







 该文章介绍了一个使用Python的requests和BeautifulSoup库来爬取京东商品信息的程序。程序通过多线程加速爬取,每页抓取80个商品,结果存储到Excel文件。作者提醒由于频繁爬取可能导致IP被封,并提供了将Python脚本打包成.exe文件的方法。
该文章介绍了一个使用Python的requests和BeautifulSoup库来爬取京东商品信息的程序。程序通过多线程加速爬取,每页抓取80个商品,结果存储到Excel文件。作者提醒由于频繁爬取可能导致IP被封,并提供了将Python脚本打包成.exe文件的方法。
目录
前言:
在此只是想学习一下BS4对网页解码,对某东商品进行一个爬取,仅供学习使用。
整体页面展示:
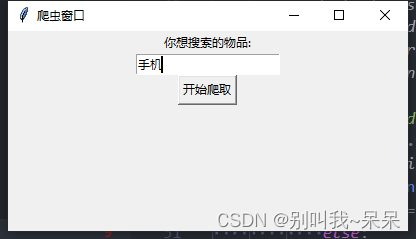
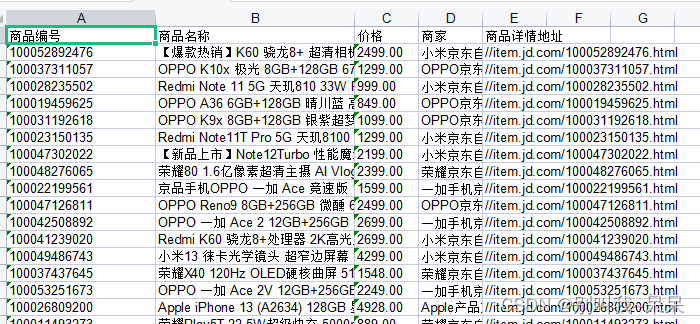
代码思路:
整体使用requests模块,把某东的搜索框作为一个加载页面,我们从窗体文件中为他传入一个关键词,把这个关键词作为某东搜索网址里搜索的keyword,我设的爬取范围是搜索商品自初始页面往后的600件商品,在这个某东的网页很神奇,因为有些商品你虽然在这个爬去中看到了,但是你拿着编号去页面搜索的时候却看不到,每一页有60+左边20=80个商品展示。为了增加爬取的速度我是用了多线程,总共大约18个,但速度快带来的代价就是我总共没使用几次,我的IP就封掉了,所以大家学习一下就行,别给人家添麻烦了,哈哈。代码里面我基本上都给了注释。有什么宝贵的意见建议的可以评论或者私信我,我们可以一块学习。
import tkinter as tk
import threading
from bs4 import BeautifulSoup
import requests
import xlwt
import tkinter.messagebox as ms
def get_html(url, headers):
print("--> 正在获取网站信息,请稍等30S,完成后会有提示")
response = requests.get(url, headers=headers)
if response.status_code == 200:
html = response.text
return html
else:
print("获取网站信息失败!")
response.close
def crawl_data(keyword):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53'}
# 创建workbook,就是创建一个Excel文档
write_work = xlwt.Workbook(encoding='ascii')
# 添加一张单
write_sheet = write_work.add_sheet("sheet1")
# 创建表头
write_sheet.write(0, 0, label='商品编号')
write_sheet.write(0, 1, label='商品名称')
write_sheet.write(0, 2, label='价格')
write_sheet.write(0, 3, label='商家')
write_sheet.write(0, 4, label='商品详情地址')
# 记录当前行数
_current_row = 0
for k in range(0, 20):
i = 1+k*2
j = 80+k*60
search_url= 'https://search.jd.com/Search?keyword=%s&suggest=1.his.0.0&wq=AJ1&pvid=65892364c2604d5897754ab21bed6d22&page=%d&s=%d&click=1'%(keyword,i,j)
html = get_html(search_url, headers)
soup = BeautifulSoup(html, 'lxml')
goods_list = soup.find_all('li', class_='gl-item')
for li in goods_list:
_current_row += 1
if _current_row == 29:
break
no = li['data-sku']
name = li.find(class_='p-name p-name-type-2').find('em').get_text()
price = li.find(class_='p-price').find('i').get_text()
if (li.find(class_='p-shop').find('a') != None):
shop = li.find(class_='p-shop').find('a').get_text()
else:
shop = None
print('='*10, '第二组', '='*10, "No: ", no, 'Name: ', name, "Price: ", price, 'Shop: ', shop)
detail_addr = li.find(class_='p-name p-name-type-2').find('a')['href']
# 写入Excel
write_sheet.write(_current_row, 0, label=no)
write_sheet.write(_current_row, 1, label=name)
write_sheet.write(_current_row, 2, label=price)
write_sheet.write(_current_row, 3, label=shop)
write_sheet.write(_current_row, 4, label=detail_addr)
# 保存文件
file_name="./"+keyword+"爬取结果.xls"
write_work.save(file_name)
ms.showinfo("提示", "爬取完成,请关闭所有运行框后再打开文件")
def crawl_with_gui():
def crawl_thread():
# 获取关键字
keyword = keyword_entry.get()
crawl_thread = threading.Thread(target=crawl_data, args=[keyword])
crawl_thread.start()
# 创建window
window = tk.Tk()
window.title("爬虫窗口")
window.geometry("400x200")
# 标签
keyword_label = tk.Label(window, text="你想搜索的物品:")
keyword_label.pack()
# 输入框
keyword_entry = tk.Entry(window)
keyword_entry.pack()
# 按钮
crawl_button = tk.Button(window, text="开始爬取", command=crawl_thread)
crawl_button.pack()
window.mainloop()
if __name__ == '__main__':
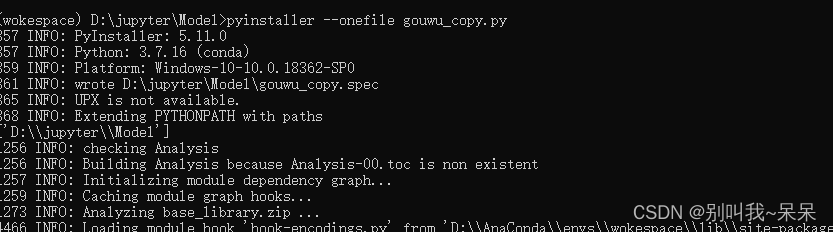
crawl_with_gui()生成便于其计算机执行的.exe文件过程:
我是使用的Anaconda Prompt,进入到自己的工作环境
![]()
然后再进入到你程序所在的目录下

执行pyinstaller --onefile you_filename.py,后面这个替换成你自己的文件名,可能过程会长一点,但是一会就好了,在你的目录下会生成一些列的配置文件,在dist文件下就会有一个.exe可以把这个发给你的好朋友,这样他也可以爬取一些自己想要的东西了。
当然前提是你已经安装了pyinstaller的包,
若是没有就在你的工作环境下pip install pyinstaller



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











