




1.DeepSeek 在 LLM 推理上的创新方法
DeepSeek 在最新论文中详细介绍了他们通过强化学习(RL)提升大语言模型(LLM)推理能力的创新方法——DeepSeek-R1。这项研究标志着一个重要的进展,即如何通过纯强化学习提升 LLM 解决复杂问题的能力,而不依赖于大量的监督微调。
2.DeepSeek-R1 的技术概述
2.1 模型架构
DeepSeek-R1 不是单一的模型,而是一个模型家族,包括:
-
DeepSeek-R1-Zero
-
DeepSeek-R1
2.2 主要区别
-
DeepSeek-R1-Zero 是团队最初的实验,完全基于强化学习,没有进行任何监督微调。他们从基础模型出发,直接应用强化学习,让模型通过试错过程自行发展推理能力。这种方法在 AIME 2024 竞赛中达到了 71% 的准确率,展现出了一定的推理能力,但存在可读性和语言一致性上的限制。该模型采用 6710 亿参数,使用 Mixture-of-Experts (MoE) 架构,每个 token 仅激活 370 亿参数,展现出了诸如 自我验证、反思、长链推理(CoT) 等涌现能力。
-
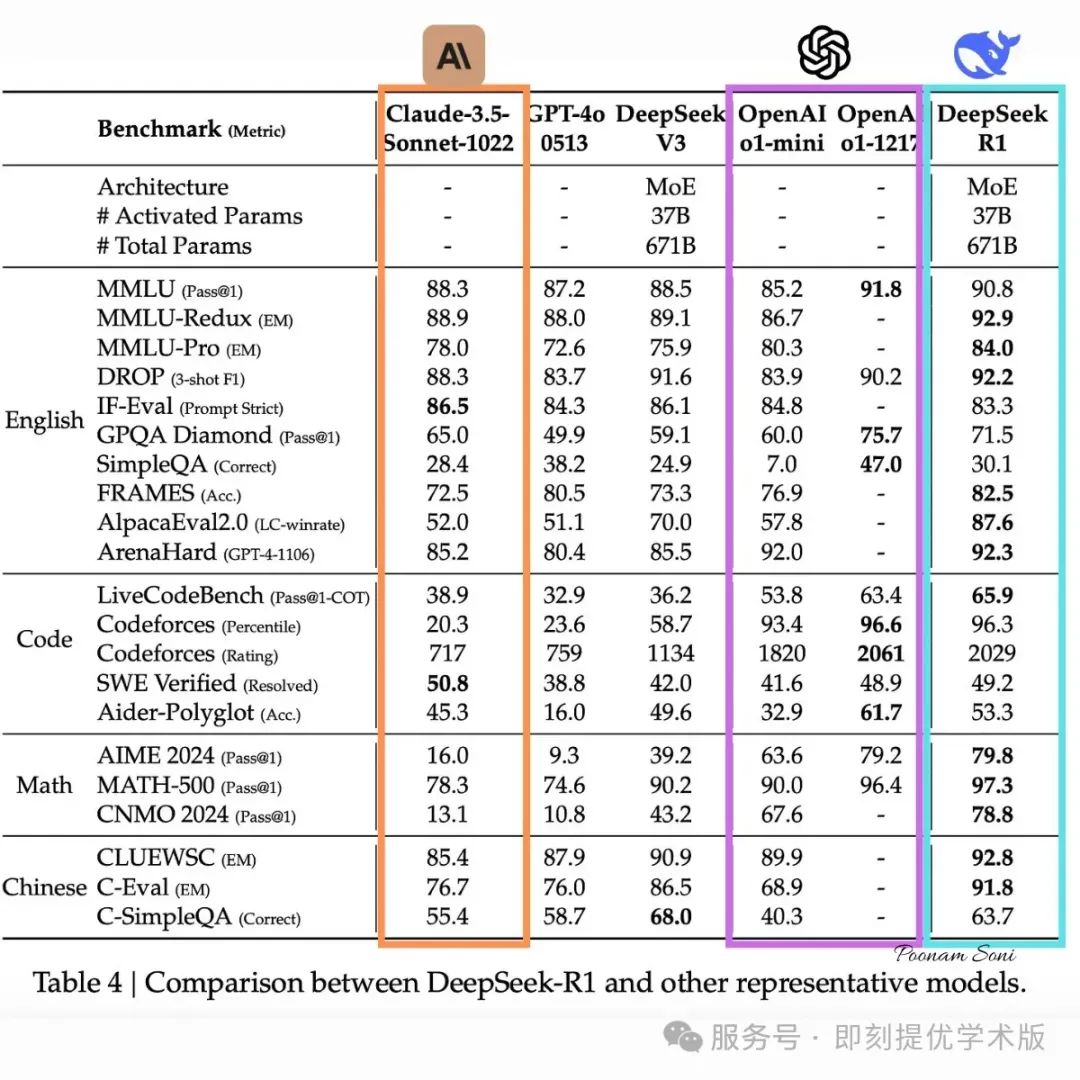
DeepSeek-R1 采用了更复杂的多阶段训练方法。它并非纯强化学习,而是在强化学习前,首先进行 监督微调(使用精心挑选的“冷启动数据”),然后再应用强化学习。这种方法解决了 DeepSeek-R1-Zero 的局限性,同时实现了更高的性能。该模型仍然是 6710 亿参数,但在可读性和连贯性上有明显提升。
3. 训练方法对比
3.1 训练方法
-
强化学习(RL): DeepSeek-R1 主要依赖强化学习,而不是传统的监督学习。训练过程中使用 群体相对策略优化(GRPO),结合准确性和格式奖励来增强推理能力,而无需大量标注数据。
-
蒸馏技术: DeepSeek 还发布了从 1.5B 到 70B 参数的蒸馏版本,这些模型基于 Qwen 和 Llama 架构,证明了复杂推理能力可以被压缩进更小、更高效的模型。蒸馏过程使用 DeepSeek-R1 生成的合成推理数据进行微调,从而在降低计算成本的同时保持高性能。
3.2 训练流程对比
3.2.1 DeepSeek-R1-Zero 训练流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5452
5452





 到【灌水乐园】发言
到【灌水乐园】发言







