




前言
前面我们主要围绕pyObject和pyTypeObject聊完了python的内建对象部分,现在我们将开启新的篇章—python虚拟机,将聚焦在python的执行部分,搞懂从“代码”到“执行”的过程。开启新的篇章之前,你也许会有一个疑惑:我们写的代码是如何执行的?从表面看,我只要按照python的正确语法书写一段代码,然后“剩下的”交给python解释器,代码就能被执行了!这也许就是大部分人能够给出的解释了,在没有学习此篇章之前,我也是这么认为的,因为我也没有探究过“剩下的部分”python解释器是如何去操作的。因此,从这一篇博客开始,让我们一起带着这个问题,“钻进”python的解释器中,看看它到底做了个啥!🔍🔍🔍
开始
作为python开发者,我相信大家对pyc文件应该并不陌生,它虽然经常“藏”在我们看不到的地方,但有时作用可不小,你也许为了提速,将整个项目的py文件转成pyc文件,然后再去执行;或者你为了加密,将py文件转成pyc文件再发给别人…等等这些,都和pyc文件的特性有关系,这样看来,pyc文件似乎比py文件更“抢手”?这其中似乎有什么蹊跷?还是python解释器对pyc文件有偏心?因此,在开启“python执行过程”的探索,pyc文件似乎比py文件更有研究价值🧐?
什么是pyc文件?
细心的小伙伴应该早就发现了:我们写的py文件夹中,有时候会多一个额外的文件夹:__pychache_,点开这个文件夹,你可能还会发现,这里面会有一些以.pyc结尾的文件,同时,你还会发现它们的文件名和上级目录中的py文件名是有一些对应关系的。
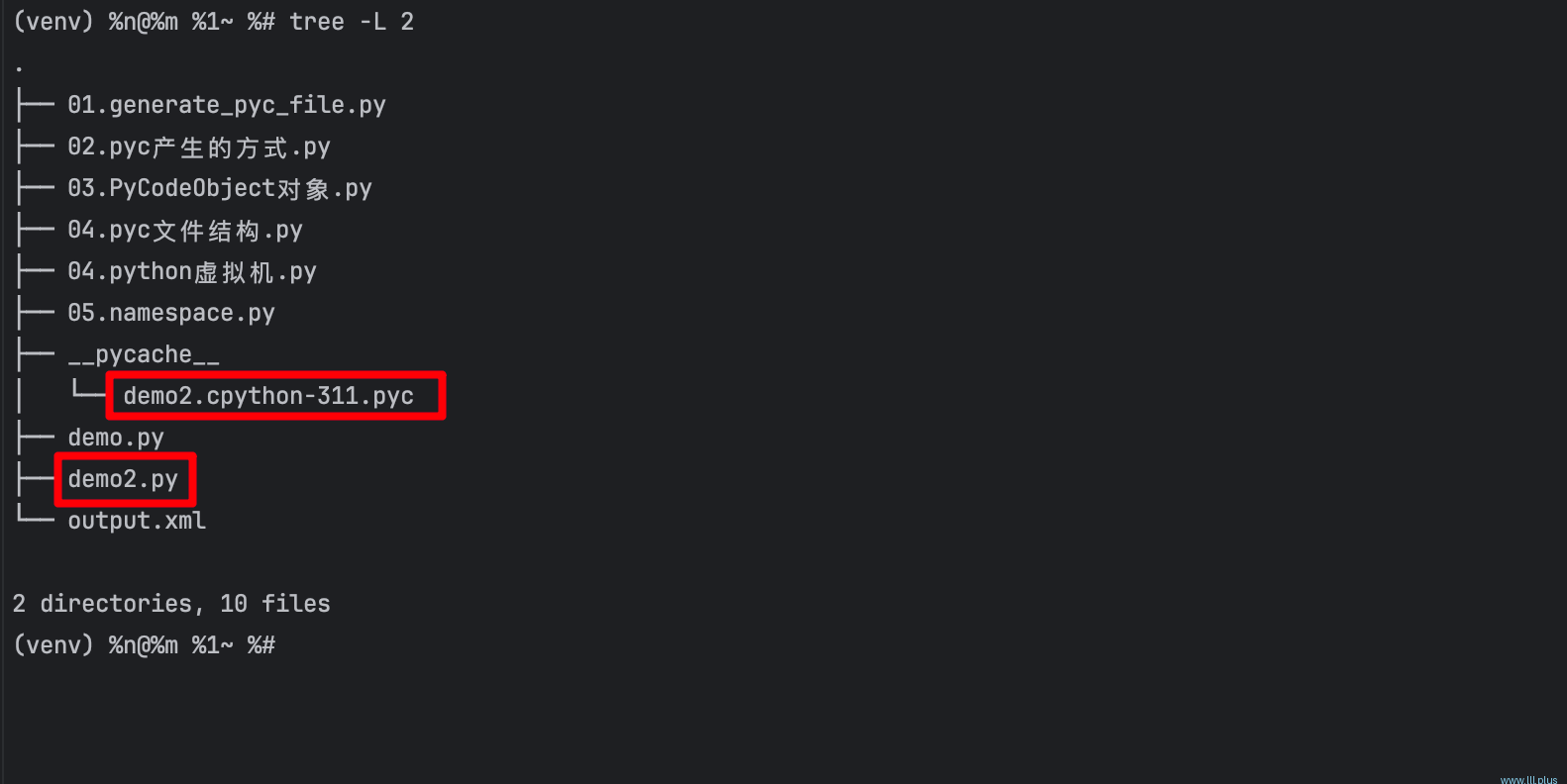
这里的以.pyc结尾的文件就是我们常说的pyc文件,看看它的目录名:__pycache_,根据目录名,我想大家应该猜到它的作用是什么了,没错,我们就可以把它当作是对py文件的一个缓存文件,缓存的主要目的:就是为了提(加载)速!
pyc文件是怎么产生的?
看上面👆的那个截图发现,__pycache__中似乎只有一个.pyc文件,为什么其他的py文件没有对应的pyc文件呢?这也许从侧面说明了一点:pyc文件不是必须的,应该只在特定情况下才能触发生成。(如果你还是有点怀疑,可以查看自己的py文件目录)
是和我们写的代码有关系吗?答案是肯定的!
实际上,当我们每次通过import导入一个py文件时,都可能会触发这个“生成pyc文件”的开关。
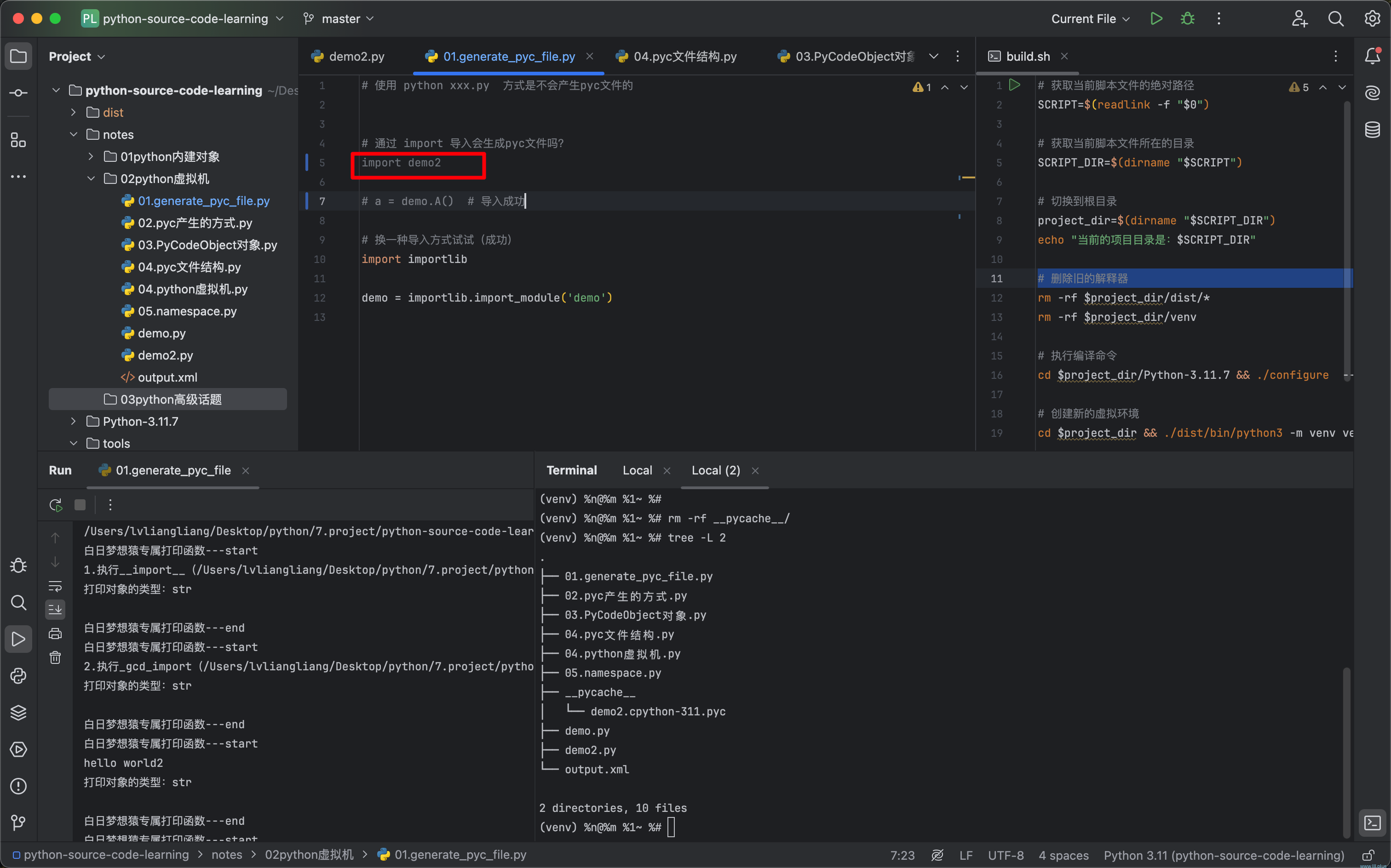
在当前目录所有的py文件中,我只对demo2.py文件进行了导入操作,没有对其他的py文件执行导入操作,因此实际上就是import机制触发了pyc文件的产生。当然,如果你想手动生成,也是可以的,下面是通过代码生成pyc文件的一个方法:
import py_compile
# 将py文件编译成pyc文件(编译成PyCodeObject存放在pyc文件中)
# PyCodeObject是编译真正的结果,pyc文件只是它存放的位置
pyc_path = py_compile.compile(file='demo.py')
# 读取pyc文件的内容
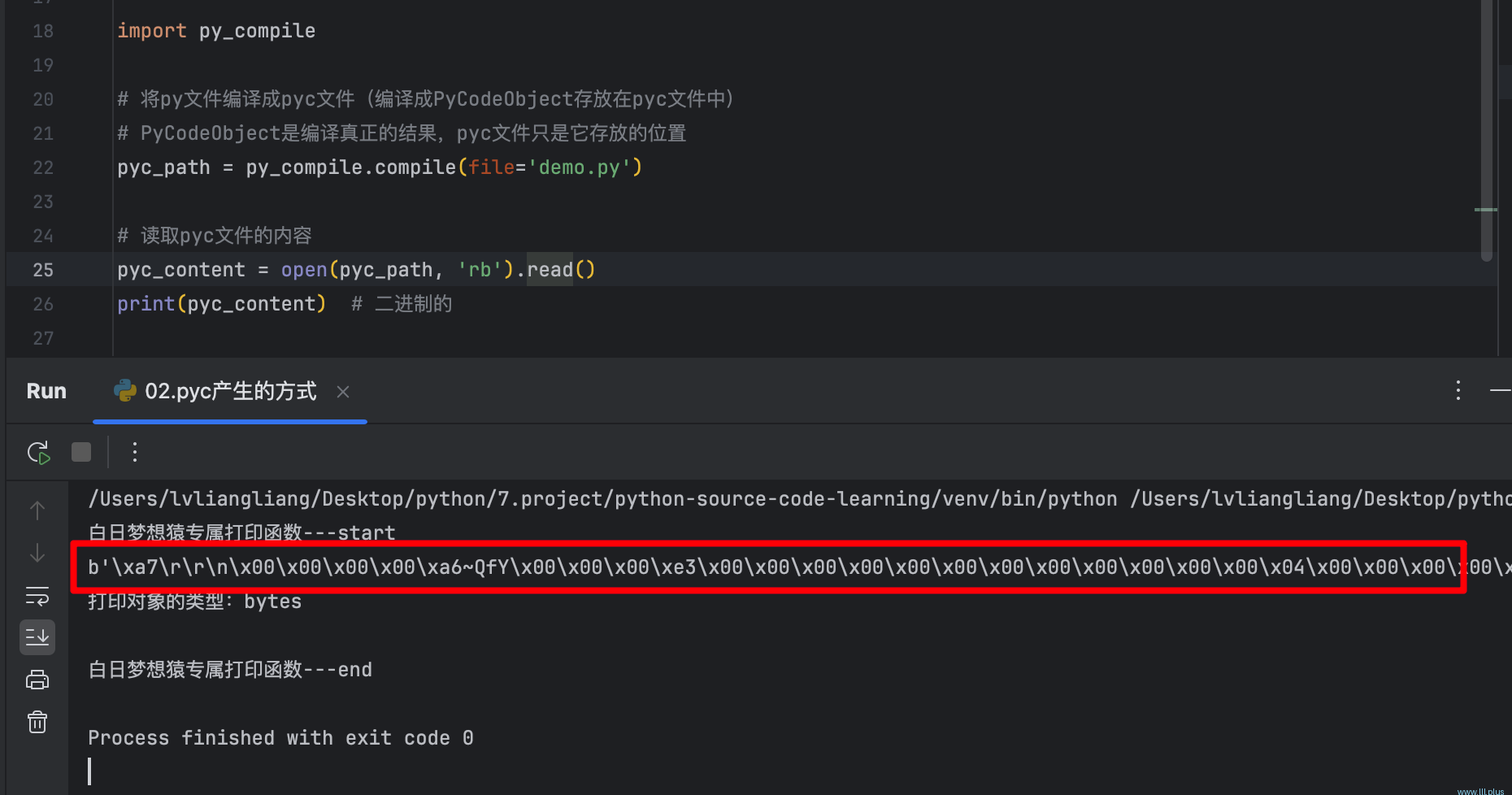
pyc_content = open(pyc_path, 'rb').read()
print(pyc_content) # 二进制的
通过读取pyc文件的内容可以发现,它实际上是一个二进制文件。
pyc文件的结构
到目前为止,我们已经知道pyc文件是一个二进制文件,用于缓存py文件,那么它的结构是怎样的呢?它里面包含了哪些东西?你是不是不知道该何从下手了?别担心!你是否还记得它是可以通过import机制生成的?那么就说明import机制中一定包含了它生成的逻辑!所以那就让我们一起顺藤摸瓜吧!
”顺着import摸瓜“
当我在阅读《python源码剖析》时,书中介绍的创建pyc的过程是在import.c这个文件中产生的,但我找了很长时间都没有找到相应的逻辑,最后通过查阅各种资料和AI发现这个逻辑已经放在标准库importlib中实现了(这里可能是版本的关系导致的,或许有出入,但问题不大)。

该说不说,python中有一个非常好用的东西,那就是它的异常栈,当一个函数有多处实现,不知道具体是哪个地方的时候,我们在每一个地方“埋雷”,当python解释器不小心踩到我们的雷,它的执行路线就会像多米洛骨牌连续翻倒一样,清晰的展现在我们面前:
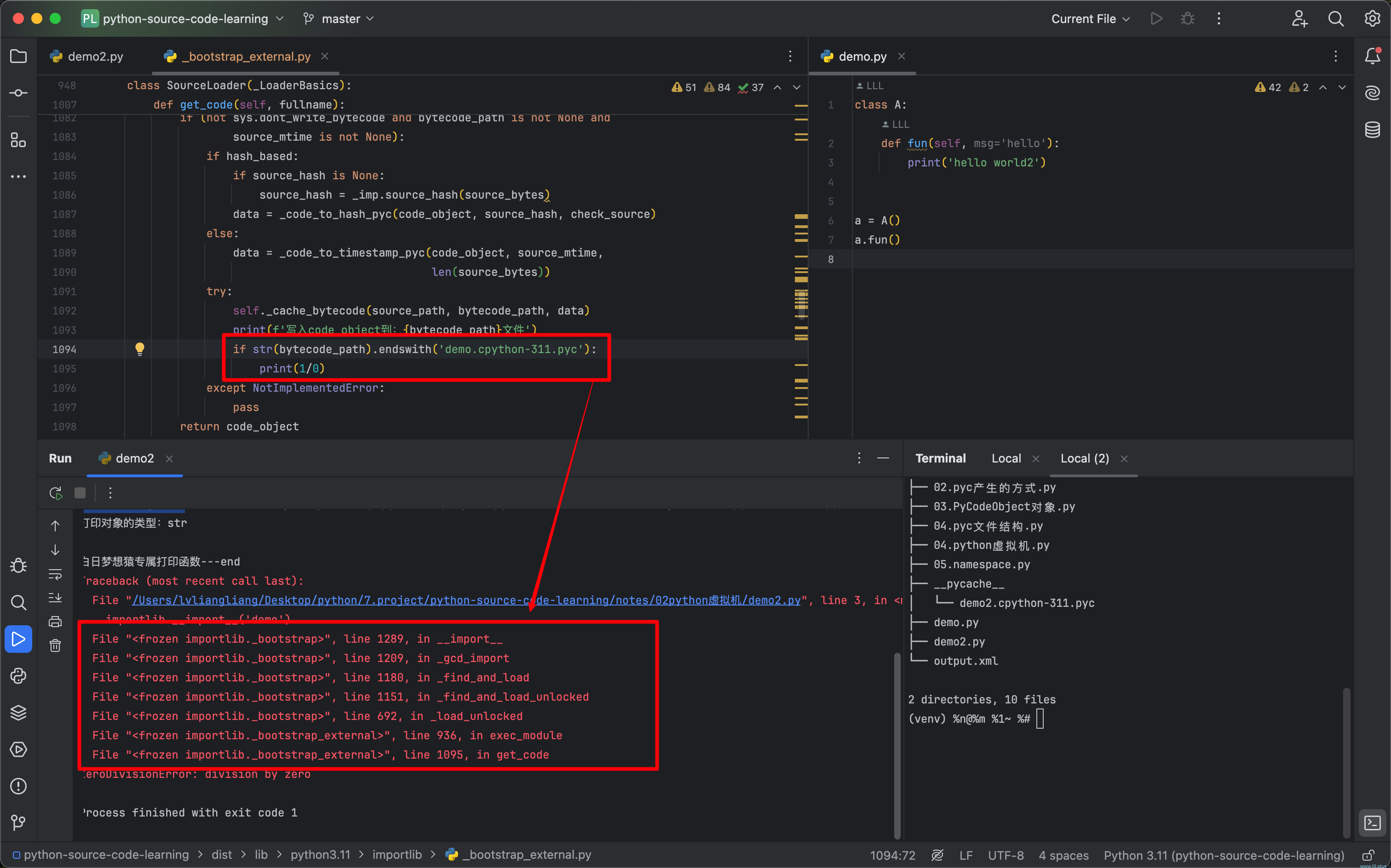
可以看到,import一个模块时,它会走到一个名为get_code的函数中,在此函数中,就包含了pyc文件生成的逻辑,这段代码的大概逻辑就是:
找到模块对应的py路径,根据py路径找到它对应的pyc路径;尝试从pyc中读取,如果读取成功,校验它和py文件中的内容是否一致(这里有两种校验方式:基于hash和基于时间戳),如果是一致的就直接返回;如果发生了变化,就从py中读取得到code obejct,并写入到对应的pyc文件,之后再返回;最后调用exec方法执行返回的code obejct。
def get_code(self, fullname):
"""Concrete implementation of InspectLoader.get_code.
Reading of bytecode requires path_stats to be implemented. To write
bytecode, set_data must also be implemented.
"""
source_path = self.get_filename(fullname)
source_mtime = None
source_bytes = None
source_hash = None
hash_based = False
check_source = True
try:
# 获取py文件对应的pyc文件的路径
bytecode_path = cache_from_source(source_path)
except NotImplementedError:
bytecode_path = None
else:
try:
"""
- 'mtime' (mandatory) is the numeric timestamp of last source
code modification;
- 'size' (optional) is the size in bytes of the source code."""
st = self.path_stats(source_path)
except OSError:
pass
else:
# py文件最后的修改时间
source_mtime = int(st['mtime'])
try:
data = self.get_data(bytecode_path)
except OSError:
pass
else:
exc_details = {
'name': fullname,
'path': bytecode_path,
}
try:
flags = _classify_pyc(data, fullname, exc_details)
bytes_data = memoryview(data)[16:]
hash_based = flags & 0b1 != 0
if hash_based:
check_source = flags & 0b10 != 0
if (_imp.check_hash_based_pycs != 'never' and
(check_source or
_imp.check_hash_based_pycs == 'always')):
source_bytes = self.get_data(source_path)
source_hash = _imp.source_hash(
_RAW_MAGIC_NUMBER,
source_bytes,
)
_validate_hash_pyc(data, source_hash 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









