



 本文介绍了一个项目,它涉及使用OpenCV连接和获取大华IP摄像头的图像,然后通过Python的requests库上传到基于flask的服务器进行yolov5目标识别。服务器接收到base64编码的图像后,解码并使用模型进行处理,结果再通过socket返回给本地。讨论了实现过程中的关键步骤,包括图像获取、上传、服务器处理和结果接收,以及性能优化的考虑。
本文介绍了一个项目,它涉及使用OpenCV连接和获取大华IP摄像头的图像,然后通过Python的requests库上传到基于flask的服务器进行yolov5目标识别。服务器接收到base64编码的图像后,解码并使用模型进行处理,结果再通过socket返回给本地。讨论了实现过程中的关键步骤,包括图像获取、上传、服务器处理和结果接收,以及性能优化的考虑。
前言
1.项目的需求是,本地连接IP摄像头,然后把图像上传到图像处理服务器器进行处理,得到的结果返回本地。
2.IP摄像头使用的是大华的摄像头,目标识别用的yolov5的模型,服务器用的是flask,实现语言是python。
3.在实现过程中,需要先进行IP摄像头的连接和图像的获取。可以使用OpenCV库来实现这一步骤。通过OpenCV库中的VideoCapture函数,可以连接到IP摄像头并获取图像。
4.获取到图像后,需要将其上传到图像处理服务器进行处理。可以使用Python中的requests库来实现图像上传功能。通过requests库中的post函数,可以将图像上传到服务器。
5.在服务器端,需要使用flask框架来实现图像处理功能。可以使用yolov5模型来进行目标识别。通过flask框架中的路由功能,可以将上传的图像进行处理,并将处理结果返回给本地。
6.最后,在本地端,需要使用Python中的socket库来实现图像结果的接收。通过socket库中的recv函数,可以接收到服务器返回的图像处理结果。
7.需要注意的是,在实现过程中,需要考虑到图像处理的时间和网络传输的延迟。可以通过优化算法和网络传输方式来提高系统的性能和响应速度。
一.连接摄像头
连接IP摄像头并以base64的方式上传到服务器是一种常见的操作,可以实现将摄像头拍摄的视频或图片数据传输到服务器上进行处理或存储。
首先定义了IP摄像头的地址,然后使用OpenCV库的VideoCapture函数打开摄像头。接着,使用循环读取视频流数据,并在每一帧数据上进行处理。在处理完视频帧后,使用OpenCV库的imencode函数将视频帧转换为JPEG格式的图像数据,并使用Python的base64库将图像数据编码为base64格式的字符串。最后,将base64编码的字符串上传到服务器。
在实际应用中,需要根据具体的需求对上传数据的格式和方式进行调整。例如,可以使用HTTP协议将数据上传到服务器,或者使用WebSocket协议实现实时数据传输。同时,还需要考虑数据的安全性和稳定性,比如使用SSL加密协议保护数据传输,或者使用缓冲区和重传机制保证数据的可靠性。
但这里只是一个简单的demo,如果要应用到项目上,则要考虑以上的各种因素。
import cv2
import datetime
import time
import requests
import base64
import numpy as np
def image_to_base64(image_np):
image = cv2.imencode('.jpg', image_np)[1]
base64_data = str(base64.b64encode(image))[2:-1]
return base64_data
def base64_to_image(base64_code):
img_data = base64.b64decode(base64_code)
img_array = np.frombuffer(img_data, np.uint8)
img = cv2.imdecode(img_array, cv2.COLOR_RGB2BGR)
return img
class Camera_picture:
def __init__(self):
self.user = "admin"
self.pwd = "dahua12345"
self.ip = "192.168.0.xxx:xxx"
self.file_path = "./"
self.name = "camera"
def dahua(self):
video_stream_path = f"rtsp://{self.user}:{self.pwd}@{self.ip}/cam/realmonitor?channel=1&subtype=0"
cap = cv2.VideoCapture(video_stream_path) # 连接摄像头
print('IP camera open : {}'.format(cap.isOpened()))
return cap
def timing_screenshot(self):
cap = self.dahua()
if cap.isOpened():
cv2.namedWindow(self.name, flags=cv2.WINDOW_FREERATIO)
last_time = datetime.datetime.now()
while(True):
ret, frame = cap.read()
frame = cv2.resize(frame, (500, 300))
cv2.imshow(self.name, frame)
cur_time = datetime.datetime.now()
name = self.file_path + str(time.time()) + ".jpg"
if (cur_time - last_time).seconds >= 10:
cv2.imwrite(name, cap.read()[1])
last_time = cur_time
print("Image saved successfully!")
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
else:
print("Camera connection failed. Please check the configuration!")
def manual_screenshot(self):
cap = self.dahua()
if cap.isOpened():
cv2.namedWindow(self.name, flags=cv2.WINDOW_FREERATIO)
while(True):
ret, frame = cap.read()
frame = cv2.resize(frame, (500, 300))
cv2.imshow(self.name, frame)
event = cv2.waitKey(1) & 0xFF
if event == ord('s'): # 按"S"截取图片
name = self.file_path + str(time.time()) + ".jpg"
cv2.imwrite(name, cap.read()[1])
print("Screen saved successfully!")
elif event == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
else:
print("Camera connection failed. Please check the configuration!")
def get_video_stream(self):
cap = self.dahua()
if cap.isOpened():
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
# fourcc = int(cap.get(cv2.CAP_PROP_FOURCC))
# FourCC 是用于指定视频编解码器的4字节代码
# fourcc = cv2.VideoWriter_fourcc(*"MJPG")
# writer = cv2.VideoWriter(f"{self.file_path}{str(time.time())}.mp4", fourcc, fps, (width, height))
while(True):
ret, frame = cap.read()
if not ret: # 返回False退出循环
break
# writer.write(frame) # 视频保存
# frame = cv2.resize(frame, (500, 300))
# cv2.imshow(self.name, frame)
img_code = image_to_base64(frame)
data = {'img': img_code}
resp = requests.post("http://127.0.0.1:5004/camera_input", data=data)
print(resp.content)
if 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
else:
print("Camera connection failed. Please check the configuration!")
def read_video(self,):
cap = self.dahua()
if cap.isOpened():
key_frame = 2
j = 0
while True:
if key_frame >= 1:
cap.set(cv2.CAP_PROP_POS_FRAMES, j)
j += key_frame
hasFrame, frame = cap.read()
if not hasFrame:
break
img_code = image_to_base64(frame)
data = {'img': img_code}
resp = requests.post("http://127.0.0.1:5004/camera_input", data=data)
print(resp.content)
# cv2.imshow('show', frame)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
if __name__ == '__main__':
run = Camera_picture()
# run.timing_screenshot()
# run.get_video_stream()
# run.manual_screenshot()
run.read_video()
二、目标识别
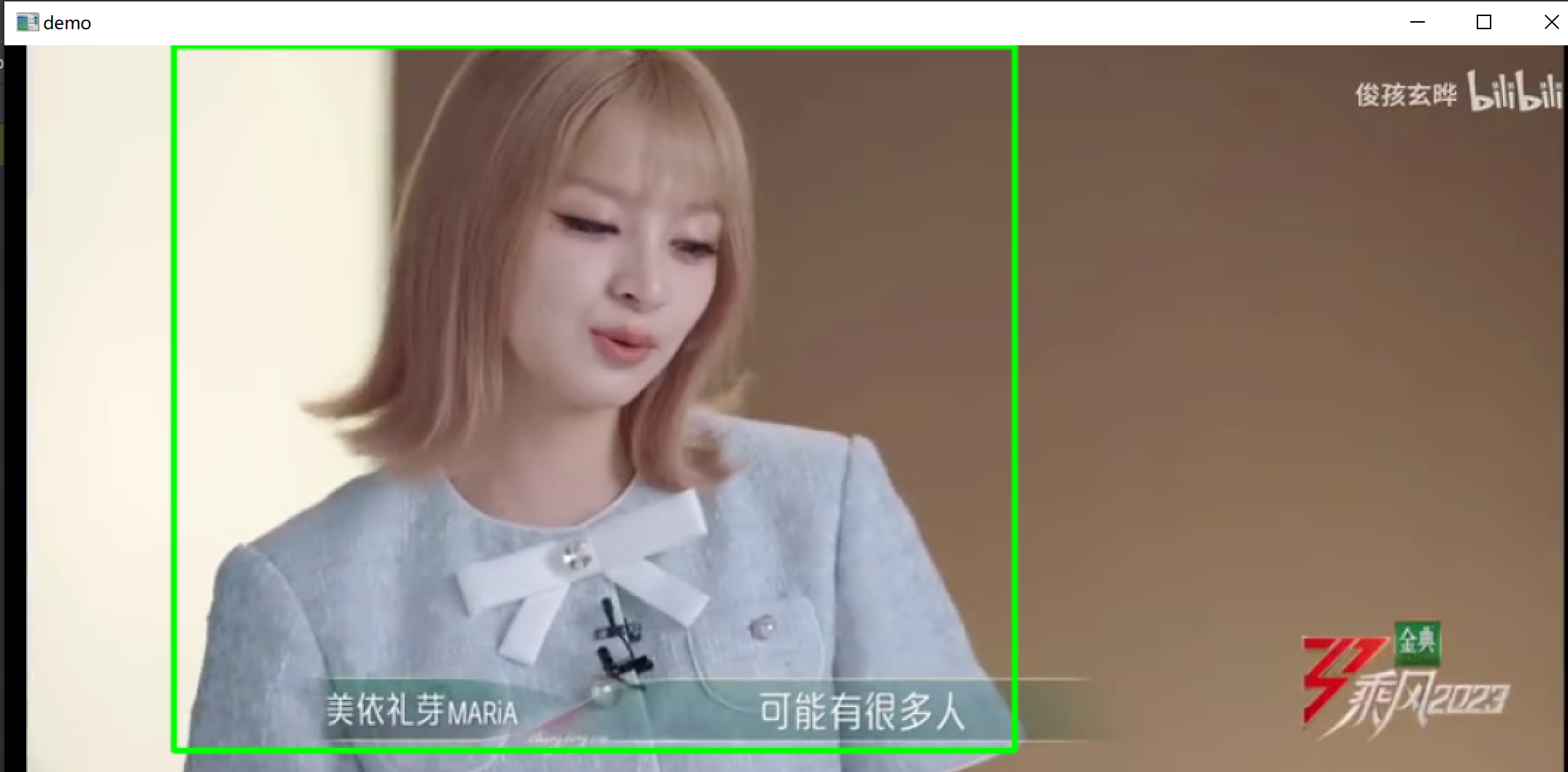
这里用来演示的目标识别是git上一个开源代码,可以到这个里下载代码:https://github.com/Sharpiless/Yolov5-deepsort-inference
下载代码,配置下环境,然后运行python demo.py,代码运行效果如下:
三、服务器端
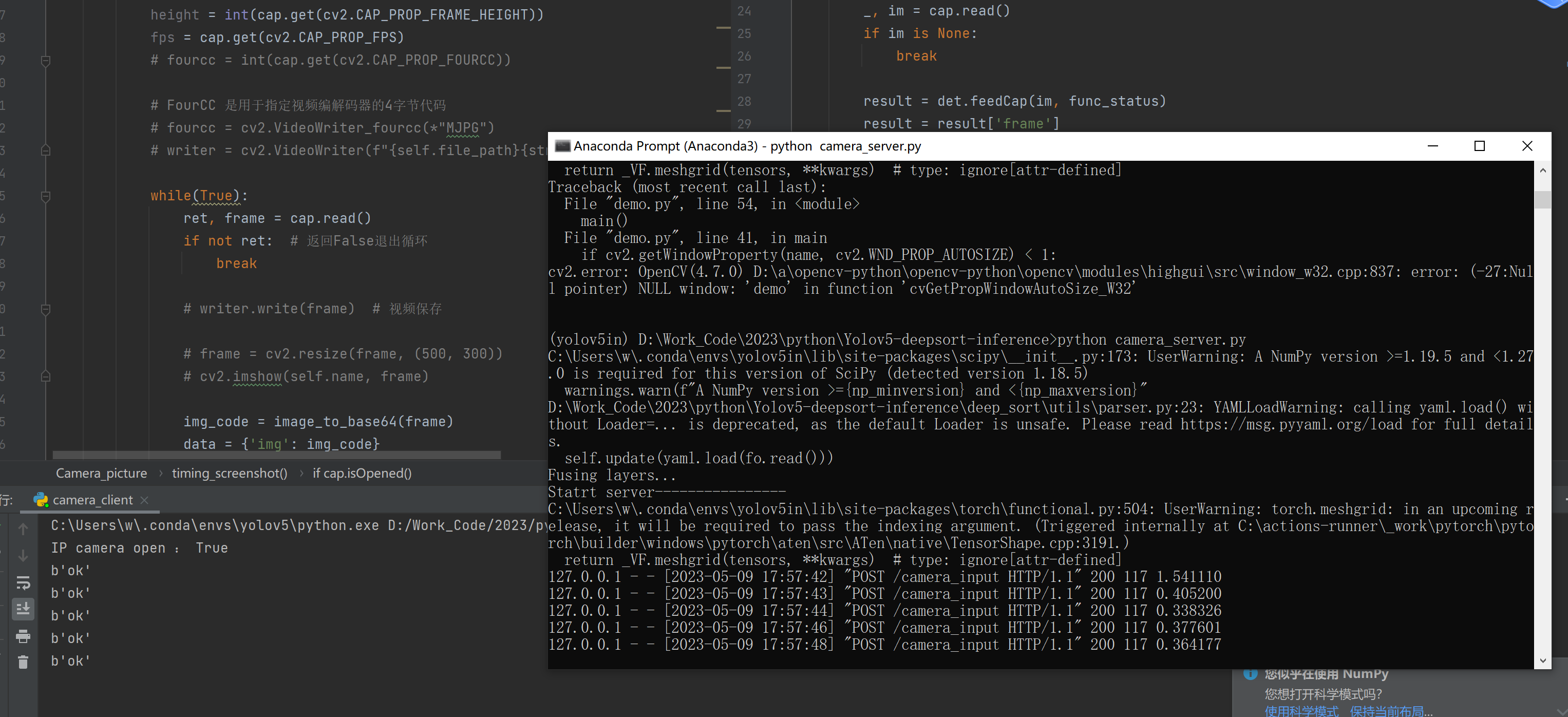
服务端的代码是接收到数据流之后,进行解码操作,然后使用yolov5模型进行推理。这个过程可以分为以下几个步骤:
1. 接收数据流:服务端通过网络接口接收客户端发送的数据流。
2. 解码数据流:服务端对接收到的数据流进行解码操作,将其转换为图像数据。
3. 模型推理:服务端使用yolov5模型对预处理后的图像数据进行推理,得到目标检测结果。
需要注意的是,服务端的代码需要具备高效的数据处理能力和模型推理能力,以保证实时性和准确性。同时,服务端的代码还需要考虑并发处理和多线程处理等问题,以提高系统的吞吐量和并发性能。
from flask import Flask, request
import base64
import numpy as np
from gevent import pywsgi
import cv2, argparse
import imutils
from AIDetector_pytorch import Detector
det = Detector()
func_status = {}
func_status['headpose'] = None
app = Flask(__name__)
@app.route('/camera_input', methods=['POST'])
def camera_input():
if request.method == 'POST':
input_data = request.form.get('img')
cv_img = base64_to_image(input_data)
result = det.feedCap(cv_img, func_status)
result = result['frame']
result = imutils.resize(result, height=500)
cv2.imshow('src',result)
cv2.waitKey(24)
return 'ok'
def image_to_base64(image_np):
image = cv2.imencode('.jpg', image_np)[1]
base64_data = str(base64.b64encode(image))[2:-1]
return base64_data
def base64_to_image(base64_code):
img_data = base64.b64decode(base64_code)
img_array = np.frombuffer(img_data, np.uint8)
img = cv2.imdecode(img_array, cv2.COLOR_RGB2BGR)
return img
if __name__ == "__main__":
print('Statrt server----------------')
server = pywsgi.WSGIServer(('127.0.0.1', 5004), app)
server.serve_forever()




















 2064
2064








 到【灌水乐园】发言
到【灌水乐园】发言









