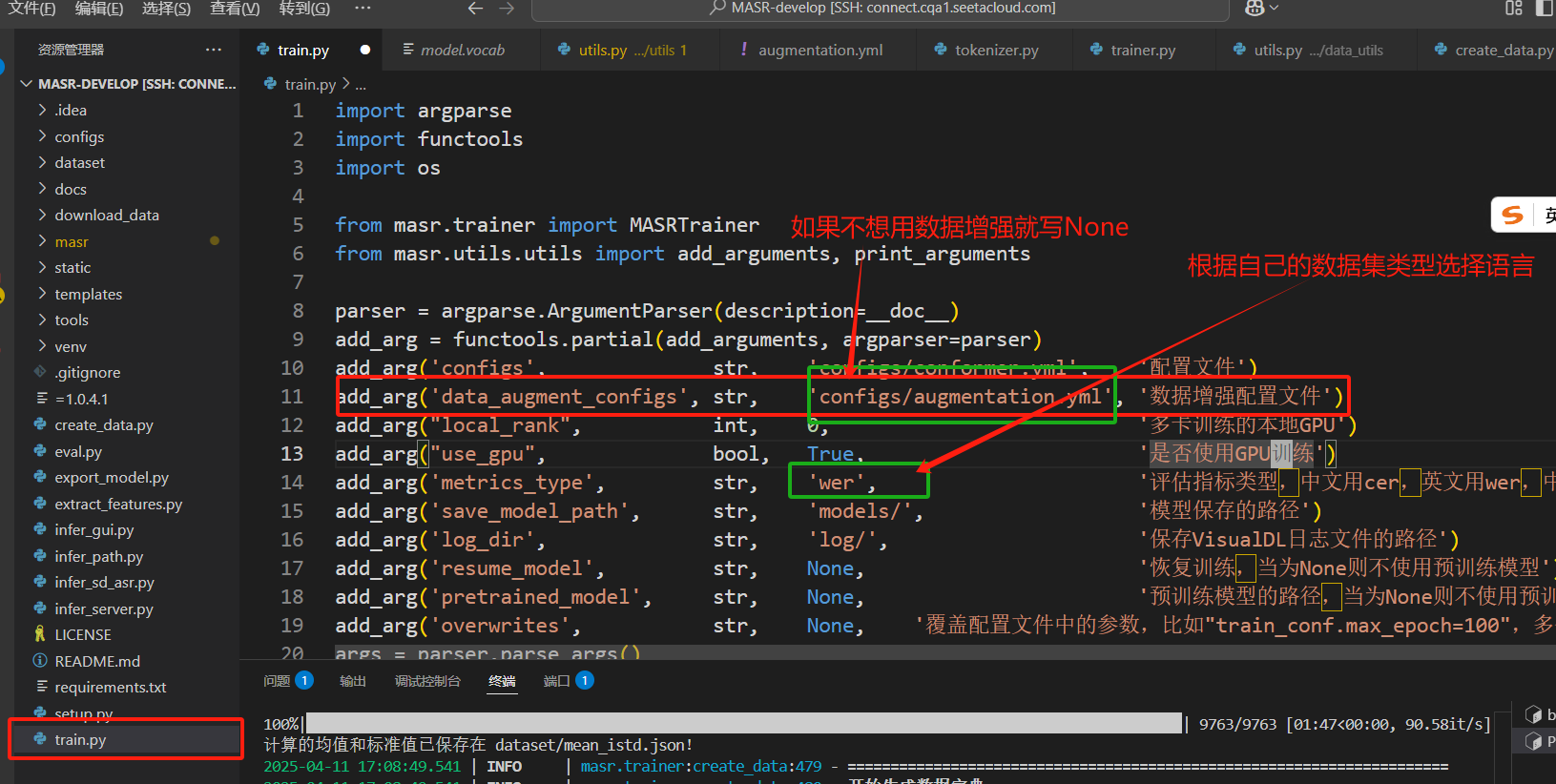
如何不想使用数据增强,只需要将参数data_augment_configs设置为None即可。这里羽婕使用了语音增强。
将train.py中的metrics_type参数改为wer,表示评价指标类型是英语。
最好把train.py文件里的路径全改为绝对路径,像羽婕这样:


执行完这些操作后,羽婕开了一个screen窗口,原因及具体操作具体可看羽婕的这篇笔记:
如果在screen模式下不能查看历史 记录,可以使用
Ctrl+a+[ # 使用这个命令进入光标模式,用上下键或滚轮查看历史
Ctrl+c # 退出光标模式
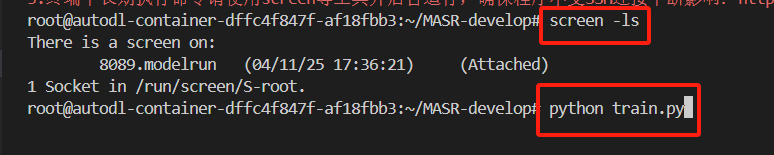
程序成功跑起来了:
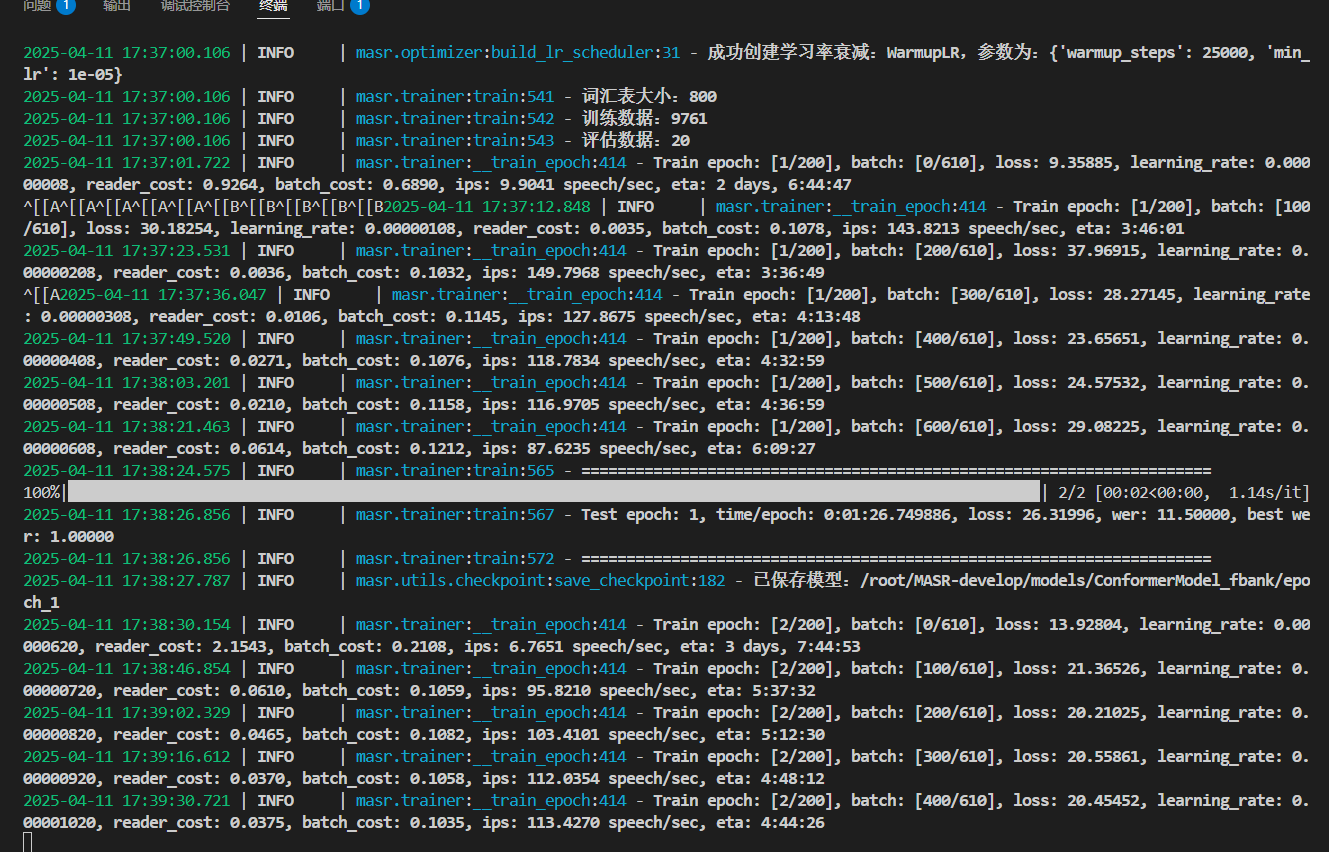
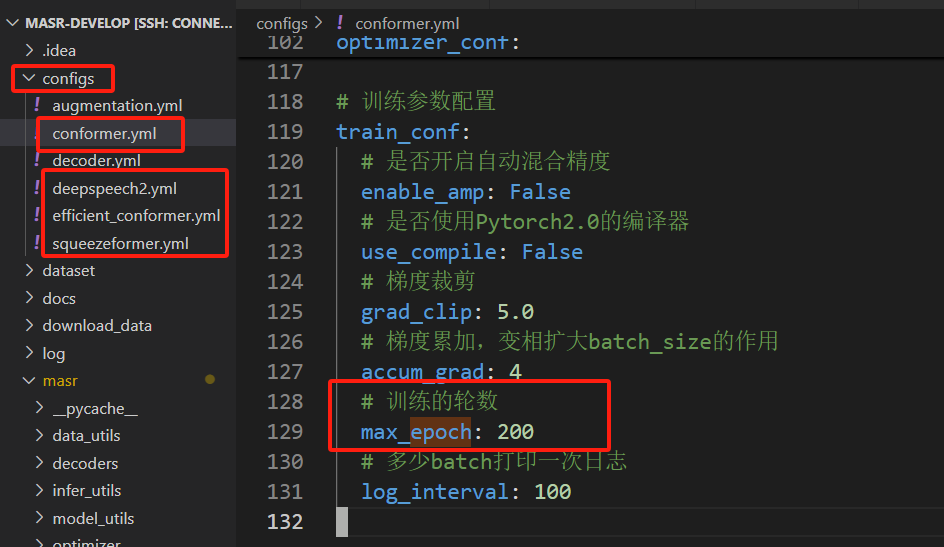
如果不想跑200个epoch,可以在configs目录里改epoch的大小:

















 2131
2131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









