







 本文详细介绍了PySpark中DataFrame的数据结构,特别是Row和Column对象的理解与操作函数,包括数据转换、排序、筛选等常见操作,旨在帮助读者从Pandas平滑过渡到PySpark。
本文详细介绍了PySpark中DataFrame的数据结构,特别是Row和Column对象的理解与操作函数,包括数据转换、排序、筛选等常见操作,旨在帮助读者从Pandas平滑过渡到PySpark。
目录
前言
如果之前不接触python的pandas我觉得上手pyspark会更快,原因在于pandas的dataframe操作API实在是好用,功能代码使用简便而且容易理解,相对于pyspark中的sql.dataframe就显得十分出色了。sql.dataframe数据类型的底层构造是完全和python中pandas完全不同的,而是强关联与spark的dataframe,二者有本质的区别,当然函数功能操作也是有很大的不同。而spark数据处理的还是针对于基础RDD数据集去操作分布式计算,因此理解pyspark的核心还是在于如何针对RDD去做基础处理,而其关键点在于处理RDD的Row和Dataframe的Column。
因此对于能够熟练的使用pyspark这门工具归根结底还得在RDD和Row操作上面下手,如果能够将这些工具都使用的相当熟练的话,那必定是一名优秀的大数据工程师。故2023年这一年的整体学习重心都会集中在这门pyspark技术上,当然Pandas以及Numpy的专栏都会更新。我将对PySpark专栏给予极大的厚望,能够实现从Pandas专栏过度到PySpark专栏零跨度学习成本,敬请期待。
一、Row对象理解
对于任何pyspark的理解都可以先理解一遍spark的基本数据类型,因为二者的关系是相同的。DataFrame内存存储的是row对象,也就是DataFrame的每一条记录都是row类型的。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息都用Row来表示。
通过创建一个dataframe我们就知道:
pd_df=pd.DataFrame(
{'name':['id1','id2','id3','id4'],
'old':[21,23,22,35],
'city':['杭州','北京','南昌','上海']
},
index=[1,2,3,4])
pd_df
spark = SparkSession.builder.getOrCreate()
sp_df=spark.createDataFrame(pd_df)
sp_df.rdd.collect()
sp_df.sort(sp_df.old.desc()).collect() 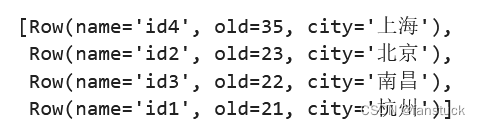
总体而言操作Row一般都为全体操作,取得dataframe一般都是通过spark.sql(sql)直接获取到dataframe,在一些其他情况下需要对Row进行拆分配对。
pyspark提供了操作Row的API可以实现简单功能。
二、Row操作函数
Row获取其值可以有两种方法,这两种和pandas的dataframe获取类似:
1. (row.key)
sp_df.rdd.map(lambda x: (x.city)).collect()2. row[key]
sp_df.rdd.map(lambda x: (x['city'])).collect()这二者效果是一样的:

Row可用于通过使用命名参数创建行对象。不允许省略命名参数来表示该值为None或缺失。在这种情况下,应将其显式设置为None。
创建一个Row:
from pyspark.sql import *
Person = Row("name", "age")
Person("Alice", 11) 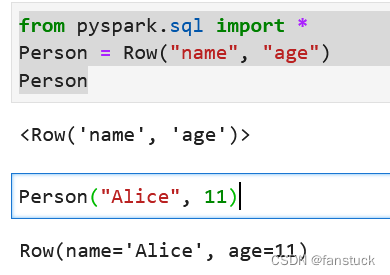
1.asDict
Row.asDict(recursive: bool = False) → Dict[str, Any]DataFrame和dict可以互相转化,故Row转换为单个dict也容易理解。
Row(name="Alice", age=11).asDict() == {'name': 'Alice', 'age': 11}
2.count
统计计数:
Person("Alice", 11).count("Alice") 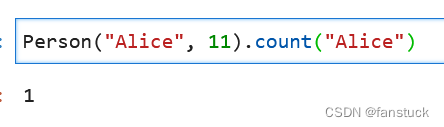
三、Column对象理解
如其意,在DataFrame对象中就指代一列的意思,和pandas的Clolumn是类似的,功能也是差不多。

sp_df.columns 
关于列的操作还是很多的,这涉及到DataFrame的细化处理,也是主要用于处理的对象。
四、Column操作函数
1.alias别名
Column.alias(*alias: str, **kwargs: Any) → pyspark.sql.column.Column返回此列的别名为一个或多个新名称(对于返回多个列的表达式,如分解)。
sp_df.select(sp_df.state.alias("state_stuck")).show() 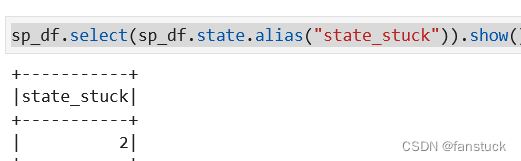
2.asc升序
Column.asc() → pyspark.sql.column.Column根据列的升序返回排序表达式。
sp_df.select(sp_df.times).orderBy(sp_df.times.asc()).show() 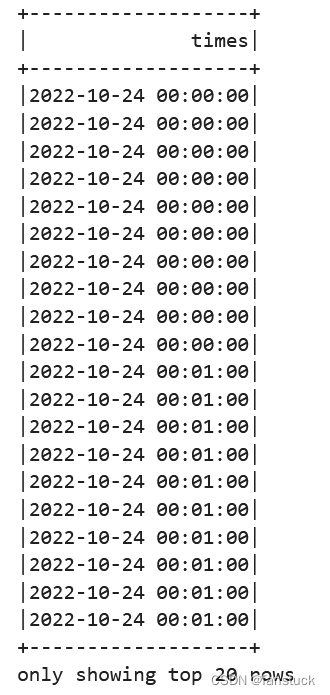
3.asc_nulls_first空值前置升序
Column.asc_nulls_first() → pyspark.sql.column.Column根据列的升序返回排序表达式,并且在非空值之前返回空值。
和上面的结果相比也就是先将空值提出排到前面,后面一样升序排列。
4.asc_nulls_last空值后置升序
Column.asc_nulls_last() → pyspark.sql.column.Column根据列的升序返回排序表达式,非空值后出现空值。
和上面的结果相比也就是先将空值提出排到后面,后面一样升序排列。
5.astype数据类型转换
老常用函数了,用于转换列数据类型:
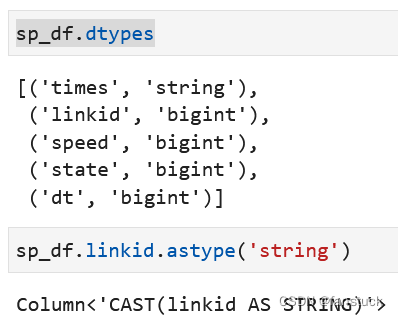
6.between范围筛选
Column.between(lowerBound: Union[Column, LiteralType, DateTimeLiteral, DecimalLiteral],
upperBound: Union[Column, LiteralType, DateTimeLiteral, DecimalLiteral])
→ Column如果当前列介于下限和上限之间(包括下限和上限),则为True。
sp_df.select(sp_df.linkid, sp_df.state.between(3, 5)).show() 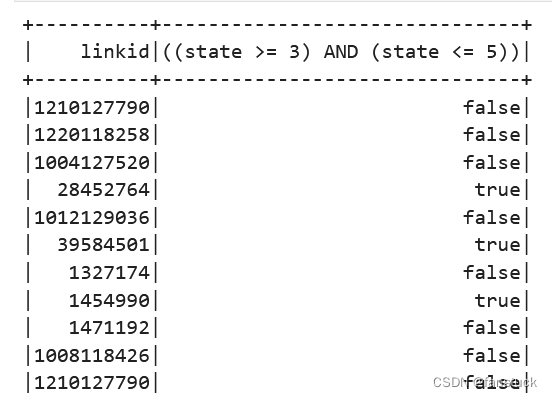
7.bitwiseAND位运算and
Column.bitwiseAND(other: Union[Column,LiteralType, DecimalLiteral, DateTimeLiteral]) → Column用另一个表达式计算此表达式的位AND。
from pyspark.sql import Row
df = spark.createDataFrame([Row(a=170, b=75)])
df.select(df.a.bitwiseAND(df.b)).collect() 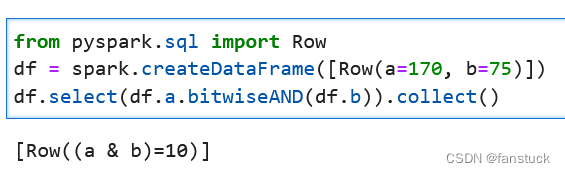
8.bitwiseOR位运算or
Column.bitwiseOR(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral]) → Column用另一个表达式计算此表达式的位OR。
from pyspark.sql import Row
df = spark.createDataFrame([Row(a=170, b=75)])
df.select(df.a.bitwiseOR(df.b)).collect() 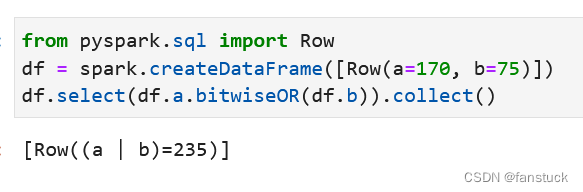
9. bitwiseXOR位运算^
Column.bitwiseXOR(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral]) → Column计算此表达式与另一个表达式的位XOR。
from pyspark.sql import Row
df = spark.createDataFrame([Row(a=170, b=75)])
df.select(df.a.bitwiseXOR(df.b)).collect() 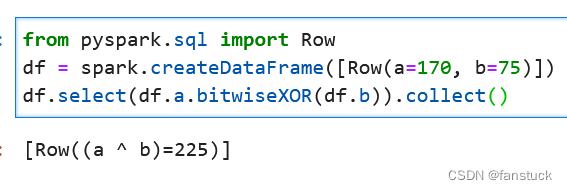
10.cast强制转换
Column.cast(dataType: Union[pyspark.sql.types.DataType, str])
→ pyspark.sql.column.Column将列强制转换为dataType类型。
sp_df.select(sp_df.linkid.cast("string").alias('linkid_str')).show()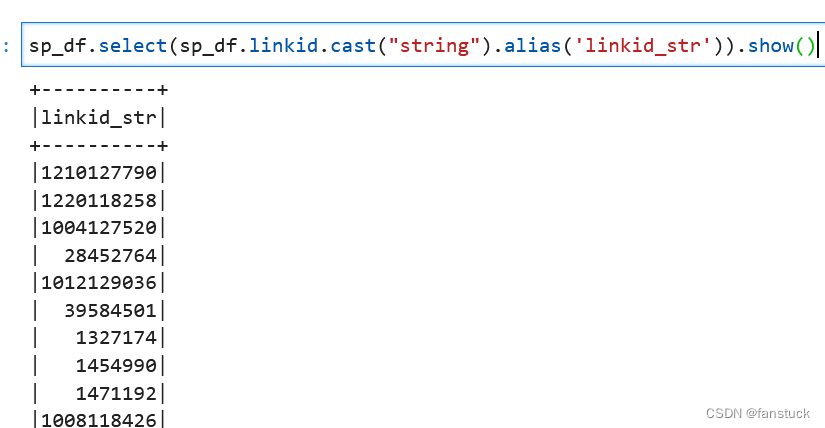
11.contains包含筛选
Column.contains(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral])
→ Column包含其他元素。基于字符串匹配返回布尔列。
例如查找状态包含2的所有数据:
sp_df.filter(sp_df.state.contains('2')).collect()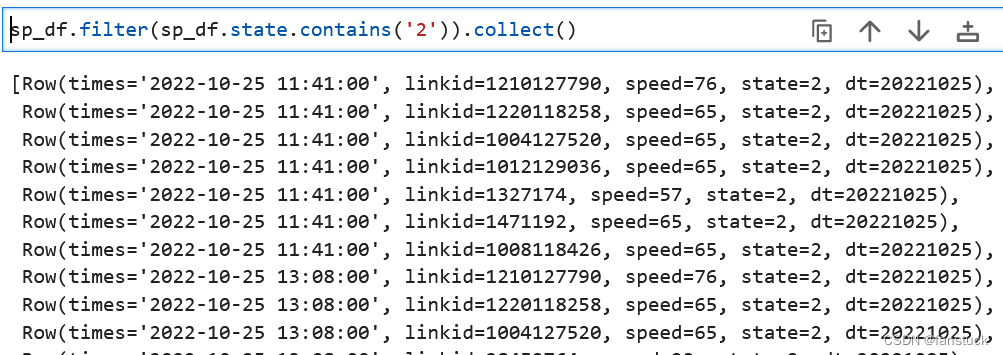
12.desc降序
Column.desc() → pyspark.sql.column.Column根据列的降序返回排序表达式。
sp_df.select(sp_df.speed).orderBy(sp_df.speed.desc()).show() 
13.desc_nulls_first空值前置降序
上同asc_nulls_first
14.desc_nulls_last空值后置降序
上同desc_nulls_last
15.dropFields删除列
Column.dropFields(*fieldNames: str) → pyspark.sql.column.Column按名称删除StructType中字段的表达式。如果架构不包含字段名,则这是一个no op。
from pyspark.sql.functions import col, lit
df = spark.createDataFrame([
Row(a=Row(b=1, c=2, d=3, e=Row(f=4, g=5, h=6)))])
df.withColumn('a', df['a'].dropFields('b')).show() 
此方法支持直接删除多个嵌套字段
df.withColumn("a", col("a").dropFields("e.g", "e.h")).show()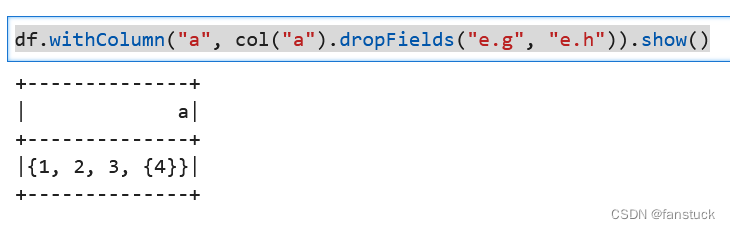
但是,如果要添加/替换多个嵌套字段,则最好在添加/替换多重字段之前提取嵌套结构。
df.select(col("a").withField(
"e", col("a.e").dropFields("g", "h")).alias("a")
).show() 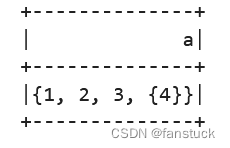
16.endswith匹配尾字符
Column.endswith(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral]) → Column字符串以结尾。基于字符串匹配返回布尔列。
sp_df.filter(sp_df.dt.endswith('25')).collect()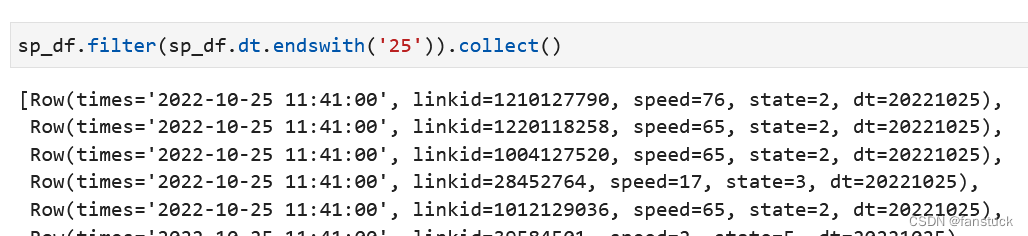
17.eqNullSafe空值检测
Column.eqNullSafe(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral]) → Column对空值的相等测试。
df1 = spark.createDataFrame([
Row(id=1, value='foo'),
Row(id=2, value=None)
])
df1.select(
df1['value'] == 'foo',
df1['value'].eqNullSafe('foo'),
df1['value'].eqNullSafe(None)
).show() 
18.getField获取字段
Column.getField(name: Any) → pyspark.sql.column.Column通过StructType中的名称获取字段的表达式。
df = spark.createDataFrame([Row(r=Row(a=1, b="b"))])
df.select(df.r.getField("b")).show() 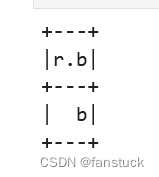
和一下的这个索引是一样的效果:
df.select(df.r.a).show()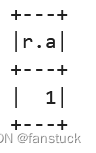
19.getItem获取对象
Column.getItem(key: Any) → pyspark.sql.column.Column[source]一种表达式,它从列表中的序号位置获取项,或从字典中按关键字获取项。
df = spark.createDataFrame([([1, 2], {"key": "value"})], ["l", "d"])
df.show() 
df.select(df.l.getItem(0), df.d.getItem("key")).show() 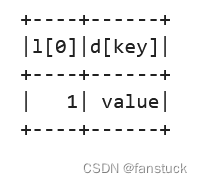
20.ilike匹配
Column.ilike(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral]) → ColumnSQL ILIKE表达式(不区分大小写LIKE)。基于不区分大小写的匹配返回布尔列。
sp_df.filter(sp_df.times.ilike('%00:08:00')).show() 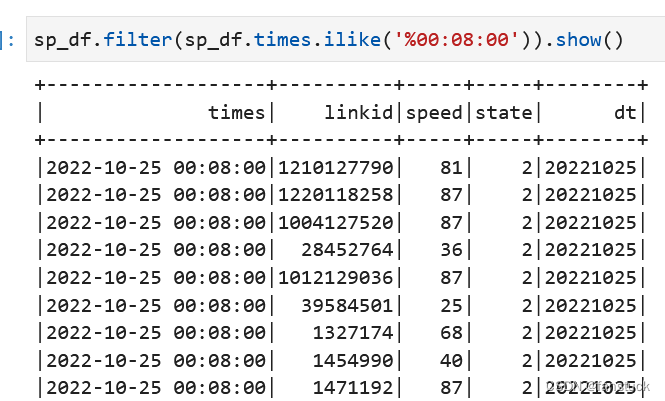
21.isNotNull不为空判断
Column.isNotNull() → pyspark.sql.column.Column如果当前表达式不为空,则为True。
df = spark.createDataFrame([Row(name='Tom', height=80), Row(name='Alice', height=None)])
df.filter(df.height.isNotNull()).collect()
22.isNull为空判断
如果当前表达式为空,则为True。
df = spark.createDataFrame([Row(name='Tom', height=80), Row(name='Alice', height=None)])
df.filter(df.height.isNull()).collect()[Row(name='Alice', height=None)]
23.isin包含
Column.isin(*cols: Any) → pyspark.sql.column.Column一个布尔表达式,如果此表达式的值包含在参数的计算值中,则计算为true。
查询DataFrame某列在某些值里面的内容,等于SQL IN ,如 where year in(‘2017’,‘2018’)
sp_df[sp_df.state.isin('1','2')].show() 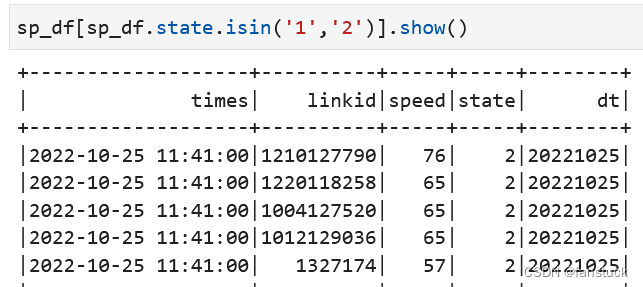
24.like包含
Column.like(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral]) → Column类似SQL的表达式。返回基于SQL LIKE匹配的布尔列。
sp_df.filter(sp_df.times.like('%08:00:00')).show() 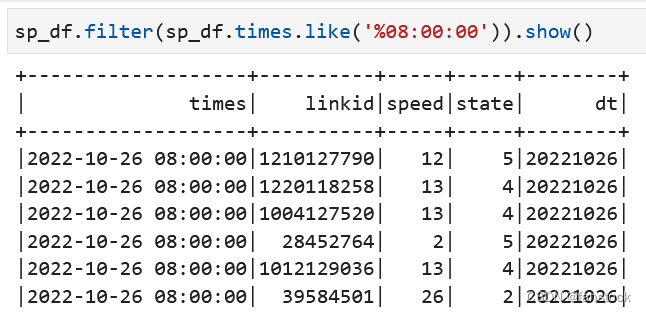
25.otherwise等于else
Column.otherwise(value: Any) → pyspark.sql.column.Column计算条件列表并返回多个可能的结果表达式之一。如果未调用Column.otherwise(),则为不匹配的条件返回None。
from pyspark.sql import functions as F
sp_df.select(sp_df.linkid, F.when(sp_df.state > 2, 'red').otherwise('green')).show()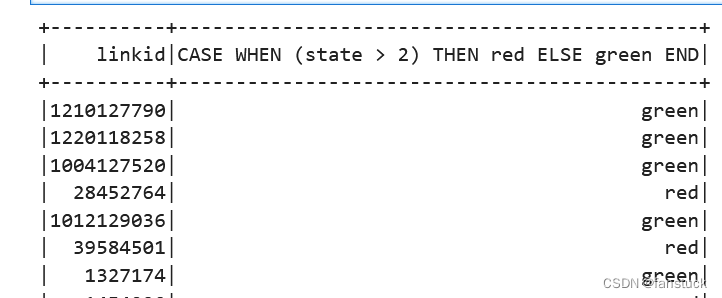
26.over窗口
Column.over(window: WindowSpec) → Column定义窗口列。
27.rlike正则匹配
Column.rlike(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral]) → ColumnSQL RLIKE表达式(带Regex的LIKE)。基于正则表达式匹配返回布尔列。
sp_df.filter(sp_df.times.rlike('(08.{6,})')).show() 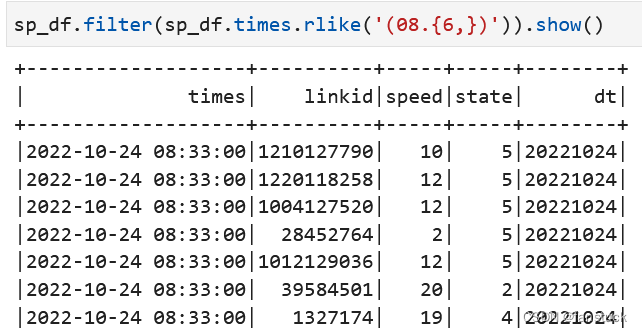
28.startswith匹配头项
Column.startswith(other: Union[Column, LiteralType, DecimalLiteral, DateTimeLiteral])
→ Column字符串以开头。基于字符串匹配返回布尔列。
sp_df.filter(sp_df.times.startswith('2022-10-27')).show() 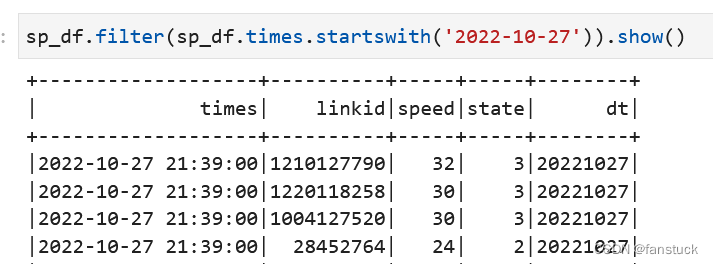
29.substr截取字符
Column.substr(startPos: Union[int, Column], length: Union[int, Column])
→ pyspark.sql.column.Column返回列的子字符串Column。
sp_df.select(sp_df.times.substr(1,10).alias('dt')).show() 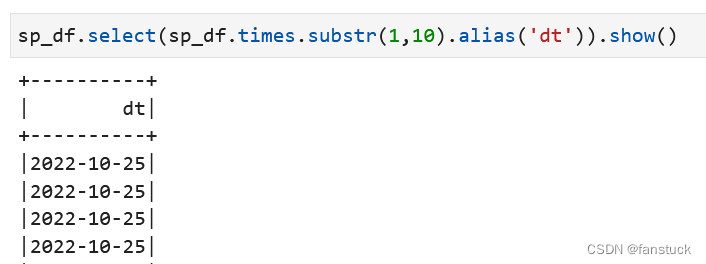
30.when条件筛选
Column.when(condition: pyspark.sql.column.Column, value: Any)
→ pyspark.sql.column.Column计算条件列表并返回多个可能的结果表达式之一。如果未调用Column.otherwise(),则为不匹配的条件返回None。
这个在上文的时候已经用到了:
from pyspark.sql import functions as F
sp_df.select(sp_df.linkid, F.when(sp_df.state > 2, 'red').otherwise('green')).show()31.withField
Column.withField(fieldName: str, col: pyspark.sql.column.Column)
→ pyspark.sql.column.Column按名称添加/替换StructType中字段的表达式。
df = spark.createDataFrame([Row(a=Row(b=1, c=2))])
df.withColumn('a', df['a'].withField('b', lit(3))).select('a.b').show() 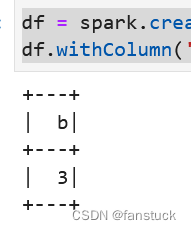
至此所有的pyspark.sql.Row和Column的函数操作都写完了。最主要的还是得运用到项目上去简化代码,实现想要的效果,这需要反复使用联系熟练,才能完成复杂计算的项目。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。



















 2967
2967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











