




异步
作为开发人员会经常需要通过 API 与这些大模型进行交互。然而,随着应用程序的复杂性和规模不断增长,对高效且高性能的 API 交互的需求变得至关重要。这就是异步编程的亮点,它使我们能够在使用 LLM API 时最大限度地提高吞吐量并最大限度地减少延迟。
在这里我们将探索 Python 中异步 LLM API 调用的世界。将涵盖从异步编程的基础知识到处理复杂工作流的高级技术的所有内容。
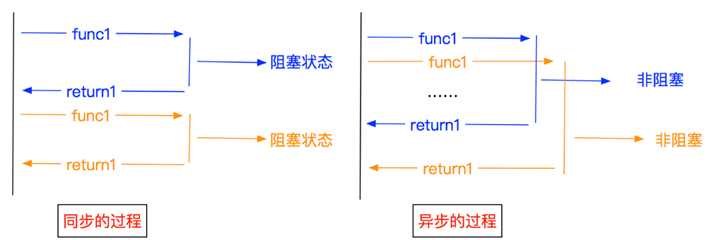
异步编程允许同时执行多个操作而不会阻塞执行的主线程。在 Python 中,这主要通过以下方式实现: 异步 模块,它提供了一个使用协程、事件循环和未来编写并发代码的框架。

关键概念:
- 协程:使用以下函数定义 异步定义 可以暂停和恢复。
- 事件循环:管理和运行异步任务的中央执行机制。
- 等待项:可以与 await 关键字一起使用的对象(协同程序、任务、未来)。
这是一个简单的例子来说明这些概念:
import asyncio
async def greet(name):
await asyncio.sleep(1) # Simulate an I/O operation
print(f"Hello, {name}!")
async def main():
await asyncio.gather(
greet("Alice"),
greet("Bob"),
greet("Charlie")
)
asyncio.run(main())
在这个例子中,定义了一个异步函数 greet 模拟 I/O 操作 asyncio.sleep()。 该 main 功能用途 asyncio.gather() 同时运行多个问候语。尽管有睡眠延迟,但所有三个问候语将在大约 1 秒后打印出来,这展示了异步执行的强大功能。
LLM API 调用中异步的需求
使用 LLM API 时,我们经常会遇到需要按顺序或并行进行多个 API 调用的情况。传统的同步代码可能会导致严重的性能瓶颈,尤其是在处理高延迟操作(例如对 LLM 服务的网络请求)时。
假设我们需要使用 LLM API 为 100 篇不同的文章生成摘要。使用同步方法时,每个 API 调用都会被阻塞,直到收到响应为止,可能需要几分钟才能完成所有请求。另一方面,异步方法允许我们同时发起多个 API 调用,从而大大缩短总体执行时间。
设置环境
要开始使用异步 LLM API 调用,需要使用必要的库设置 Python 环境。以下是需要的内容:
- Python的3.7 或更高版本(用于本机异步支持)
- aiohttp:异步 HTTP 客户端库
- openai: 官方 OpenAI Python 客户端 (如果使用 OpenAI 的 GPT 模型)
- ** langchain**:使用 LLM 构建应用程序的框架(可选,但建议用于复杂的工作流程)
可以使用 pip 安装这些依赖项:
pip install aiohttp openai langchain
使用 asyncio 和 aiohttp 进行基本异步 LLM API 调用
让我们首先使用 aiohttp 对 LLM API 进行简单的异步调用。我们将使用 OpenAI 的 GPT-3.5 API 作为示例,但这些概念也适用于其他 LLM API。
import asyncio
import aiohttp
from openai import AsyncOpenAI
async def generate_text(prompt, client):
response = await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def main():
prompts = [
"Explain quantum computing in simple terms.",
"Write a haiku about artificial intelligence.",
"Describe the process of photosynthesis."
]
async with AsyncOpenAI() as client:
tasks = [generate_text(prompt, client) for prompt in prompts]
results = await asyncio.gather(*tasks)
for prompt, result in zip(prompts, results):
print(f"Prompt: {prompt}\nResponse: {result}\n")
asyncio.run(main())
在这个例子中,我们定义了一个异步函数 generate_text 使用 AsyncOpenAI 客户端调用 OpenAI API。 main 函数为不同的提示和用途创建多个任务 asyncio.gather() 同时运行它们。
这种方法使我们能够同时向 LLM API 发送多个请求,从而大大减少了处理所有提示所需的总时间。
批处理和并发控制
虽然上一个示例演示了异步 LLM API 调用的基础知识,但实际应用程序通常需要更复杂的方法。让我们探索两种重要技术:批处理请求和控制并发。
批量处理请求:处理大量提示时,将它们分批处理通常比为每个提示发送单独的请求更有效。这可以减少多次 API 调用的开销,并提高性能。
import asyncio
from openai import AsyncOpenAI
async def process_batch(batch, client):
responses = await asyncio.gather(*[
client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
) for prompt in batch
])
return [response.choices[0].message.content for response in responses]
async def main():
prompts = [f"Tell me a fact about number {i}" for i in range(100)]
batch_size = 10
async with AsyncOpenAI() as client:
results = []
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i+batch_size]
batch_results = await process_batch(batch, client)
results.extend(batch_results)
for prompt, result in zip(prompts, results):
print(f"Prompt: {prompt}\nResponse: {result}\n")
asyncio.run(main())
并发控制:虽然异步编程允许并发执行,但控制并发级别很重要,以避免 API 服务器不堪重负或超出速率限制。我们可以使用 asyncio.Semaphore 来实现此目的。
import asyncio
from openai import AsyncOpenAI
async def generate_text(prompt, client, semaphore):
async with semaphore:
response = await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def main():
prompts = [f"Tell me a fact about number {i}" for i in range(100)]
max_concurrent_requests = 5
semaphore = asyncio.Semaphore(max_concurrent_requests)
async with AsyncOpenAI() as client:
tasks = [generate_text(prompt, client, semaphore) for prompt in prompts]
results = await asyncio.gather(*tasks)
for prompt, result in zip(prompts, results):
print(f"Prompt: {prompt}\nResponse: {result}\n")
asyncio.run(main())
在这个例子中,我们使用信号量将并发请求的数量限制为 5,以确保不会使 API 服务器不堪重负。
异步 LLM 调用中的错误处理和重试
使用外部 API 时,实现强大的错误处理和重试机制至关重要。让我们增强代码以处理常见错误并实现重试的指数退避。
import asyncio
import random
from openai import AsyncOpenAI
from tenacity import retry, stop_after_attempt, wait_exponential
class APIError(Exception):
pass
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10))
async def generate_text_with_retry(prompt, client):
try:
response = await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except Exception as e:
print(f"Error occurred: {e}")
raise APIError("Failed to generate text")
async def process_prompt(prompt, client, semaphore):
async with semaphore:
try:
result = await generate_text_with_retry(prompt, client)
return prompt, result
except APIError:
return prompt, "Failed to generate response after multiple attempts."
async def main():
prompts = [f"Tell me a fact about number {i}" for i in range(20)]
max_concurrent_requests = 5
semaphore = asyncio.Semaphore(max_concurrent_requests)
async with AsyncOpenAI() as client:
tasks = [process_prompt(prompt, client, semaphore) for prompt in prompts]
results = await asyncio.gather(*tasks)
for prompt, result in results:
print(f"Prompt: {prompt}\nResponse: {result}\n")
asyncio.run(main())
该增强版本包括:
- API 相关错误的自定义 APIError 异常。
- 用@retry 从 tenacity 库修饰的 create _ text _ with _ retry 函数,实现了截断二进制指数避退算法。
- process_prompt 提示函数中的错误处理,以捕获和报告失败。
流式响应
对于长篇内容生成,流式响应可以显著提高应用程序的感知性能。您无需等待整个响应,而是可以在文本块可用时进行处理和显示。
import asyncio
from openai import AsyncOpenAI
async def stream_text(prompt, client):
stream = await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
stream=True
)
full_response = ""
async for chunk in stream:
if chunk.choices[0].delta.content is not None:
content = chunk.choices[0].delta.content
full_response += content
print(content, end='', flush=True)
print("\n")
return full_response
async def main():
prompt = "Write a short story about a time-traveling scientist."
async with AsyncOpenAI() as client:
result = await stream_text(prompt, client)
print(f"Full response:\n{result}")
asyncio.run(main())
此示例演示了如何流式传输来自 API 的响应,并在响应到达时打印每个块。此方法对于聊天应用程序或任何想要向用户提供实时反馈的场景特别有用。
使用 LangChain 构建异步工作流
对于更复杂的 LLM 应用程序, 浪链框架 提供高级抽象,简化链接多个 LLM 调用和集成其他工具的过程。让我们看一个使用具有异步功能的 LangChain 的示例:
此示例展示了如何使用 LangChain 创建具有流式传输和异步执行的更复杂的工作流。 AsyncCallbackManager 和 StreamingStdOutCallbackHandler 实现生成内容的实时流式传输。
import asyncio
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.callbacks.manager import AsyncCallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
async def generate_story(topic):
llm = OpenAI(temperature=0.7, streaming=True, callback_manager=AsyncCallbackManager([StreamingStdOutCallbackHandler()]))
prompt = PromptTemplate(
input_variables=["topic"],
template="Write a short story about {topic}."
)
chain = LLMChain(llm=llm, prompt=prompt)
return await chain.arun(topic=topic)
async def main():
topics = ["a magical forest", "a futuristic city", "an underwater civilization"]
tasks = [generate_story(topic) for topic in topics]
stories = await asyncio.gather(*tasks)
for topic, story in zip(topics, stories):
print(f"\nTopic: {topic}\nStory: {story}\n{'='*50}\n")
asyncio.run(main())
使用 FastAPI 提供异步 LLM 应用程序
为了使异步 LLM 应用程序可用作 Web 服务,FastAPI 是一个不错的选择,因为它原生支持异步操作。以下是如何创建用于文本生成的简单 API 端点的示例:
from fastapi import FastAPI, BackgroundTasks
from pydantic import BaseModel
from openai import AsyncOpenAI
app = FastAPI()
client = AsyncOpenAI()
class GenerationRequest(BaseModel):
prompt: str
class GenerationResponse(BaseModel):
generated_text: str
@app.post("/generate", response_model=GenerationResponse)
async def generate_text(request: GenerationRequest, background_tasks: BackgroundTasks):
response = await client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": request.prompt}]
)
generated_text = response.choices[0].message.content
# Simulate some post-processing in the background
background_tasks.add_task(log_generation, request.prompt, generated_text)
return GenerationResponse(generated_text=generated_text)
async def log_generation(prompt: str, generated_text: str):
# Simulate logging or additional processing
await asyncio.sleep(2)
print(f"Logged: Prompt '{prompt}' generated text of length {len(generated_text)}")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
此 FastAPI 应用程序创建一个端点 /generate 接受提示并返回生成的文本。它还演示了如何使用后台任务进行额外处理而不阻止响应。
最佳实践和常见陷阱
使用异步 LLM API 时,请牢记以下最佳实践:
- 使用连接池:当发出多个请求时,重用连接以减少开销。
- 实施正确的错误处理:始终考虑网络问题、API 错误和意外响应。
- 尊重速率限制:使用信号量或其他并发控制机制,避免 API 过载。
- 监视和记录:实施全面日志记录以跟踪性能并识别问题。
- 使用流媒体播放长篇内容:它提高了用户体验并允许提前处理部分结果。



















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











