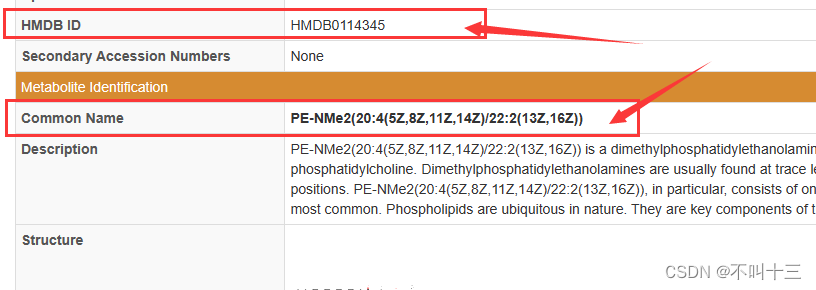
 Python脚本:使用INCHIKEY从HumanMetabolomeDatabase抓取HMDBID与CommonName(处理网络不稳定)
Python脚本:使用INCHIKEY从HumanMetabolomeDatabase抓取HMDBID与CommonName(处理网络不稳定)




 本文介绍了一个Python程序,用于从HumanMetabolomeDatabase网站通过Formula和INCHIKEY查找对应的HMDBID和CommonName。程序处理了网站的不稳定性,并指导用户如何使用CSV文件和处理网络请求超时问题。
本文介绍了一个Python程序,用于从HumanMetabolomeDatabase网站通过Formula和INCHIKEY查找对应的HMDBID和CommonName。程序处理了网站的不稳定性,并指导用户如何使用CSV文件和处理网络请求超时问题。
从网站Human Metabolome Database里匹配Formula找对应的INCHIKEY,获取对应HMDB ID,Common Name
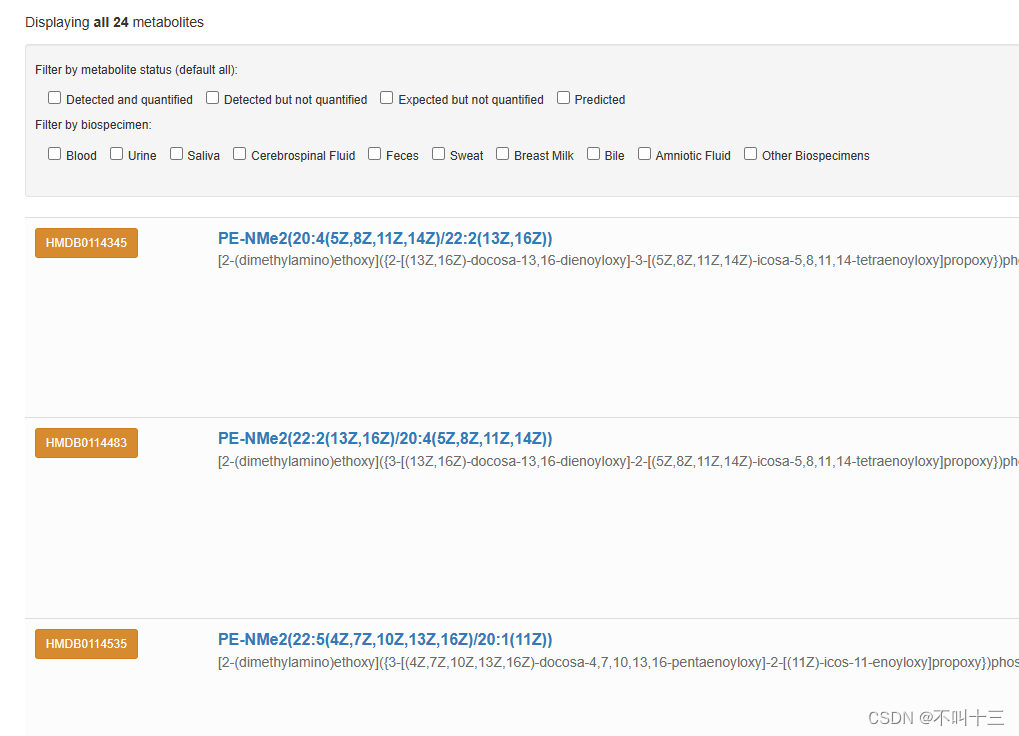
使用说明:
因为这个程序需要提交的网站不是很稳定,大部分问题在解决查询回拨这一部分了,所以功能不是很完善,可以直接把压缩文件直接解压到Dp
第一步:(这部分的名字不可以改变)在D盘下创建一个文件夹“PythonDemo”,从“PythonDemo”里创建一个子文件夹“HMDB_csv”。
第二步:在这个文件夹下把你的只含有Formula和INCHIKEY的csv文件数据复制到文件夹“HMDB_csv”
形如这个样子:这两个标题头必须要有。
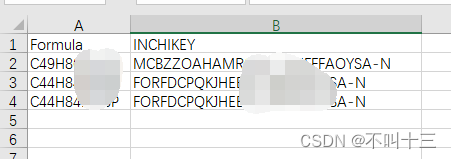
数据csv文件名字随便起,最好是英文+数字,这个只要自己区分就行。该文件夹下可以有多个的csv待搜索文件,你可以一份数据创建一个csv放在里面,程序自动匹配该文件夹下的所有CSV,等程序结束后及时移除匹配完成的数据,不然下次程序运行会再匹配一遍。
可以同时有好几个数据逐个的匹配,只要起的名字自己区分开就行:如下图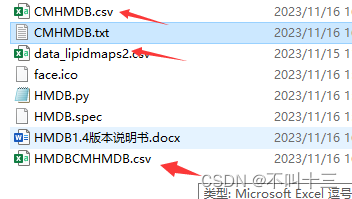
运行程序:HMDB.exe![]()
若打开长时间没动则敲一下回车键

结束后会产生一个与CSV对应的TXT,里面内容如下:
对应的分别是Formula、INCHIKEY、HMDB ID、Common Name
如果只有Formula、INCHIKEY则说明在网站中并未找到与INCHIKEY相同的Formula项。
但是要注意:

若是结果中出现了这样的,则说明这条数据因网络波动搜索失败,需要重新的搜索,可以吧CSV里的其他数据删除,只留下需要重新提交的数据,
结果使用小技巧:
可以按照上一篇文章中介绍的使用导入和公式进行筛选,但是这里在导入数据的时候需要进行一步拆分操作,“数据”选项卡“分列”,分隔符是英文状态下的单引号 ' ,

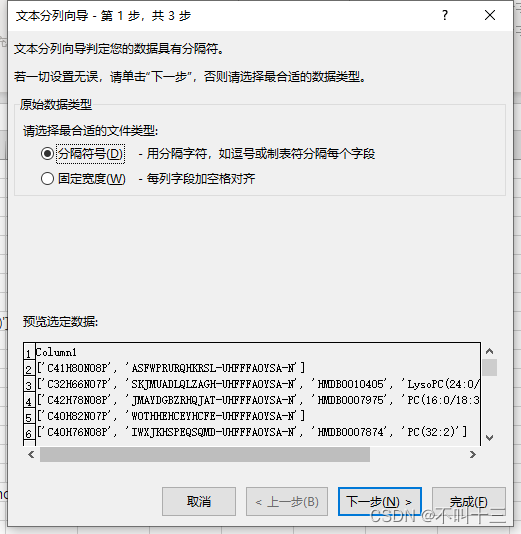
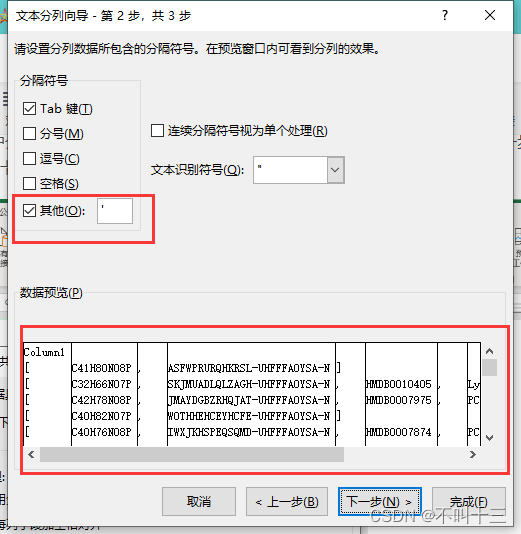
分完之后大概率张这个样子,然后自己把没用的列删除了就行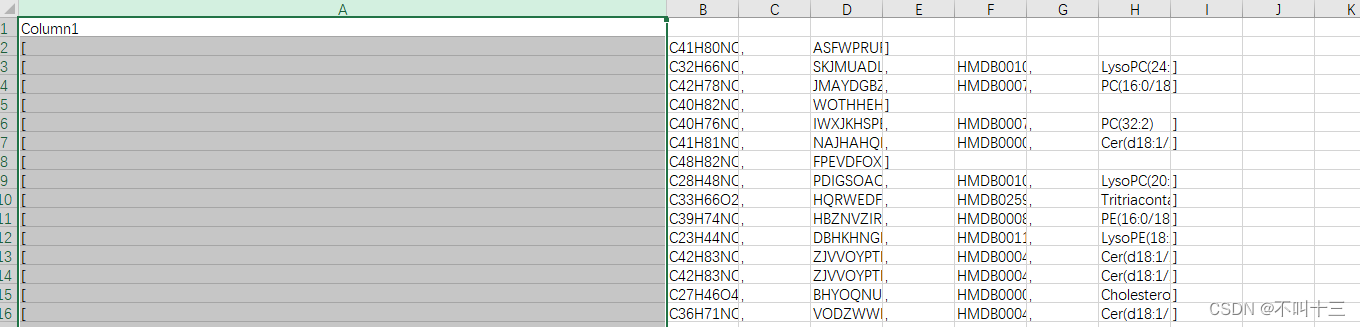
最后再给出源代码:
import time
import pandas as pd
import re
import os
from tqdm import tqdm
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
import requests
from bs4 import BeautifulSoup
import pandas as pd
from concurrent.futures import ThreadPoolExecutor
from requests.exceptions import ConnectionError, Timeout
def panduanjiye(url):
url_list = []
try:
response = requests.get(url,headers=headers, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
except ConnectionError as e:
url_list = []
print(f"连接错误:{str(e)}")
except Timeout:
url_list = []
Comparison.append(f"请求超时: {str(Timeout)}")
else:
page_info = soup.find_all('div', class_='pagination-holder')
page_max = 0
page_list = []
for li in page_info:
page_elements = li.find_all('li', class_='page')
if len(page_elements)>0:
for page in page_elements:
text = page.find('a').text
if text.isdigit():
page_list.append(text)
else:
print("The text is not a number:", text)
page_max = max(page_list)
if int(page_max)>0:
url_list = []
for i in range(1,int(page_max)+1):
page_url = url[:39]+str(i)+url[40:]
url_list.append(page_url)
else:
url_list.append(url)
response.close()
return url_list
def scrape_url(url,inchikey,Comparison):
try:
response = requests.get(url,headers=headers, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
except ConnectionError as e:
Comparison.append(str(e))
print(f"连接错误:{str(e)}")
except Timeout:
Comparison.append(f"请求超时: {str(Timeout)}")
print(f"请求超时: {str(Timeout)}")
else:
result_links = soup.find_all('div', class_='result-link')
page_info = soup.find_all('div', class_='pagination-holder') # 找到翻页
page_max = 0
for li in page_info:
page_list = []
page_elements = li.find_all('li', class_='page')
if len(page_elements)>0:
for page in page_elements:
# link = page.find('a')['href']
text = page.find('a').text
if text.isdigit():
page_list.append(text)
else:
print("The text is not a number:", text)
page_max = max(page_list)
if int(page_max)>0:
url_list = []
for i in range(1,int(page_max)+1):
page_url = url[:39]+str(i)+url[40:]
url_list.append(page_url)
flag = False
for link in result_links:
href = link.find('a', class_='btn-card').get('href')
url2 = 'https://hmdb.ca/'+href
try:
response_sub = requests.get(url2,headers=headers, timeout=10)
soup_sub = BeautifulSoup(response_sub.text, 'html.parser')
except ConnectionError as e:
Comparison.append(str(e))
print(f"连接错误:{str(e)}")
except Timeout:
Comparison.append(f"请求超时: {str(Timeout)}")
else:
result_th = soup_sub.find_all('th', string='InChI Key')
result_InChI_Key = result_th[0].find_next_sibling('td')
if flag is True:
break
pattern = r'^([^.-]*)'
match = re.search(pattern, result_InChI_Key.text.strip())
if inchikey==match.group(1):
flag = True
result_common = soup_sub.find_all('th', string='Common Name')
result_common_name = result_common[0].find_next_sibling('td')
result_HMDB = soup_sub.find_all('th', string='HMDB ID')
result_HMDB_ID = result_HMDB[0].find_next_sibling('td')
Comparison.append(result_HMDB_ID.text.strip())
Comparison.append(result_common_name.text.strip())
response_sub.close()
response.close()
return Comparison
folder_path = r'D:\PythonDemo\HMDB_csv'
for filename in os.listdir(folder_path):
if filename.endswith('.csv'):
file_path = os.path.join(folder_path, filename)
print('='*20,'Start Run ',file_path,'='*20)
file_name_without_extension = os.path.splitext(filename)[0]
txtname = file_name_without_extension+'.txt'
Txt_path = os.path.join(folder_path,txtname)
data = pd.read_csv(file_path)
Comparison_results = []
flags = False
for index, row in tqdm(data.iterrows(),total=len(data.iloc[:,0])):
Comparison = []
Formula = row['Formula']
Comparison.append(Formula)
Comparison.append(row['INCHIKEY'])
url = f'https://hmdb.ca/unearth/q?button=&page=1&query={Formula}&searcher=metabolites'
page_list = panduanjiye(url)
iteam = []
print(f' Formula: {Formula}','='*10,f'The Formula has been found {len(page_list)} of pages')
if len(page_list)>0:
for page in page_list:
pattern = r'^([^.-]*)'
match = re.search(pattern, row['INCHIKEY'])
Comparison = scrape_url(url,match.group(1) ,Comparison)
iteam = Comparison
if len(iteam)<len(Comparison):
iteam = Comparison
if len(iteam)>3:
flags = True
break
Comparison_results.append(iteam)
with open(Txt_path,'a',encoding='utf-8') as f:
f.write(str(iteam)+'\n')
print(iteam)
else:
iteam = Comparison.append('连接错误或请求超时,请重新提交本条数据')
with open(Txt_path,'a',encoding='utf-8') as f:
f.write(str(iteam)+'\n')
print(iteam)
df = pd.DataFrame(Comparison_results)
df_name = 'HMDB'+file_name_without_extension+'.csv'
df_path = os.path.join(folder_path,df_name)
df.to_csv(df_path)
print('='*20,'Next file','='*20)




















 5451
5451



 到【灌水乐园】发言
到【灌水乐园】发言









