







【回归算法解析系列】时间序列回归(ARIMA, Prophet)
1. 时间序列回归:捕捉趋势与季节的博弈
时间序列回归作为数据分析领域中极为重要的一部分,主要聚焦于对具有时间依赖性的数据进行建模分析。这类数据在各个领域广泛存在,如金融市场中的股价走势、电商平台的销售数据以及电力系统中的负荷变化等。然而,对时间序列数据进行精准建模面临着诸多核心挑战。
1.1 趋势分解
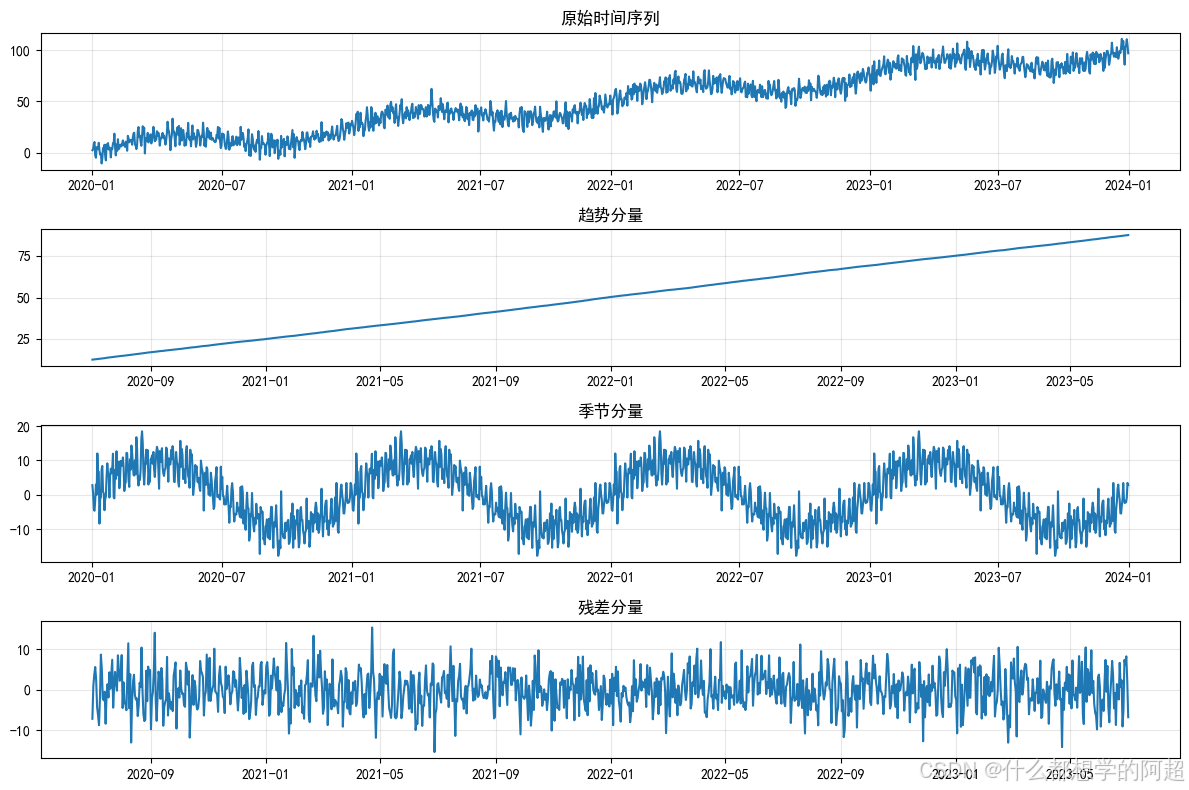
时间序列数据中往往蕴含着长期的增长或下降模式,这便是趋势。准确识别趋势对于理解数据的整体走向至关重要。例如,在科技行业,随着技术的不断进步,某类电子产品的销量可能呈现出逐年上升的趋势,这背后可能是由于消费者对新技术的需求增长以及产品的不断更新换代。通过有效的趋势分解方法,我们能够将这种长期趋势从复杂的数据中分离出来,以便更好地分析其他因素对数据的影响。在图1中,展示了一个典型的时间序列数据及其趋势分解结果,清晰地呈现出数据的上升趋势。
1.2 季节性捕捉
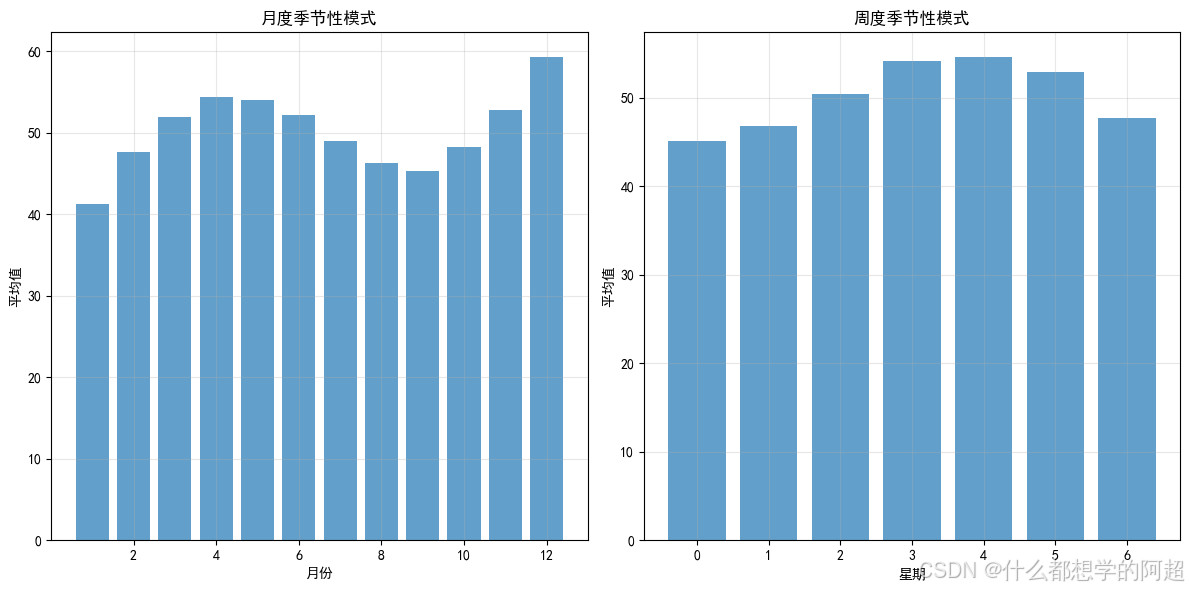
季节性是时间序列数据的另一个重要特征,它表现为数据在固定周期内的规律性波动,周期可以是日、周、年等。以零售业为例,每周周末通常是购物高峰期,销售额会明显高于工作日,这就形成了以周为周期的季节性波动;而在每年的节假日期间,如圣诞节、春节等,销售额更是会出现大幅增长,呈现出年度季节性特征。捕捉这些季节性变化对于准确预测数据至关重要。图2展示了某零售企业的月度销售额数据,其中明显呈现出每年年底销售额大幅增长的年度季节性特征,以及每月中旬相对稳定的小周期波动。
1.3 外生变量整合
除了数据自身的趋势和季节性,外部因素也常常对时间序列数据产生影响。例如,电商平台在促销活动期间,商品销量会显著增加;节假日的到来也会对旅游、餐饮等行业的客流量产生影响。在进行时间序列回归时,需要将这些外生变量有效地整合到模型中,以提高模型的预测准确性。例如,在分析某景区的游客流量时,将节假日安排、当地举办的大型活动等作为外生变量纳入模型,能够更全面地解释游客流量的变化。
1.4 ARIMA与Prophet对比
在时间序列回归领域,ARIMA和Prophet是两种被广泛应用的模型,它们各自具有独特的特性,适用于不同的场景。
| 特性 | ARIMA | Prophet |
|---|---|---|
| 数据要求 | 单变量,需严格平稳 | 支持多季节性和外生变量 |
| 季节处理 | 需手动指定季节参数 | 自动检测多种季节性 |
| 节假日支持 | 需人工编码外生变量 | 原生支持节假日效应 |
| 自动化程度 | 低(需人工调参) | 高(自动趋势拟合) |
ARIMA模型对数据的要求较为严格,通常适用于单变量时间序列,并且要求数据具有严格的平稳性。平稳性意味着时间序列的统计特性(如均值、方差等)不随时间变化。在处理季节性方面,ARIMA需要人工手动指定季节参数,这对使用者的专业知识和经验要求较高。此外,对于节假日等外生变量的处理,ARIMA需要通过人工编码将其作为外部变量引入模型。
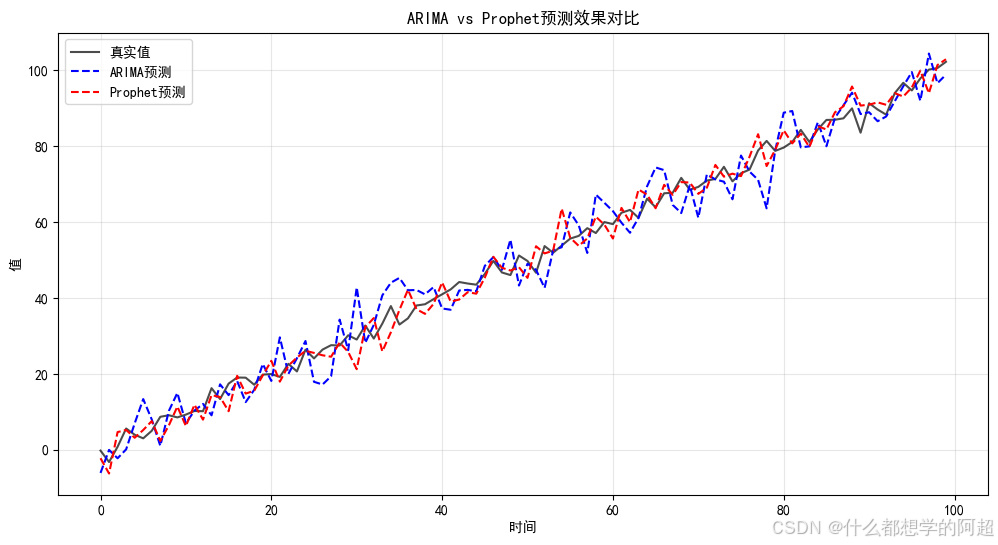
相比之下,Prophet模型具有更高的灵活性和自动化程度。它不仅支持多季节性和外生变量,能够同时处理多种不同周期的季节性波动以及多个外部因素的影响,而且能够自动检测数据中的多种季节性特征,无需人工手动设定复杂的季节参数。在节假日支持方面,Prophet原生支持节假日效应,使用者只需简单设置节假日信息,模型就能自动考虑其对数据的影响。在趋势拟合方面,Prophet能够自动适应数据的变化,找到较为合适的趋势模型,大大降低了使用者的操作难度。通过图3的对比示意图,可以更直观地看到ARIMA和Prophet在处理不同特性时的差异。
2. ARIMA模型:经典的三段式建模
2.1 数学原理
ARIMA(p,d,q)模型是时间序列分析中经典的模型之一,它由自回归(AR)、差分(I)和移动平均(MA)三部分组成。
自回归部分用历史值来预测当前值,其公式为:
[
y_t = c + \sum_{i=1}^p \phi_i y_{t - i} + \epsilon_t
]
其中,( y_t ) 是当前时刻 ( t ) 的值,( c ) 是常数项,( \phi_i ) 是自回归系数,( y_{t - i} ) 是过去 ( i ) 个时刻的值,( \epsilon_t ) 是白噪声误差项。这意味着当前时刻的值可以由过去 ( p ) 个时刻的值的线性组合加上一个随机误差项来表示。
差分部分通过 ( d ) 阶差分来实现时间序列的平稳性。公式为:
[
\Delta^d y_t = y_t - y_{t - 1} - \cdots - \Delta^{d - 1} y_{t - 1}
]
当时间序列存在明显的趋势时,通过差分操作可以消除趋势,使数据变得平稳,从而满足ARIMA模型的要求。例如,对于一个具有线性增长趋势的时间序列,一阶差分可以将其转化为平稳序列。
移动平均部分则利用历史误差来改进预测。公式为:
[
y_t = \mu + \epsilon_t + \sum_{i=1}^q \theta_i \epsilon_{t - i}
]
其中,( \mu ) 是均值,( \theta_i ) 是移动平均系数,( \epsilon_{t - i} ) 是过去 ( i ) 个时刻的误差项。移动平均部分通过考虑过去的误差情况,对预测结果进行修正,提高预测的准确性。
2.2 建模三步骤
ARIMA模型的建模过程主要包括三个关键步骤。
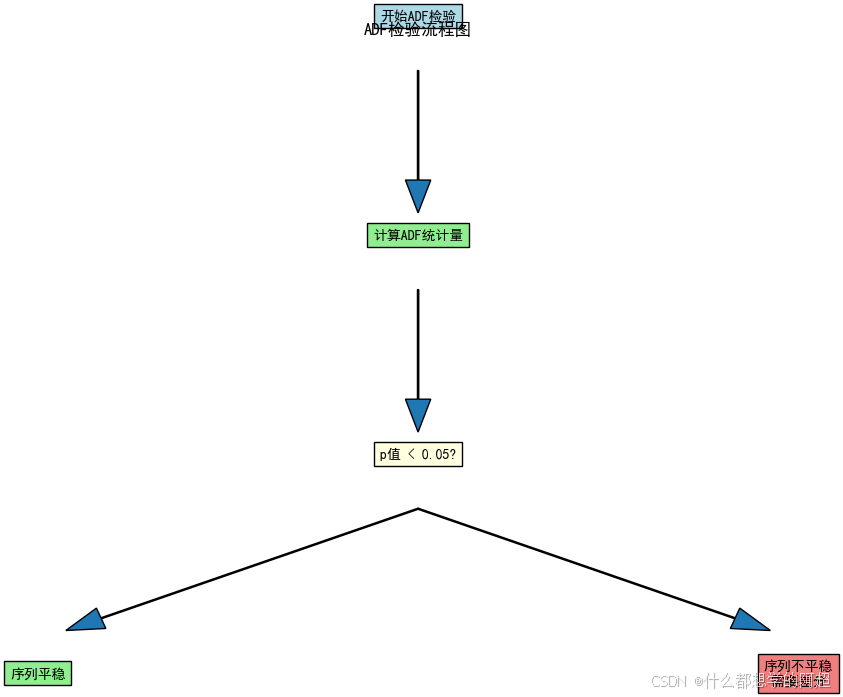
首先是平稳性检验,常用的方法是ADF检验。ADF检验通过计算统计量,并与给定的临界值进行比较,根据p值来判断时间序列是否平稳。一般来说,当p值小于0.05时,我们认为时间序列是平稳的。图4展示了ADF检验的流程示意图,清晰地说明了如何根据检验结果判断时间序列的平稳性。
其次是参数选择,通过自相关函数(ACF)和偏自相关函数(PACF)图来确定自回归阶数 ( p ) 和移动平均阶数 ( q ) 的值。ACF图反映了时间序列与其自身滞后值之间的相关性,而PACF图则在控制了中间滞后项的影响后,展示了时间序列与其自身滞后值之间的直接相关性。通过观察这两个图中相关性显著不为零的滞后阶数,可以初步确定 ( p ) 和 ( q ) 的值。图5和图6分别展示了一个时间序列的ACF图和PACF图,从图中可以看出在某些滞后阶数处,相关性较为显著,从而为参数选择提供依据。
最后是模型诊断,通过Ljung - Box检验来验证残差是否为白噪声。如果残差是白噪声,说明模型已经充分捕捉了时间序列中的信息,不存在未被解释的相关性。Ljung - Box检验计算出的Q统计量与给定的显著性水平下的临界值进行比较,当Q值对应的p值大于0.05时,认为残差是白噪声,模型诊断通过。图7展示了Ljung - Box检验的结果示例,以及如何根据结果判断模型的有效性。
3. 代码实战:销量预测
3.1 数据准备与平稳化
本案例使用某零售企业的销售数据进行销量预测。首先,加载数据并进行必要的预处理。
import pandas as pd
from statsmodels.tsa.stattools import adfuller
# 加载零售销售数据(包含趋势+月度季节性)
df = pd.read_csv('retail_sales.csv', parse_dates=['date'], index_col='date')
# 季节性分解可视化
from statsmodels.tsa.seasonal import seasonal_decompose
result = seasonal_decompose(df['sales' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











