




更多内容同步更新与个人博客系统:数据处理之seaborn的学习相关数据集在附件中.
1.什么是seaborn?
#学习seaborn的原因
'''
Matplotlib虽然已经是比较优秀的绘图库了,但是它有个令人头疼的问题,那就是API使用
过于复杂,它里面有上千个函数和参数,属于典型的那种可以用它做任何事,却无从下手.
seaborn基于Matplotlib核心库进行了更高级的API封装,可以轻松地画出更漂亮的图形,
而seaborn的漂亮主要体现在配色更加舒服,以及图形元素的样式更加细腻
'''
#安装:pip install seaborn
#可视化数据的分布
'''
当处理一组数据时,通常先要做的就是了解变量是如何分布的.
.对于单变量的数据来说,采用直方图或核密度曲线是一个不错的选择
.对于双变量来说,可采用多面板图形展示
针对这种情况,seaborn库提供了对单变量和双变量分布的绘制函数,如displot()函数,joinplot()
函数
'''
2.单变量分布的图形绘制
import seaborn as san
import numpy as np
import matplotlib.pyplot as plt
'''
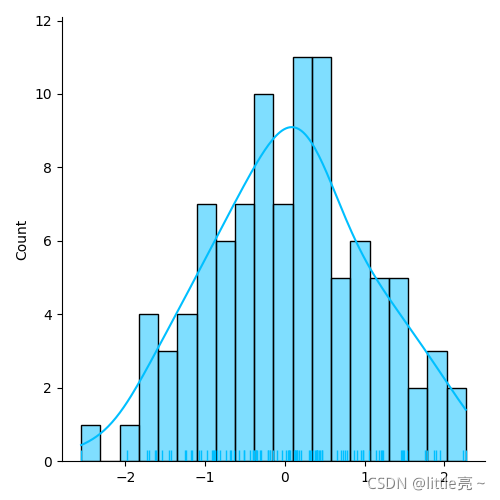
可以采用最简单的直方图描述单变量的分布情况.seaborn中提供了displot()函数,它默认
绘制的是一个带有核密度估计曲线的直方图
API:seaborn.displot(a,bins=None,hist=True,kde=True,rug=False,fit=None,color=None)
参数:
a:数据,可以是series,一维数组等
bins:用于控制条形的数量
hist:是否绘制直方图
kde:是否绘制高斯密度估计曲线
rug:是否在支持的轴方向上绘制rugplot
'''
#核密度估计
'''
核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,可以比较直观地看出
数据样本本身的分布特征
'''
np.random.seed(0)
list_=np.random.randn(100)
san.displot(list_,bins=20,kde=True,rug=True,color='deepskyblue')
plt.show()
3.双变量分布的图形绘制
import numpy as np
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
#双变量分布
'''
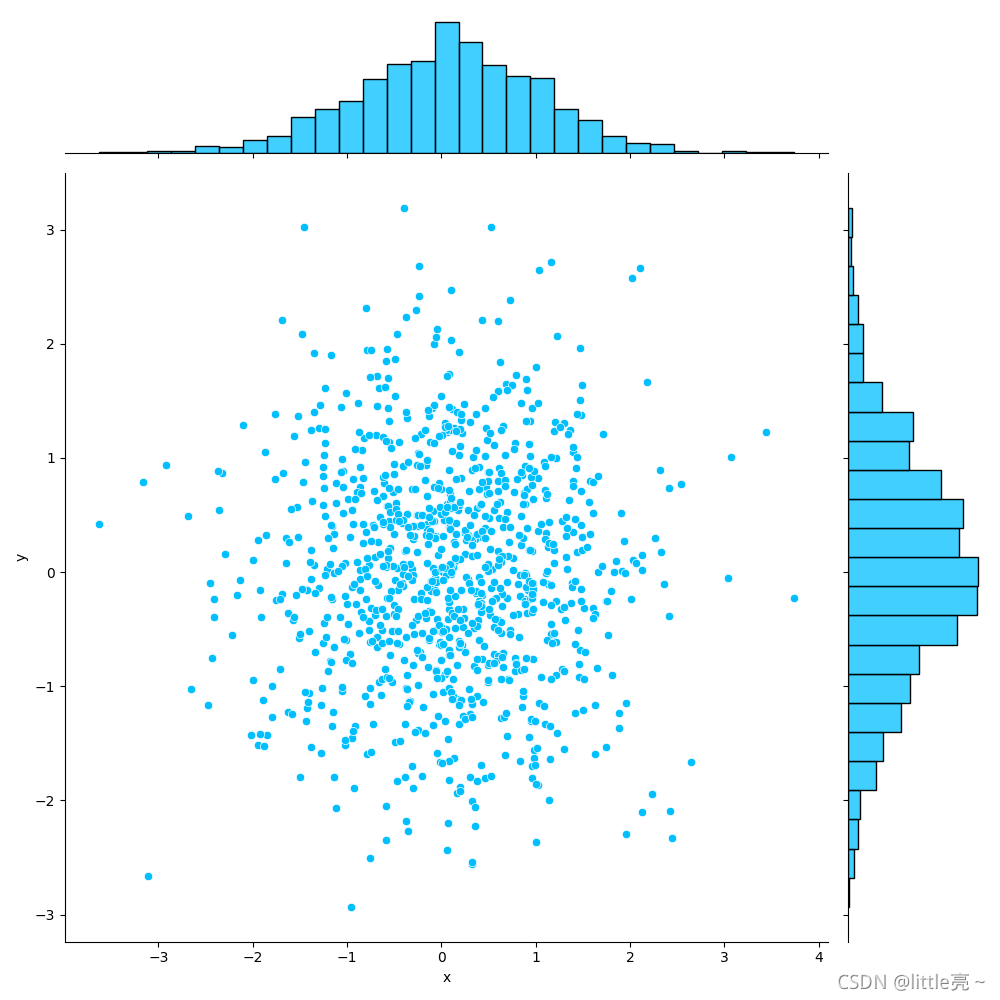
两个变量的二元分布可视化也很有用,在seaborn中最简单的方法是使用joinplot()函数,
该函数可以创建一个多面板图形,比如散点图,二维直方图等,以显示两个变量之间的关系,以及
每个变量在单坐标轴上的单变量分布
API:seaborn.jointplot(x,y,data=None,kind="scatter",stat_func=None,color=None,
ratio=5,space=0.2,dropna=True)
参数:
data:数据,可以是DataFrame
kind:表示绘制图形的类型
stat_func:用于计算有关关系的统计量并标注图
color:绘图元素的颜色
height:用于设置图的大小(正方形)
ratio:表示中心图与侧边图的比例.该参数值越大,则中心图的占比越大
space:用于设置中心图与侧边图的间隔大小
'''
#绘制散点图
df=pd.DataFrame({'x':np.random.randn(1000),'y':np.random.randn(1000)})
sns.jointplot(x='x',y='y',data=df,kind='scatter',color='deepskyblue',height=10,ratio=5,space=0.5,dropna=True,)
# plt.show()
#绘制成对的双变量分布图
dataset=sns.load_dataset('iris')
sns.pairplot(dataset)
plt.show()
4.NBA球员数据分析
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data=pd.read_csv('nba_2017_nba_players_with_salary.csv')
print(data.head())
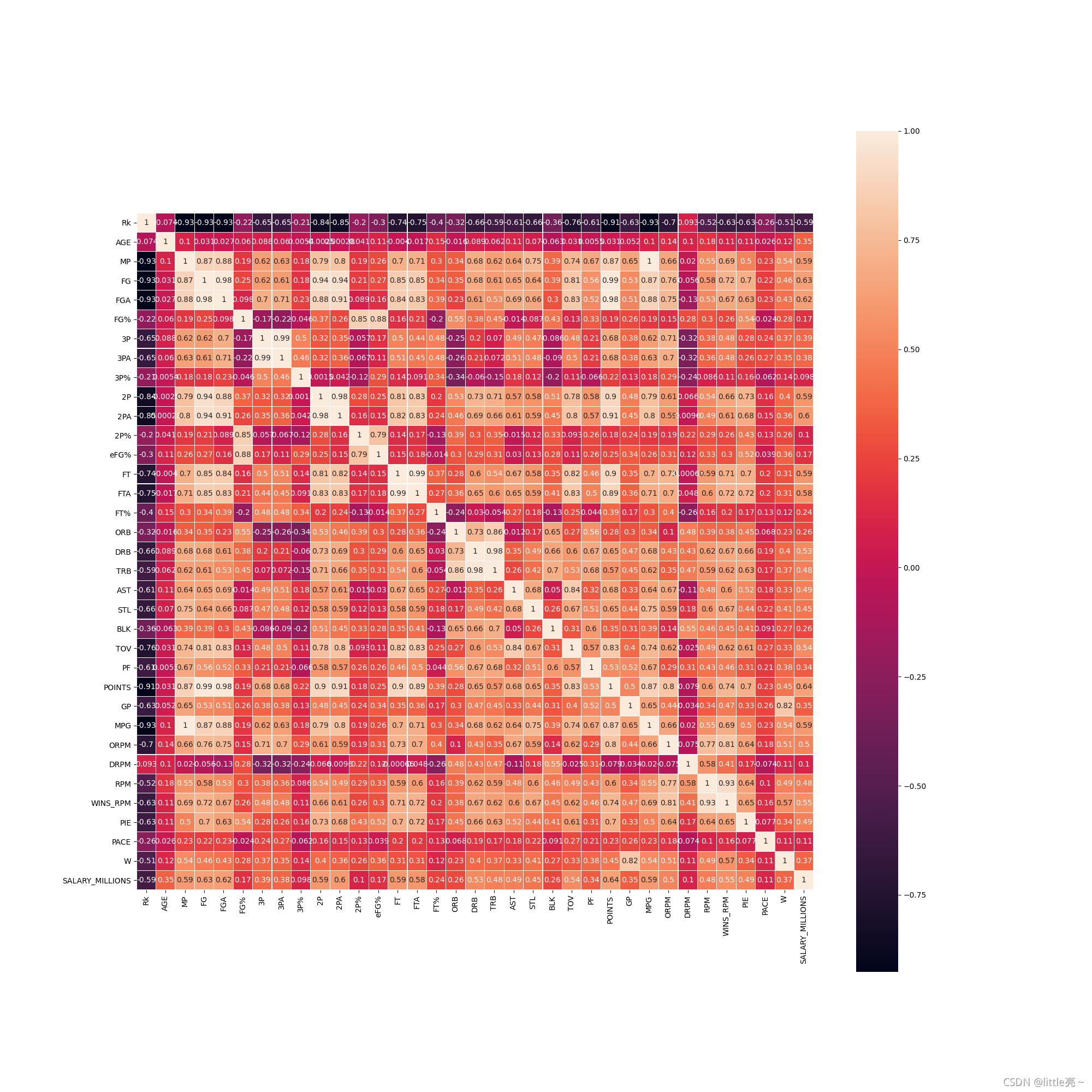
#相关性 求任意两组数据之间的相关性
corr=data.corr()
print(corr.head())
#绘制相关性的热力图
plt.figure(figsize=(50,50))
sns.heatmap(corr,square=True,linewidths=0.1,annot=True)
plt.savefig('NBA球员数据分析之相关性.png')
plt.show()
print(data.columns.values)
#获取球员的效率排行榜
rpm_list=data.loc[:,['PLAYER','AGE','SALARY_MILLIONS','RPM']].sort_values(by='RPM',ascending=False)
print(rpm_list.head(10))
#获取球员的薪资排行榜
rpm_list=data.loc[:,['PLAYER','AGE','SALARY_MILLIONS','RPM']].sort_values(by='SALARY_MILLIONS',ascending=False)
print(rpm_list.head(10))
#获取球员的年龄 薪水 效率值的分布情况
#年龄
plt.figure(figsize=(100,50))
sns.set_theme(style='darkgrid')
sns.displot(data['AGE'],kde=True,kind='hist',height=100)
plt.show()
print(data['AGE'])
# age_min=data['AGE'].min()
# age_max=data['AGE'].max()
# age_bins=np.linspace(age_min,age_max,30)
# plt.xticks(age_bins)
# plt.ylabel('AGE')
#薪水
plt.subplot(3,1,2)
sns.displot(data['SALARY_MILLIONS'],kde=True)
salary_min=data['SALARY_MILLIONS'].min()
salary_max=data['SALARY_MILLIONS'].max()
salary_bins=np.linspace(salary_min,salary_max,30)
plt.xticks(salary_bins)
plt.ylabel('SALARY_MILLIONS')
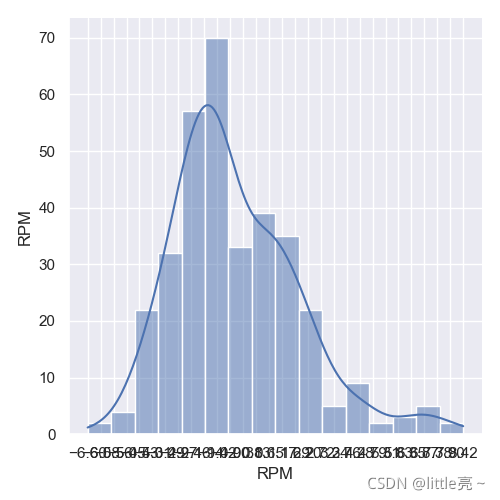
#效率
plt.subplot(3,1,3)
sns.displot(data['RPM'],kde=True)
rpm_min=data['RPM'].min()
rpm_max=data['RPM'].max()
rpm_bins=np.linspace(rpm_min,rpm_max,30)
plt.xticks(rpm_bins)
plt.ylabel('RPM')
#查看各个变量之间的相关性
# sns.pairplot(data)
plt.show()
5.NBA球员数据分析之延伸变量
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 读取数据
data = pd.read_csv('nba_2017_nba_players_with_salary.csv')
print(data.columns.values)
# 对年龄进行一个划分
def cut_age(x):
if x < 25:
return 'young'
elif x > 30:
return 'old'
else:
return 'best'
data['age_cut'] = data['AGE'].apply(lambda x: cut_age(x))
print(data.head())
#绘制各个年龄段薪资关于效率的散点图
plt.figure(figsize=(10,10),)
sns.set_theme(style='darkgrid')
plt.title('the correlation between RPM and SALARY in different age group')
plt.xlabel('RPM')
plt.ylabel('SALARY')
rpm_max=data['RPM'].max()
rpm_min=data['RPM'].min()
salary_max=data['SALARY_MILLIONS'].max()
salary_min=data['SALARY_MILLIONS'].min()
plt.xticks(np.linspace(rpm_min,rpm_max,10))
plt.yticks(np.linspace(salary_min,salary_max,10))
#young
young_rpm=data[data.age_cut=='young'].RPM
young_salary=data[data.age_cut=='young'].SALARY_MILLIONS
plt.scatter(young_rpm,young_salary,marker='o',label='young')
#old
old_rpm=data[data.age_cut=='old'].RPM
old_salary=data[data.age_cut=='old'].SALARY_MILLIONS
plt.scatter(old_rpm,old_salary,marker='^',color='green',label='old')
#best
best_rpm=data[data.age_cut=='best'].RPM
best_salary=data[data.age_cut=='best'].SALARY_MILLIONS
plt.scatter(best_rpm,best_salary,marker='x',color='red',label='best')
plt.legend()
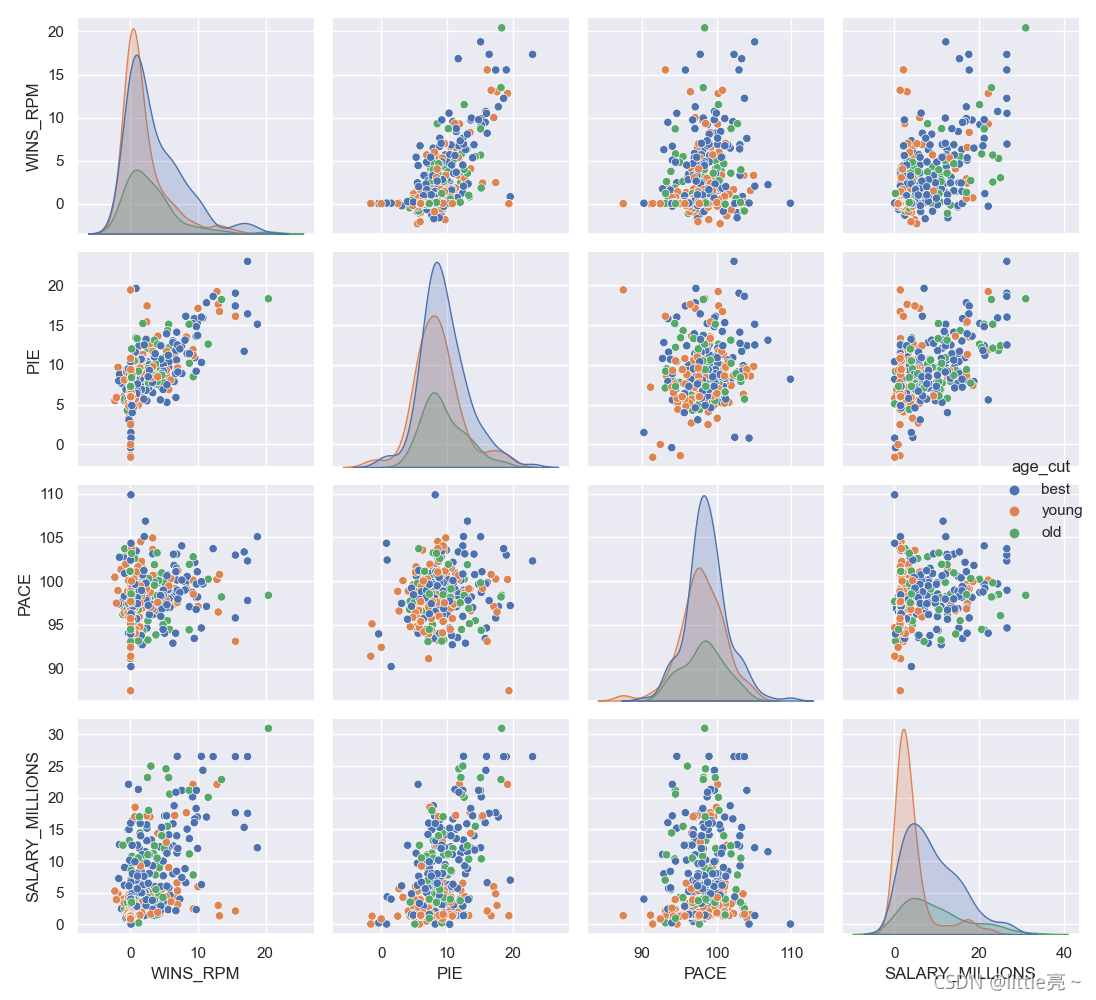
sns.pairplot(data.loc[:,['WINS_RPM' ,'PIE', 'PACE','SALARY_MILLIONS','age_cut']],hue='age_cut')
plt.show()
6.NBA球队数据分析之箱线图和小提琴图的应用
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('nba_2017_nba_players_with_salary.csv')
# print(data.columns.values)
# 对年龄进行一个划分
def cut_age(x):
if x < 25:
return 'young'
elif x > 30:
return 'old'
else:
return 'best'
data['age_cut'] = data['AGE'].apply(lambda x: cut_age(x))
# 按照不同球队的平均薪资进行降序排序
'''
agg({'SALARY_MILLIONS': np.mean,'RPM':np.mean})
计算不同球队下薪资和效率的平均值
'''
data2 = data.groupby(by=['TEAM'], as_index=True).agg({'SALARY_MILLIONS': np.mean, 'RPM': np.mean}).sort_values(
by=['SALARY_MILLIONS'], ascending=False)
# print(data2)
# 按照分球队分年龄段,上榜球员数降序排列,如果上榜球员数相同,则按照效率值降序排列
data3 = data.groupby(by=['TEAM', 'age_cut']).agg(
{'PLAYER': np.size, 'RPM': np.mean, 'SALARY_MILLIONS': np.mean, }).sort_values(
by=['PLAYER', 'RPM', 'SALARY_MILLIONS'], ascending=False)
# print(data3)
# 按照球队的平均效率值降序排序
data4 = data.groupby(by=['TEAM']).agg({'RPM': np.mean, 'SALARY_MILLIONS': np.mean}).sort_values(by=['RPM'],
ascending=False)
# print(data4)
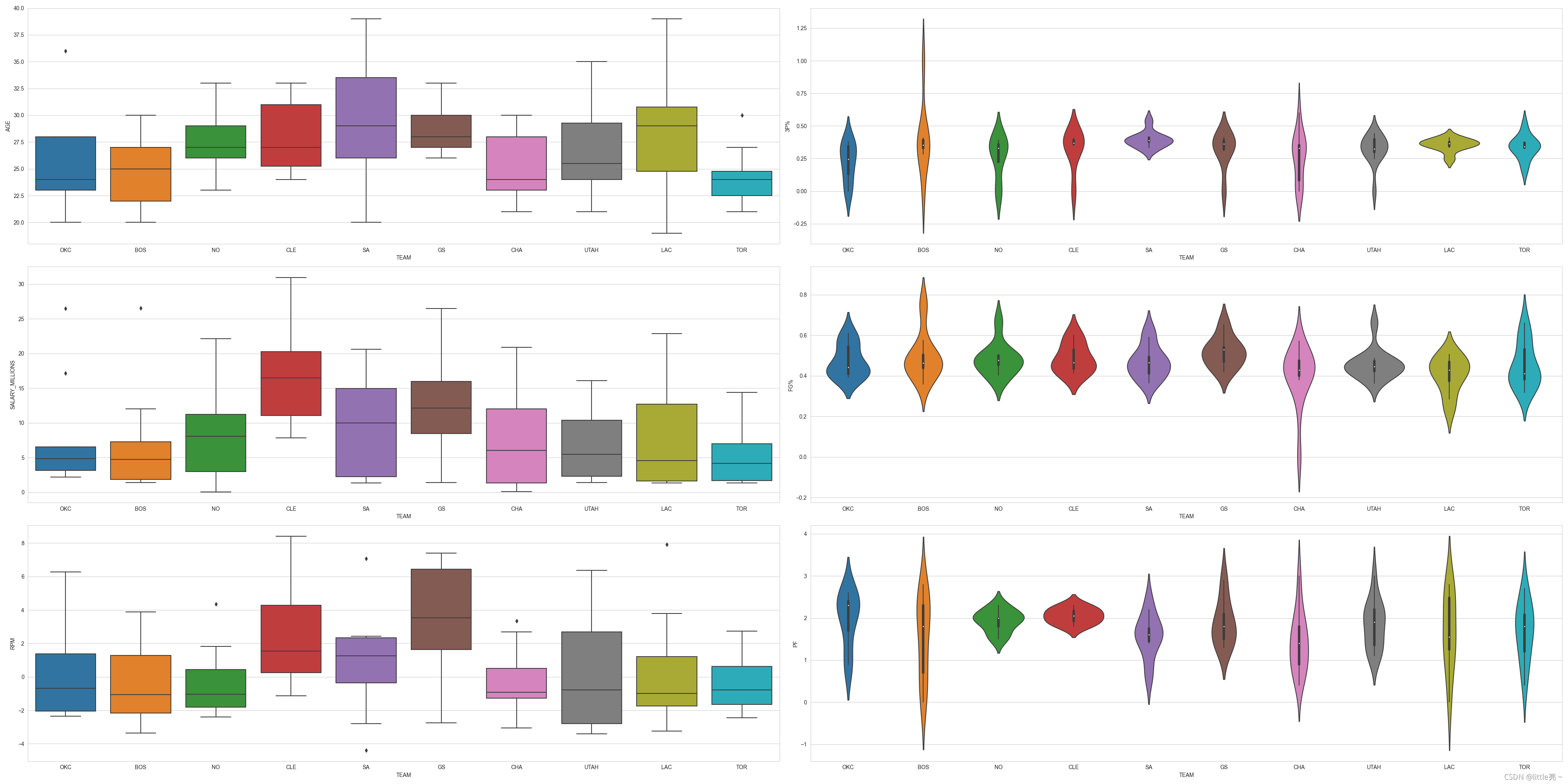
# 利用箱线图和小提琴图进行数据分析
# 去特定的几组球队
team = ['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS']
data5 = data[data.TEAM.isin(team)]
plt.figure(figsize=(40, 20))
sns.set_style('whitegrid')
# 年龄
plt.subplot(3, 2, 1)
sns.boxplot(x='TEAM', y='AGE', data=data5)
# 薪资
plt.subplot(3, 2, 3)
sns.boxplot(x='TEAM', y='SALARY_MILLIONS', data=data5)
#RPM
plt.subplot(3, 2, 5)
sns.boxplot(x='TEAM', y='RPM', data=data5)
#3分球命中率
plt.subplot(3,2,2)
sns.violinplot(x='TEAM',y='3P%',data=data5)
#命中率
plt.subplot(3,2,4)
sns.violinplot(x='TEAM',y='FG%',data=data5)
#犯规
plt.subplot(3,2,6)
sns.violinplot(x='TEAM',y='PF',data=data5)
plt.show()
7.房源信息处理之数据预处理
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 预处理
class Preprocessing:
data = None
# 数据读取
@classmethod
def readData(cls):
Preprocessing.data = pd.read_csv('链家北京租房数据.csv')
# 重复值和空值的处理
# 删除重复值
@classmethod
def deleteDupAndNa(cla):
data = Preprocessing.data
# 重复值检测
isDup = np.all(data.duplicated().values) # 如果有重复值返回True,否则False
# 删除重复值
if isDup:
data.drop_duplicates()
# 空值检测
isNan = np.all(data.isna().values)
if isNan:
data.dropna()
#数据类型的转换
@classmethod
def transformType(cls):
#将面积转换成浮点型数据
newArr=[]
for i in Preprocessing.data['面积(㎡)']:
newArr.append(i[:-2])
newArr=np.array(newArr).astype(np.float64)
Preprocessing.data.loc[:,['面积(㎡)']]=newArr
#房屋类型的替换
newArr2=[]
for i in Preprocessing.data['户型']:
newArr2.append(i.replace('房间','室'))
Preprocessing.data['户型']=newArr2
#返回预处理完成的数据
@classmethod
def returnDoneData(cls):
Preprocessing.readData()
Preprocessing.deleteDupAndNa()
Preprocessing.transformType()
return Preprocessing.data
if __name__ == '__main__':
Preprocessing.readData()
Preprocessing.deleteDupAndNa()
Preprocessing.transformType()
8.房源信息处理之房源数量位置分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from lll07_链家北京租房数据处理之数据预处理 import Preprocessing
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
#获取预处理完成的数据
data=Preprocessing.returnDoneData()
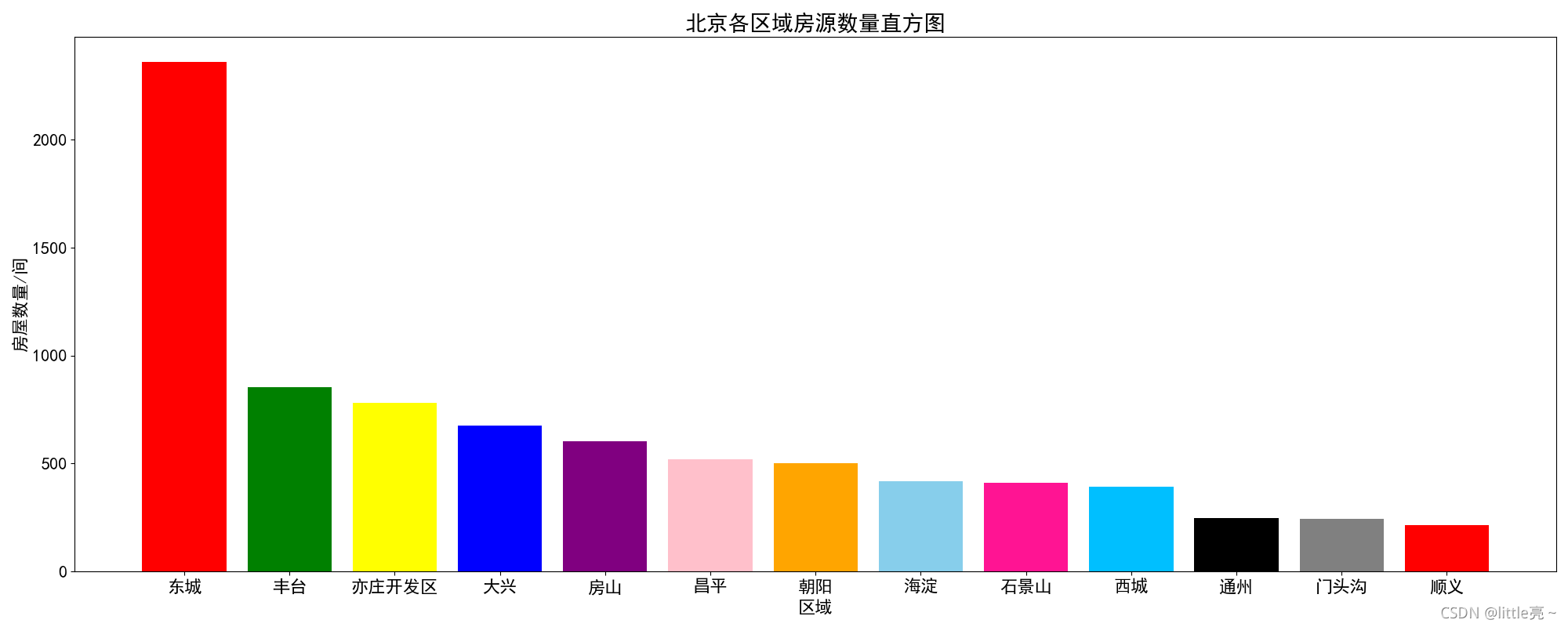
#统计各个地区的房源数量
area=data['区域'].unique()
area_num=data.groupby(by='区域').agg({'户型':np.size}).sort_values(by='户型',ascending=False)
df=pd.DataFrame({'区域':area,'数量':area_num['户型']})
plt.figure(figsize=(20,8))
plt.bar(df['区域'],df['数量'],color=['red','green','yellow','blue','purple','pink','orange','skyblue','deeppink','deepskyblue','black','gray'])
plt.xlabel('区域',fontsize=16)
plt.ylabel('房屋数量/间',fontsize=16)
plt.title('北京各区域房源数量直方图',fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.show()
9.房源信息处理之户型数量分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from lll07_链家北京租房数据处理之数据预处理 import Preprocessing
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正确显示中文
# 获取预处理完成的数据
data = Preprocessing.returnDoneData()
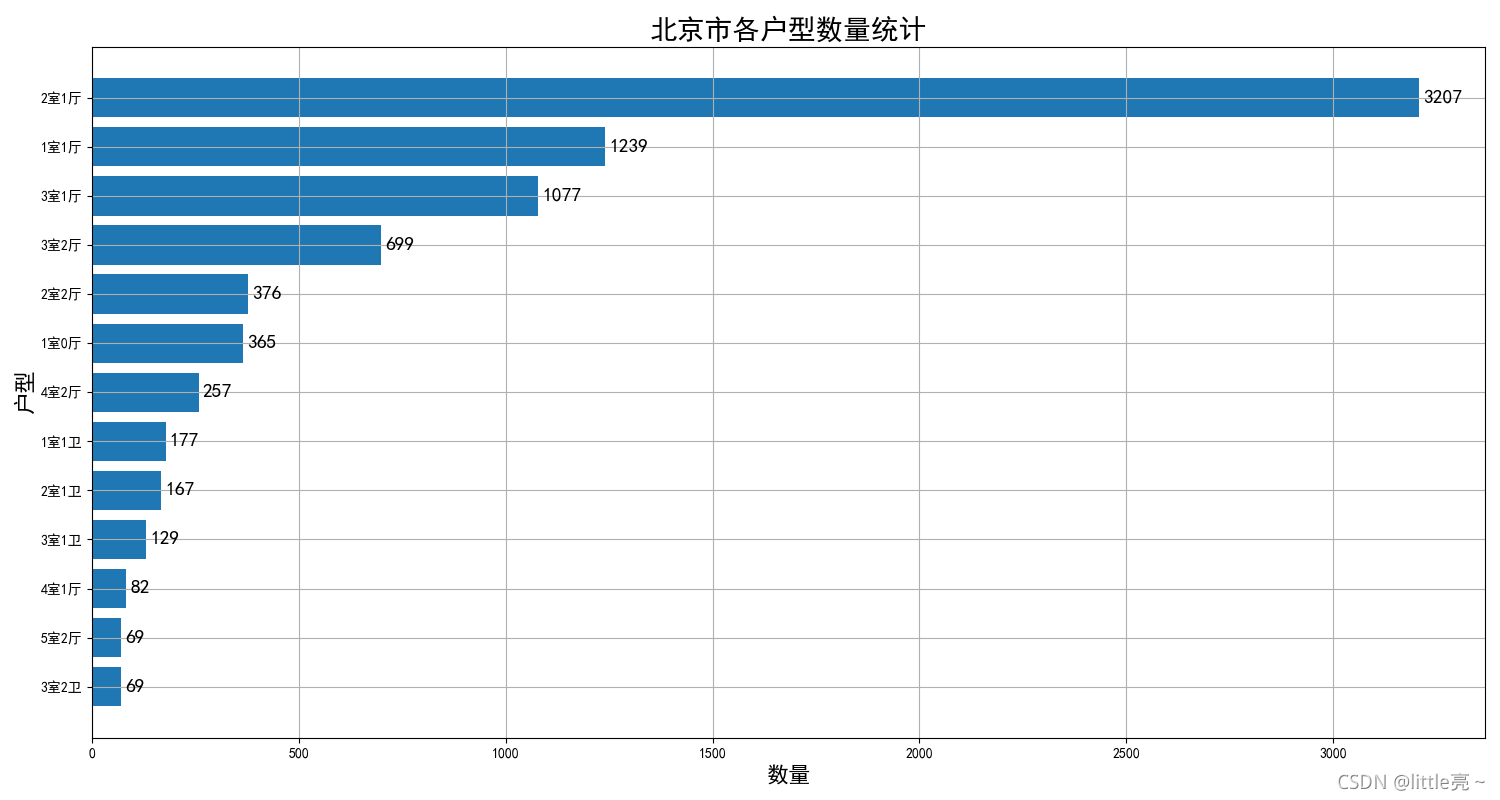
data_house = data['户型']
def all_house(arr): # 获取每个户型的数量
key = np.unique(arr)
result = {}
for k in key:
arr_new = arr[arr == k]
v = arr_new.size
result[k] = v
return result
data = all_house(data_house)
# 筛选出大于50的数据
data = {key: value for key, value in data.items() if value > 50}
# print(data)
df = pd.DataFrame({'户型': data.keys(), '数量': data.values()}).sort_values(by='数量', ascending=True)
plt.figure(figsize=(15, 8))
plt.barh(df['户型'], df['数量'])
plt.xlabel('数量', fontsize=16)
plt.ylabel('户型', fontsize=16)
plt.title('北京市各户型数量统计', fontsize=20)
plt.grid()
# 给柱头添加数量
for x, y in enumerate(df['数量']):
print(x, y)
plt.text(y + 10, x - 0.1, f'{y}', fontsize=14)
plt.show()
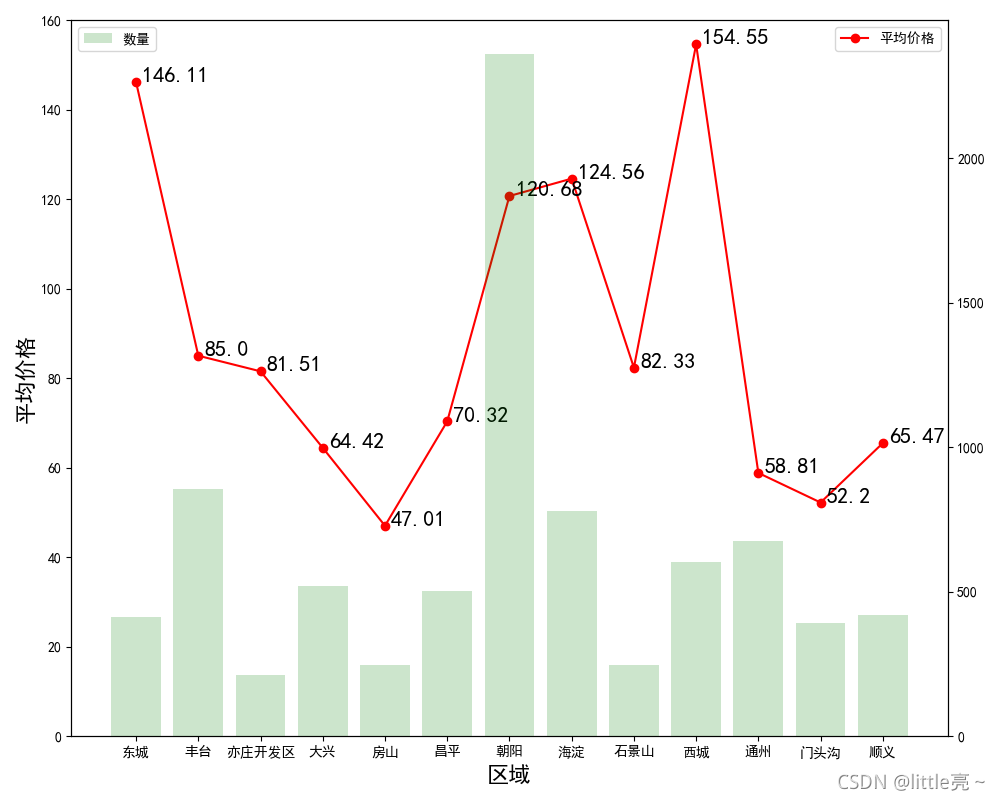
10.房源信息处理之平均租金分析
import numpy as np
import matplotlib.pyplot as plt
from lll07_链家北京租房数据处理之数据预处理 import Preprocessing
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正确显示中文
# 获取预处理完成的数据
data = Preprocessing.returnDoneData()
# 统计各个区域的租金的平均值
data_rent = data.groupby(by=['区域']).agg({'价格(元/月)': np.sum, '面积(㎡)': np.sum, '区域': np.size})
data_rent['平均价格'] = round(np.divide(data_rent['价格(元/月)'], data_rent['面积(㎡)']), 2)
data_rent = data_rent # .sort_values(by='平均价格',ascending=False)
data_rent['数量'] = data_rent['区域']
print(data_rent)
# 绘制图形
x = [i for i in range(data_rent['平均价格'].values.size)]
num = data_rent['数量'].values
price = data_rent['平均价格'].values
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(111)
ax1.plot(x, price, 'or-', label='平均价格') # 绘制折线图
ax1.set_ylim([0, 160])
plt.xlabel('区域', fontsize=16)
plt.ylabel('平均价格', fontsize=16)
plt.legend(loc='upper right')
# 在拐点处显示数量
for i, (x_, y_) in enumerate(zip(x, price)):
plt.text(x_ + 0.1, y_, price[i], fontsize=16)
# 绘制柱状图
ax2 = ax1.twinx()
plt.bar(x, num, alpha=0.2, color='green', label='数量')
plt.xticks(x, data_rent.index.values, fontsize=16)
plt.legend(loc='upper left')
plt.show()
11.房源信息处理之面积划分
import pandas as pd
import matplotlib.pyplot as plt
from lll07_链家北京租房数据处理之数据预处理 import Preprocessing
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正确显示中文
# 获取预处理完成的数据
data = Preprocessing.returnDoneData()
# 统计各面积块的占比
area_divide = [1, 30, 50, 70, 90, 120, 140, 160, 1200]
data_area = pd.cut(data['面积(㎡)'], area_divide)
num_list = []
labels = []
for index in data_area.value_counts().index.values:
num_list.append(data_area.value_counts().loc[index])
str_index = str(index).replace('(', '').replace(']', '').split(',')
label = f'{str_index[0]}-{str_index[1]}平米'
labels.append(label)
plt.figure(figsize=(10, 10))
plt.pie(num_list, labels=labels, autopct='%.2f%%')
plt.legend()
plt.show()


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









