







 本文介绍了词向量模型,包括skip-gram和负采样的概念。skip-gram通过当前词预测上下文,负采样则用于优化大规模词汇表的softmax计算,提高训练效率。词向量模型利用上下文语境学习字词的相似性,解决了one-hot向量的不足。
本文介绍了词向量模型,包括skip-gram和负采样的概念。skip-gram通过当前词预测上下文,负采样则用于优化大规模词汇表的softmax计算,提高训练效率。词向量模型利用上下文语境学习字词的相似性,解决了one-hot向量的不足。
一、前言
请勿全文复制转载!尊重劳动成果!
在使用词向量之前,我们往往用one-hot向量来表示一个字词,这样有两个缺点:
① 维度过大。使用one-hot向量来表示字词,那么一个字词就需要一个词表大小的向量,而NLP任务中的词表往往是上万甚至上百万的,这会极大地增加神经网络中的参数数量。
② 距离一致。使用one-hot表示字词,会使得所有字词之间的相似性是一致的,而在我们的认知中,“苹果”和“梨子”要比“苹果”和“英语”更接近。
而词向量能将原本用one-hot表示的字词压缩到更小的维度,而且相似字词之间的距离更小。那词向量是如何表示字词的这种相似性的呢。很简单,词向量通过字词的上下文语境来表示这个字词,而相似的字词往往拥有相似的上下文语境。比如“苹果”和“梨子”可能都经常和“吃”、“水果”等词一起出现,那么“苹果”和“梨子”的词向量就会比较接近,而“英语”的上下文语境往往是“说”、“学习”等,那么“苹果”、“梨子”与“英语”之间就会差异较大。
要表达这种相似性,只需要建立这样一个模型:当输入“吃”的时候,模型输出“苹果”的概率较大,输出“英语”的概率较小。即输入一个字词,模型输出与这个字词共同出现的其他字词的概率。模型会学习到这种相似性,并将其体现到隐层权重之上。
显然,上面的模型与语言模型极其相似,语言模型的任务是根据上下文预测下一个字词。因此我们可以借用语言模型来训练词向量,词向量从一开始就和语言模型是密不可分的。
二、词向量
在开始讲解词向量之前,请你先思考这样一个问题:给你一个字词,需要你构建一个最简单的神经网络模型来预测下一个字词是什么。
对于这个问题,不使用词向量,不使用RNN,我想你最先能想出来的就是下面这个两层的全连接模型了。
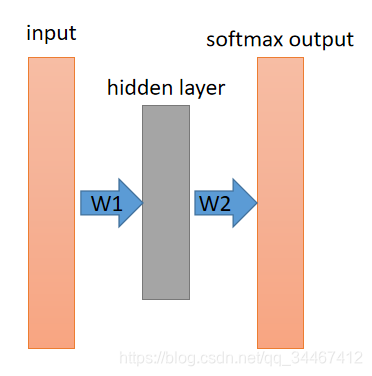
模型使用one-hot向量来表示一个字词,所以input层表示一个one-hot向量的输入,经过一个全连接层后得到一个隐藏层向量,在经过softmax层得到一个概率输出,概率最大对应的字词就是我们预测出的字词。
实际上,这已经是一个最简单的语言模型了,只不过最早的NNLM的input层是连续的多个字词,而且隐藏层要更多。
以 “小明不但喜欢吃梨子,还喜欢吃苹果” 为例,观察上述模型。对于这句话,我们可以获得数据集如下:
(小明,不但)
(不但,喜欢)
(喜欢,吃)
(吃,梨子)
(还,喜欢)
(喜欢,吃)
(吃,苹果)< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









