







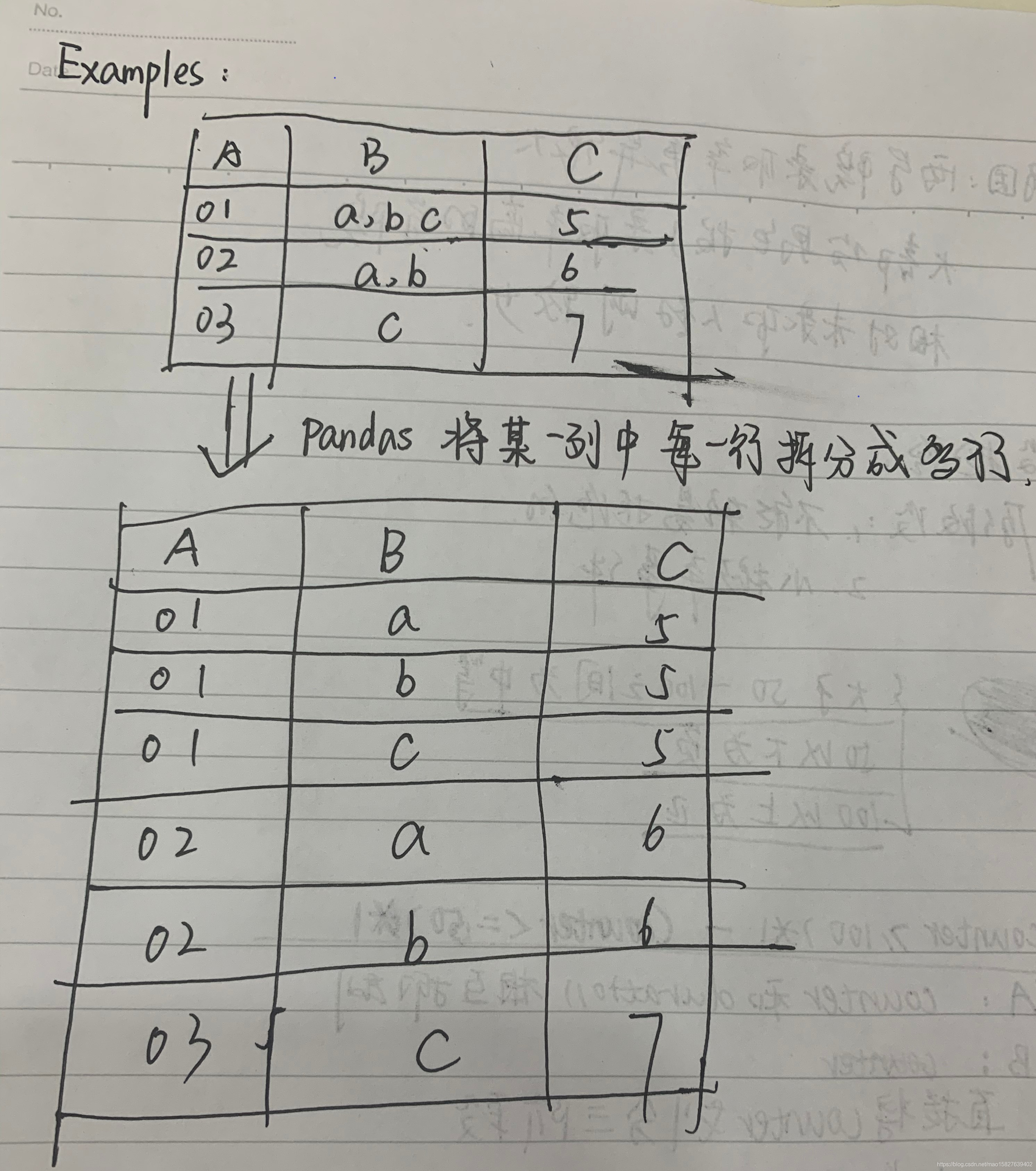
python 代码实现如下
import pandas as pd
a = [['01', 'a,b,c', 5], ['02','a,b', 10], ['03', 'b,c', 20]]
data = pd.DataFrame(a, index=['user1','user2','user3'], columns=["id", "type", "num"])
print(data)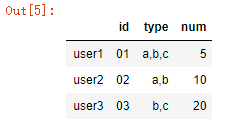
接下来,对type列分拆
data_type = data['type'].str.split(',', expand=True).stack().reset_index(level = 1,drop = True)
print(data_type)
#解析
data['type'].str.split(',', expand=True)#将type列中的数值分拆出来
data['type'].str.split(',', expand=True).stack()#将分拆的数值由行转为列
data['type'].str.split(',', expand=True).stack().reset_index(level = 1,drop = True)#将1级索引去除
将这个和原数据集合并
data_new = data.drop(['type'], axis=1).join(data_type.to_frame( name = 'type1'))
#等价于
data_new = data.drop(['type'], axis=1).join(data_type.rename('type1'))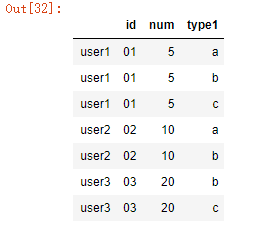
最后补充一个,将列转成行
data_new.groupby(['id','type1'])['num'].sum().unstack()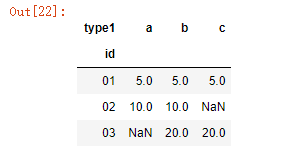
Python博大精深,不断积累玩得更遛,加油,希望对学习入门python得同学们有帮助,喜欢点赞哦!

















 3560
3560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









