




 本文综述了基于鸟瞰(BEV)视角的自动驾驶感知技术,重点介绍了仅使用摄像头进行语义分割的方法,探讨了不同架构如Transformer在网络中的应用,并讨论了多模态融合方案及其在3D目标检测等任务中的表现。
本文综述了基于鸟瞰(BEV)视角的自动驾驶感知技术,重点介绍了仅使用摄像头进行语义分割的方法,探讨了不同架构如Transformer在网络中的应用,并讨论了多模态融合方案及其在3D目标检测等任务中的表现。
一、Introdution
Why BEV
- 高度信息在自动驾驶中并不重要,BEV视角可以表达自动驾驶需要的大部分信息.
- BEV空间可以大致看作3D空间.
- BEV representation有利于多模态的融合
- 可解释性强,有助于对每一种传感器模态调试模型
- 扩展其它新的模态很方便
- BEV representation有助于下游的prediction和planning任务
- BEV语义分割依赖于朝向不同的多摄像头,比SALM只朝一个方向获取语义更丰富;通知在ego运动速度慢的时候也能work.
- 在纯视觉系统(无雷达或激光雷达)中,几乎必须在BEV中执行感知任务,因为传感器融合时没有其它3D观测可用于视图转换
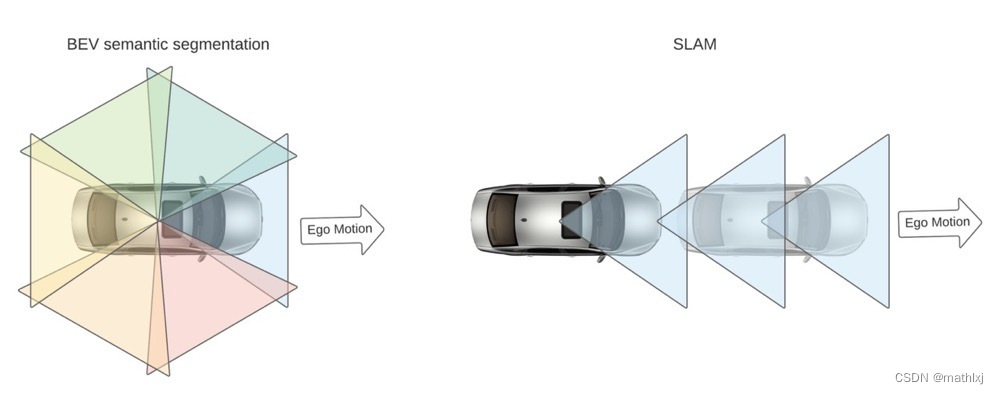
BEV的难点
- 视角变换。为了得到BEV representation,算法需要利用
- 先验的几何信息,包括相机的内参和外参(可能有噪声)
- soft priors:路面布局的信息库
- common sense:车在BEV视角下不会overlap.
- 数据获取与标注。
- 人手工标注
- 使用一些人造的数据
- 单目的相机获取图像上从3D到2D的映射图像,但是从2D提升到3D本身就是个ill-posed problem(解不唯一).
分类法
- 监督/indirect supervision
- 3D目标检测/扫图/预测/语义分割
- 输入: 单张图像/多张图像/仅雷达/图像+雷达/其它传感器融合
任务拓展
一些较新的数据集,例如(Lyft, Nuscenes, Argoverse),提供了
- 3D检测框
- HD map
- ego在每个时间戳时在HD map的位置
BEV的语义分割分为静态(道路布局)语义分割和动态实例分割,因此可以基于ego定位的结果,将静态的map映射到ego坐标系
视角变换的主要方法
- 逆透视变换(IPM, Inverse Perspective Mapping),例如Cam2BEV。假设地面上平的,一般只用在车道线检测或free space检测。
- Lift-splat。例如Lift, Splat, Shoot;BEV-Seg;CaDDN;FIERY。先估计深度信息,将图像提升到类似于3D点云,再splat得到BEV视角特征
- MLP。使用MLP直接对变换矩阵进行预测,例如VPN,HDMapNet
- Transformer。基于attention的transformer来建模视角的变换,最近论文比较多。
二、仅摄像头X语义分割
VPN (IROS 2020)
-
输入:多模态,主要是多视角的图像
-
输出:语义分割
VPN (Cross-view Semantic Segmentation for Sensing Surroundings)几乎是第一个探索BEV语义分割的任务。
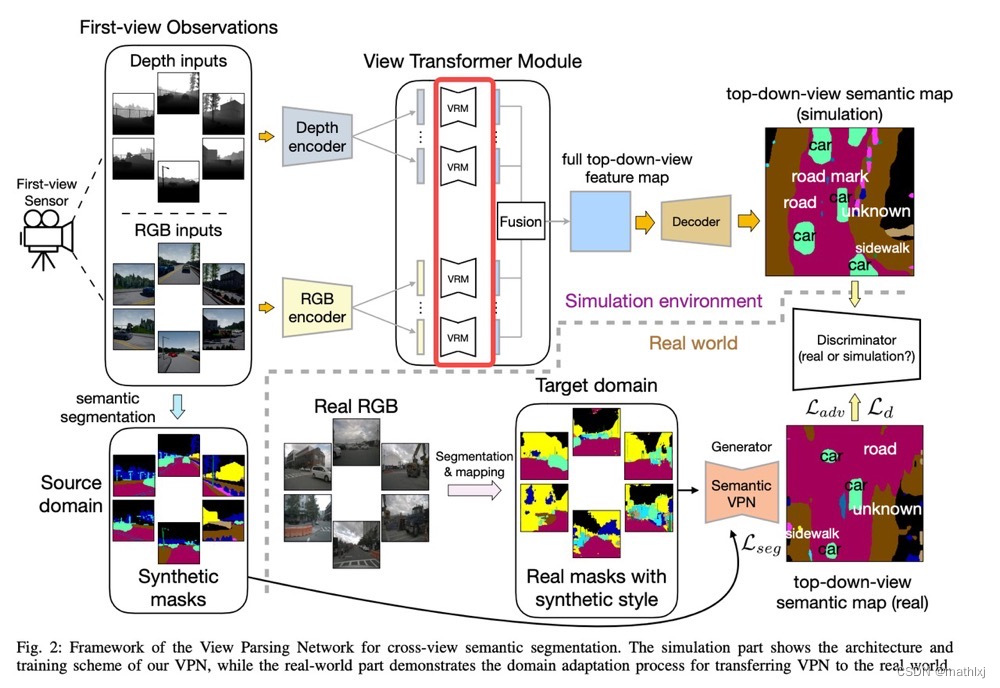
-
VPN 对每个模态的每个输入经encoder得到的feature map,经过不同的MLP回归从原始view到BEV视角的映射矩阵R_i(View transformer)。当然,不足之处是也忽略了feature点与点之间的位置关系。
-
使用人造的数据和对抗损失来训练。
-
View transformer:输入(原视角)与输出(BEV视角)尺寸相同。(实际上是没必要的)
Cam2BEV (ITSC 2020)
A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View
-
输入:4个摄像头
-
输出:语义分割
Cam2BEV 使用一个space trasnformer module with IPM(Inverse Perspective Mapping)来将原视角的feature映射到BEV空间。
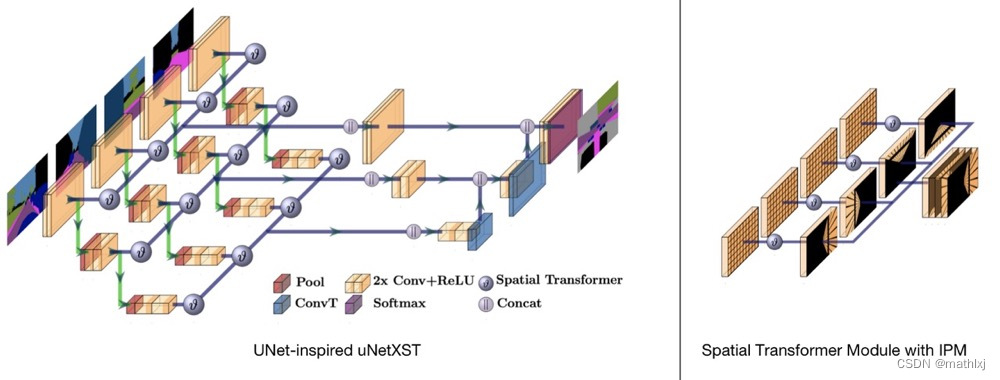
-
主干网络借鉴了uNet的思想
-
对ground truth做预处理,来生成被遮挡的部分为一类。
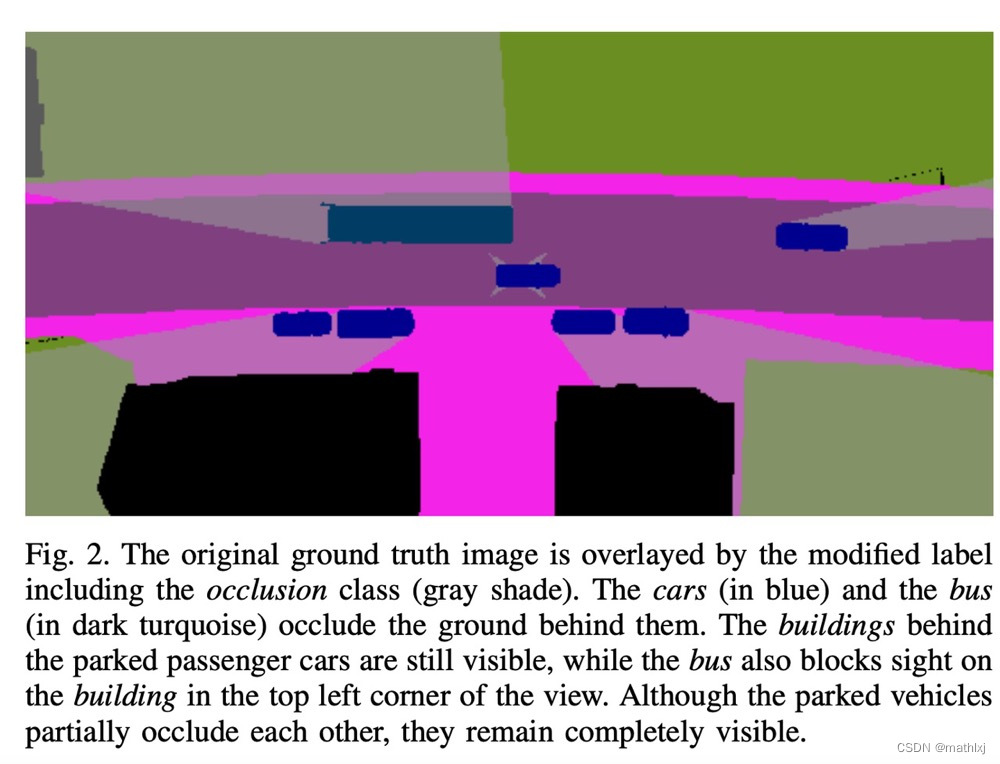
-
Spatial Transformer Module
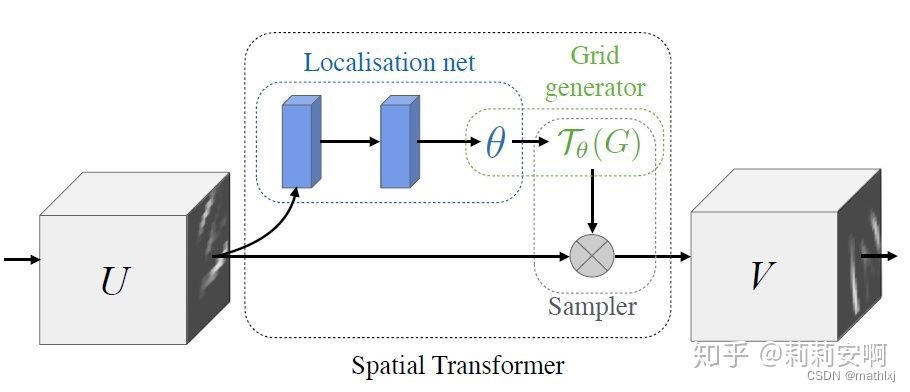
- Localisation Network-局部网络,由输入特征图回归变换矩阵
- Parameterised Sampling Grid-参数化网格采样,得到输出特征图的坐标点对应的输入特征图的坐标点的位置
- Differentiable Image Sampling-差分图像采样,利用插值方式来计算出对应点的灰度值
-
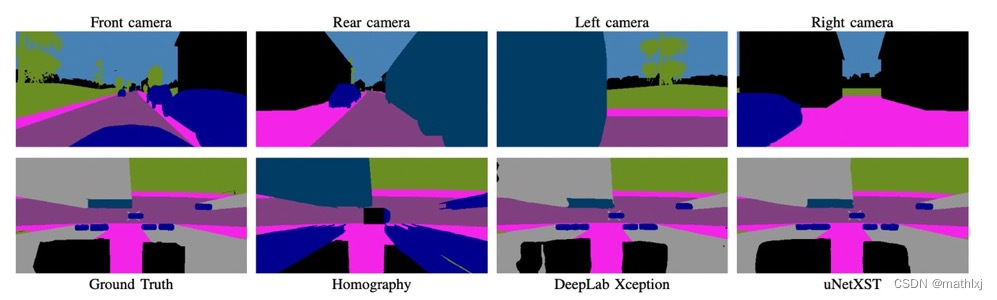
直接用四个相机的语义分割结果作为输入,类别有road, sidewalk, person, car, truck, bus,
bike, obstacle, vegetation.
MonoLayout(WACV 2020)
MonoLayout: Amodal scene layout from a single image
-
输入:单个摄像头
-
输出:语义分割,道路和交通参与者
-
Shared encoder,分两个decoder,一个用来做静态语义分割,一个做动态语义分割
-
对KITTI数据集使用temporal sensor fusion生成一些weak groundtruth,通过结合2D语义分割结果和位置信息
-
对抗学习损失,静态分割head的先验数据分布来自公开数据集OpenStreetMap,属于unpaired fashion.
PyrOccNet (CVPR 2020)
Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks
-
输入:多个摄像头
-
输出:语义分割,道路、交通参与者、障碍物
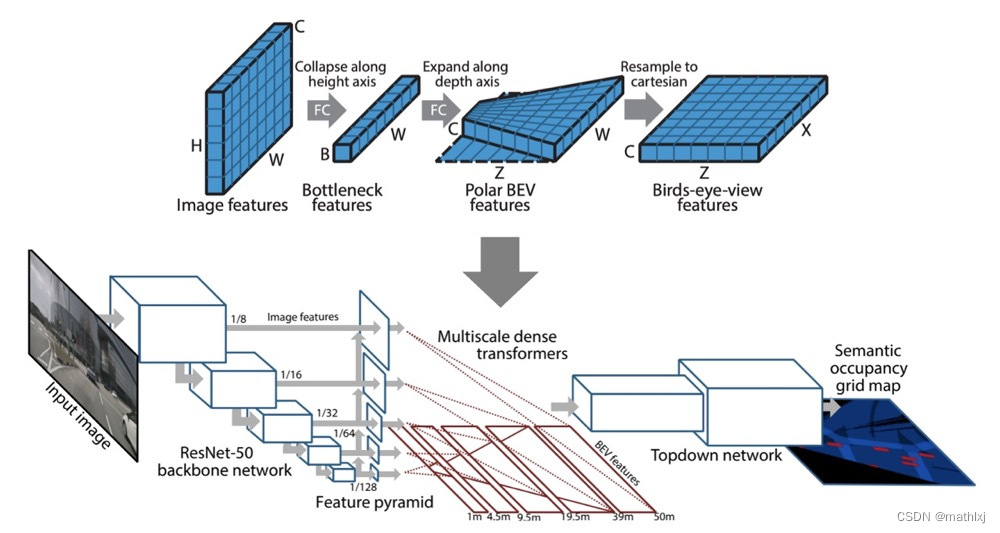
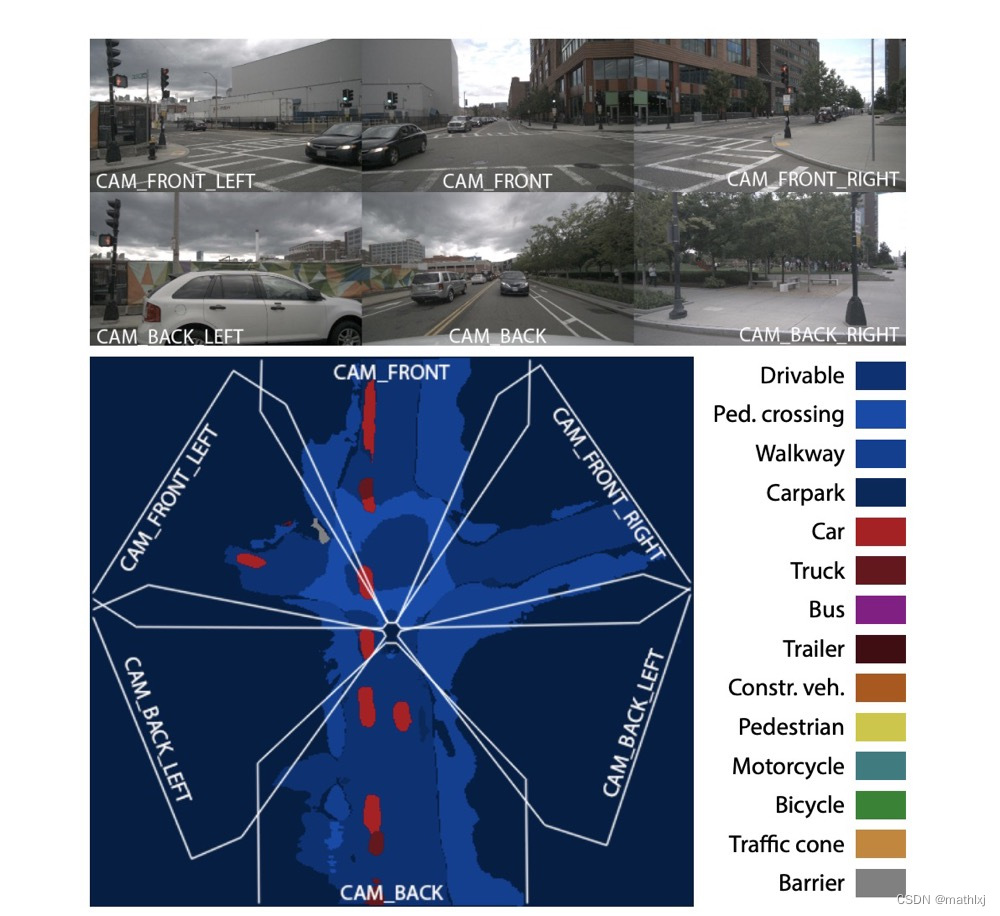
-
Semantic occupancy grid prediction:与2D图像的语义分割类似,预测 m i c m_i^c mic,即第c类占据第i个grid的概率
-
dense transformer module,use of both camera geometry and fully-connected reasoning to map features from the image to the BEV space。这里feature map的size不一定一致了,输入为
H × W × C H\times W \times C H×W×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









