




 本文详细介绍了Scrapy框架的使用,包括安装、开发流程、pipelines管道原理、框架结构,以及中间件的定制和实际应用案例。通过实例解析了Scrapy在处理爬虫请求、响应、数据提取及存储等方面的关键操作。
本文详细介绍了Scrapy框架的使用,包括安装、开发流程、pipelines管道原理、框架结构,以及中间件的定制和实际应用案例。通过实例解析了Scrapy在处理爬虫请求、响应、数据提取及存储等方面的关键操作。
一、scrapy简介
Scrapy 是用纯 Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架, 用途非常广泛
Scrapy 使用了 Twisted(其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快 我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成 各种需求
(1)、下载scrapy
pip install scrapy
二、scrapy开发流程
1、新建项目
scrapy startproject 项目名
2、新建spider–爬虫模板
先进入项目目录下
命令:scrapy genspider [py文件的名称] [spider爬取的网址]
文件中属性的含义:

3、更改配置-settings.py的两个配置

(1)headers:配置scrapy下载时的请求头

(2)robots协议:
全称:网络爬虫排除标准
作用:robots协议规定了,搜索引擎哪些数据可以爬取,哪些不可以爬取的协议文件
scrapy默认遵循robots协议的

4、运行命令
scrapy crawl spider_name [–nolog]
5、提取数据
参数repsonse有如下内容:

对于一个提取数据的方法,它外部不会提取出两个内容:
-
一个url
-
item
所以在spider组件中的所有的parse方法,将来只能yield出两个内容:
-
一个url
yield scrapy.Requests(
url=url,callback=函数, encoding =编码 ) -
item
yield item
-
6、编写item

item.py结构如下:注意:这些字段必须不能为空
导入使用相对路径

7、数据的保存
当在spider中yiled一个item时候,scrapy会将这个item交给pipelines.py来处理,想要利用上述功能,必须先要配置
(1)配置pipelines

(2)编存储数据的pipelines.py

三、pipelines管道原理

四、scrapy框架图

- Scrapy Engine(引擎): 负责 spider、ItemPipeline、Downloader、Scheduler 中间的通讯, 信号、数据传递等
- Scheduler(调度器): 它负责接受引擎发送过来的 Request 请求,并按照一定的方式进 行整理排列,入队,当引擎需要时,交还给引擎
- Downloader(下载器): 负责下载 Scrapy Engine(引擎)发送的所有 Requests 请求,并将 其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 spider 来处理
- spider(爬虫): 它负责处理所有 Responses,从中分析提取数据,获取 Item 字段需要 的数据,并将需要跟进的 URL 提交给引擎,再次进入Scheduler(调度器)
- Item Pipeline(管道): 它负责处理 spider 中获取到的 Item,并进行后期处理(详细分析、 过滤、存储等)
- Downloader Middlewares(下载中间件): 你可以当作是一个可以自定义扩展下载功能 的组件
- SpiderMiddlewares(spider中间件): 你可以理解为是一个可以自定义扩展和操作引擎 和 spider 中间通信的功能组件(比如进入 spider 的 Response 和从 spider 出去的 Requests)
五、Scrapy 中间件
简介: 中间件是Scrapy里面的一个核心概念,使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫
分类: 爬虫中间件和下载中间件
1、新建一个py文件

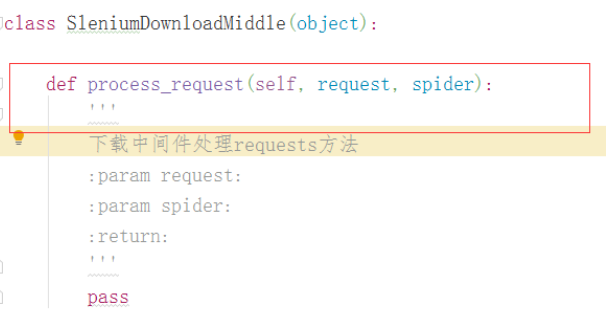
2、在文件新建一个类,这个必须有一个方法:process_request(),在process_request方法中进行对请求的处理
3、在settings.py中配置下载中间件

自定义下载(设置selenium下载):
from selenium import webdriver
from scrapy.http import HtmlResponse
class SleniumDownloadMiddle(object):
def process_request(self, request, spider):
'''
下载中间件处理requests方法
:param request:
:param spider:
:return:
'''
#dirver不能放到init方法中。
#当这个网站必须用selenium,就建议不考虑使用scrapy。
#但是使用selniunm请求次数比较有限,可以考虑使用selenium
driver = webdriver.Chrome()
driver.get(request.url)
driver.implicitly_wait(20)
html_str = driver.page_source
# - return None: continue processing this request --继续到下载器
# - or return a Response object--自定义下载--HtmlResponse
# - or return a Request object--设置代理
# - or raise IgnoreRequest: process_exception() methods of---过滤request
#body:响应正文
return HtmlResponse(url=request.url,body=html_str,request=request,ecoding='utf-8')
自定义setting配置
# 自定义配置
custom_settings = CUSTOM_SETTINGS
可以将我们自定义的一些配置字典覆盖scrapy的配置
import hashlib
CUSTOM_SETTINGS = {
#robotes协议
'ROBOTSTXT_OBEY': False,
#请求头
'DEFAULT_REQUEST_HEADERS' : {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
},
#下载中间件
'DOWNLOADER_MIDDLEWARES' : {
'douban_read.my_middle_wares.SleniumDownloadMiddle': 543,
},
#pipelines
'ITEM_PIPELINES' :{
'douban_read.pipelines.MongoPipeline': 300,
},
#数据库的url
'MONGO_URI' :'localhost',
#数据的名字
'MONGO_DATABASE' :'douban_read',
}
def get_md5(value):
return hashlib.md5(value.encode('utf-8')).hexdigest()
def update_to_mongo(db,collectionNmae,id,url,item):
'''
:param db: db引用
:param collectionNmae: 集合名
:param id: item的更新字典
:param url: 生成id字段
:param item:
:return:
'''
item[id] = get_md5(item[url])
db[collectionNmae].update({id:item[id]},{'$set':dict(item)},True)
print(item)
scrapy保存到mongo
import pymongo
from .my_settings import get_md5,update_to_mongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
'''
scrapy每个组件的入口
:param crawler:
:return:
'''
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
update_to_mongo(self.db,'小说','book_id','book_url',item)
return item
标识一个请求的方法
当我们发送二次请求是,可以说使用meta参数来标记一个请求:

在中间件中,当我们想要自定义下载时,可以通过这个参数来进行不同请求的不同处理:

scrapy设置代理的方法:
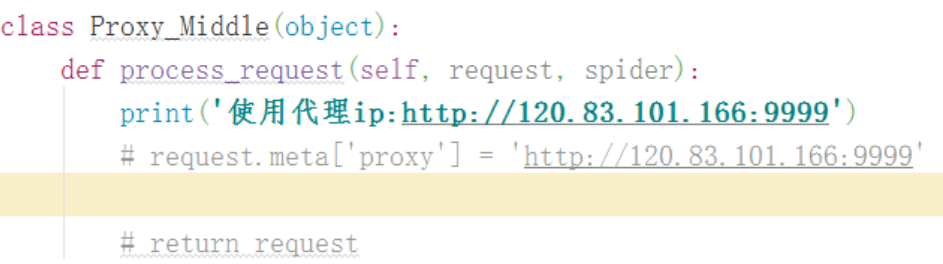
六、上市公司案例:
技术点:
-
start_request方法
# start_urls = ['http://www/'] #start_urls之所将url写入之后,就可以发送请求,原因是父类的start_request()的逻辑 #就是从start_urls里面遍历url,发送请求。 #start_urls的功能是父类的start_reuqest方法赋予的,# #如果start_request()被重写了,start_urls还有用吗? #当然没用》? def start_requests(self): ''' 这个第一个请求 #scrapy启动之后,会先找这个方法作为整个程序启动开始的url位置。 :return: ''' yield scrapy.Request( )/scrapy.FormReuqst() -
发送post请求:FormRequest—post对象
yield scrapy.FormRequest( url=ajax_url, formdata=formdata, callback=self.parse, encoding='utf-8' ) -
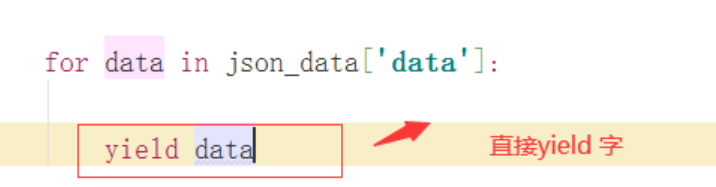
提取数据在spider中我们可以直接yield 一个字典,但是相比与item类,缺少了字段缺失校检。
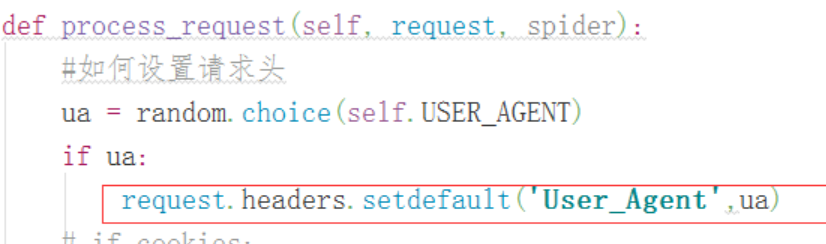
- 在中间件中设置请求头:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









