 PyTorch实战:Skip-gram 模型训练词向量
PyTorch实战:Skip-gram 模型训练词向量





 本文通过PyTorch实现Skip-gram算法,利用One-Hot Encoding处理词汇,隐藏层生成词向量,采用负采样进行模型训练,旨在获取词库中单词的词向量表示。
本文通过PyTorch实现Skip-gram算法,利用One-Hot Encoding处理词汇,隐藏层生成词向量,采用负采样进行模型训练,旨在获取词库中单词的词向量表示。
首先将文本中的词汇用One-Hot Encoding表示,根据需要设置Word Vector维度,输入层变量个数及one-hot vector的维度(代码中为30000),隐藏层单元个数即为Word Vector维度,输出与输入维度相同,也是One-Hot Encoding。
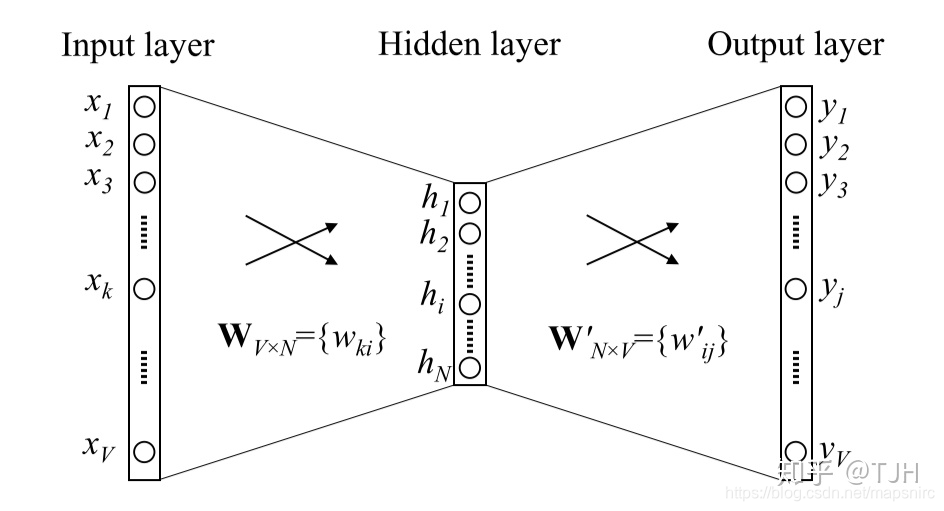
Skip-gram原理如图
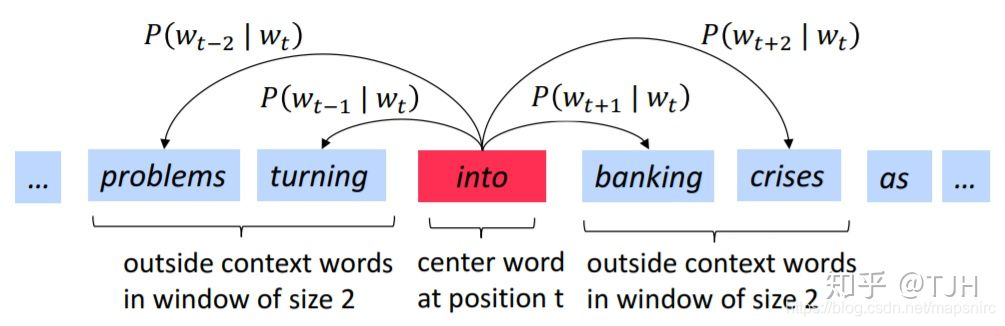
我们最终想要的是词库中单词的词向量表示,所以使用一层神经网络来实现Skip-gram算法,最后得到Word Embedding矩阵即可。
代码中使用负采样来进行模型训练,关于负采样,可以看看知乎上的这篇文章
word2vec中的负例采样为什么可以得到和softmax一样的效果
代码是跟着B站视频学习时敲的,用pytorch实现了训练,关于词向量算法原理的数学推导和assignment在学习CS224N的时候进行了实现,这里就直接用pytorch封装好的了。
USE_CUDA = torch.cuda.is_available()
# 为了保证实验结果可以复现,我们经常会把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
# 设定一些超参数
K = 100 # number of negative samples 负样本随机采样数量
C = 3 # nearby words threshold 指定周围三个单词进行预测
NUM_EPOCHS = 2 # The number of epochs of training 迭代轮数
MAX_VOCAB_SIZE = 30000 # the vocabulary size 词汇表多大
BATCH_SIZE = 128 # the batch size 每轮迭代1个batch的数量
LEARNING_RATE = 0.2 # the initial learning rate #学习率
EMBEDDING_SIZE = 100 # 词向量维度
LOG_FILE = "word-embedding.log"
# 文本转化成单词
def word_tokenize(text):
return text.split()
with open("text8.train.txt", "r") as fin: # 读入文件
text = fin.read()
text = [w for w in word_tokenize(text.lower())] # 分词
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1)) # 单词和对应出现次数的dict
vocab["<unk>"] = len(text) - np.sum(list(vocab.values())) # 文本中其他单词都是不常用单词
idx_to_word = [word for word in vocab.keys()] # 单词list
word_to_idx = {word:  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









