






AI相关的名词
AI 领域名词繁多,按「核心概念→技术方向→应用场景→工具框架」分类整理
一、核心基础名词
- AI(Artificial Intelligence,人工智能):让机器模拟人类智能的技术总称(如学习、推理、决策)。
- 机器学习(ML,Machine Learning):AI 的核心分支,让机器通过数据学习规律,无需显式编程。
- 深度学习(DL,Deep Learning):机器学习的子集,基于神经网络(多层结构)处理复杂数据(如图像、语音)。
- 神经网络(Neural Network):模拟人脑神经元连接的数学模型,深度学习的核心载体。
- 数据标注(Data Annotation):给原始数据(图、文、音视频)打标签(如分类、框选),用于模型训练。
- 训练 / 推理(Training/Inference):训练是模型从数据中学习规律的过程,推理是训练好的模型处理新数据、输出结果的过程。
- 算力(Computing Power):支撑 AI 模型训练 / 推理的硬件计算能力(常用 GPU、TPU 提供)。
二、关键技术方向名词
- 监督学习(Supervised Learning):用带标签的数据训练模型(如分类、回归),例:垃圾邮件识别、房价预测。
- 无监督学习(Unsupervised Learning):用无标签数据发现隐藏规律(如聚类、降维),例:用户行为分组、数据压缩。
- 强化学习(Reinforcement Learning):模型通过 “试错” 获取奖励信号,优化决策(如自动驾驶、游戏 AI)。
- 半监督学习(Semi-Supervised Learning):结合少量标签数据和大量无标签数据训练(平衡数据成本和效果)。
- 迁移学习(Transfer Learning):将已训练好的模型知识,迁移到新的相关任务中(减少训练成本)。
- 生成式 AI(Generative AI):能生成全新内容(文本、图像、音频)的技术,例:ChatGPT、Midjourney。
- 大语言模型(LLM,Large Language Model):基于海量文本训练的大型语言模型(如 GPT、LLaMA、文心一言)。
- 计算机视觉(CV,Computer Vision):让机器 “看懂” 图像 / 视频(如目标检测、图像分割、人脸识别)。
- 自然语言处理(NLP,Natural Language Processing):让机器理解和处理人类语言(如翻译、摘要、情感分析)。
- 语音识别 / 合成(ASR/TTS):ASR 是语音转文字,TTS 是文字转语音。
- 自动驾驶(Autonomous Driving):结合 CV、传感器技术,让车辆自动行驶(分级:L0-L5)。
三、应用场景相关名词
- AGI(Artificial General Intelligence,通用人工智能):具备人类级别的全面智能,能处理任意任务(目前未实现)。
- 弱人工智能(Narrow AI):专注于单一任务的 AI(如语音助手、推荐系统),当前主流技术。
- 推荐系统(Recommendation System):根据用户偏好推荐内容(如电商商品、短视频)。
- Chatbot(聊天机器人):通过 NLP 与人类对话的智能交互系统(如客服机器人、AI 助手)。
- AIGC(AI Generated Content,人工智能生成内容):由 AI 生成的文本、图像、视频、代码等内容。
- 人机交互(HCI,Human-Computer Interaction):研究人类与机器的交互方式(如语音控制、手势识别)。
四、工具、框架与平台名词
- 框架(Framework):简化 AI 模型开发的工具库,例:TensorFlow(谷歌)、PyTorch(Meta)、MindSpore(华为)。
- GPU/TPU:高性能计算芯片,GPU 用于通用深度学习训练 / 推理,TPU 是谷歌专为深度学习设计的芯片。
- 开源模型(Open-Source Model):公开代码和权重的 AI 模型(如 LLaMA 2、Stable Diffusion)。
- API/SDK:第三方提供的 AI 功能接口(如 OpenAI API、百度智能云 SDK),无需自研模型即可调用。
- MLOps:机器学习运维,涵盖模型开发、训练、部署、监控的全流程管理。
- 大模型微调(Fine-Tuning):基于预训练大模型,用少量专属数据进一步训练,适配特定任务(如行业问答、企业知识库)。
- Prompt Engineering(提示工程):通过设计优化输入指令(Prompt),让 AI 模型输出更符合需求的结果。
五、常见指标与术语
- 准确率(Accuracy):模型预测正确的样本占比(分类任务核心指标)。
- 召回率(Recall):实际为正类的样本中,被模型正确预测为正类的比例(如漏检率相关)。
- F1-Score:准确率和召回率的调和平均数,综合评估分类效果。
- 损失函数(Loss Function):衡量模型预测结果与真实标签的差距(训练目标是最小化损失)。
- 迭代(Iteration):模型训练中,用一批数据更新一次参数的过程。
- 批次(Batch Size):每次训练时输入模型的数据样本数量。
- 过拟合(Overfitting):模型在训练数据上表现极好,但在新数据上泛化能力差(如死记硬背而非学习规律)。
- 欠拟合(Underfitting):模型未能充分学习训练数据的规律,表现较差(如模型过于简单)。
- RAG(Retrieval-Augmented Generation):检索增强生成,一种结合「检索外部知识」和「大模型生成」的技术架构 —— 先从知识库中检索与问题相关的精准信息,再将信息作为上下文传给大模型,让生成结果更准确、可追溯(解决大模型 “知识过期”“胡编乱造” 问题)
- MCP(Model Control Program / Management Control Platform):模型控制程序 / 管理控制平台(需结合场景区分):1. 技术场景:控制硬件 / 软件模型运行的核心程序;2. AI 场景:大模型生命周期管理平台(涵盖训练、部署、监控、权限控制)
- Graph(Graph Data Structure / Graph AI):图(图数据结构 / 图人工智能):1. 基础概念:由「节点」(实体)和「边」(关系)组成的数据结构,擅长表达复杂关联;2. AI 方向:基于图结构的机器学习技术(图神经网络 GNN 是核心)
AI 应用搭建的认知纠正:
- 误区:认为简单用 dify、coze 搭建工作流、上传少量数据、能回答基础问题就是可用的 AI 应用;
- 真相:dify、coze 仅适用于产品经理快速搭建 MVP(最小可行产品),生产级应用需进一步优化。
- 核心技术与实践重点:
- 核心架构:Graph RAG(图结构 + RAG)、Agentic RAG(增强型 RAG)、RAG Agent 工作流;
- 关键能力:上下文工程、生产级 Prompt 设计、模型微调、多 Agent 协同;
- 知识库优化:混合知识库检索、文本切分策略(固定长度切分、基于内容结构动态分块、递归切分)。
- 落地痛点与优化方向:针对知识检索慢、结果排序不佳、检索精度不足等问题,提供对应的优化思路。
核心结论
企业级 AI 应用(尤其是 RAG 相关)的落地,不能仅依赖低代码工具快速搭建,需结合 Graph 图结构、动态文本切分、多 Agent 等技术,优化检索精度与效率,同时配套生产级 Prompt 设计和模型微调,才能实现从 MVP 到生产级的落地。
模型供应商
| 模型供应商 | 主要特点 | 优势 | 备注 |
|---|---|---|---|
| OpenAI | GPT 系列(如 GPT-4),具备强文本生成与理解能力 | 灵活性高、适用多场景;是大模型界事实标准 | 暂停国服 API 服务,需通过 Azure 接入 |
| 阿里百炼 | 提供多模型(如通义千问系列) | 性能接近 GPT-4;API 价格低;支持企业迁移方案 | 面向企业用户;新用户享超 5000 万 Tokens+4500 张图片的免费额度 |
| DeepSeek | 开源大模型,支持多语言 | 推理 / 编码表现优;社区活跃;支持多样化应用 | 性价比高(输入价 0.1 元 / 百万 Tokens);敏感词封号严格(缓存未命中时) |
| 智谱清言 | 基于 GLM 架构,支持多轮对话与复杂指令处理 | 指令理解能力强;支持多场景定制化方案 | 模型全面;国庆月活动:用户可低价调用所有模型,每位用户获赠 1 亿 Tokens 额度 |
| 硅基流动 | 专注 AI 基建,提供 SiliconCloud 平台 | 高效推理、多模态支持;降低使用门槛,提升开发效率 | 面向技术开发者;提供开源模型 API(如 Qwen2、GLM4 等),多个模型永久免费 |
| Ollama | 支持本地部署,集成多开源模型,隐私保护优先 | 强调用户隐私与自主性 | 需要较高硬件配置以支持本地部署 |
什么是 Spring AI Alibaba?
Spring AI Alibaba 基于 Spring AI 开源项目构建,作为 AI 应用程序的基础框架,定义了包括模型适配、聊天交互、提示词管理、工具调用等概念抽象与实现:
- 提供多种大模型服务对接能力,包括 OpenAI、Ollama、阿里云 Qwen 等
- 支持的模型类型包括聊天、文生图、音频转录、文生语音等
- 支持同步和流式 API,在保持应用层 API 不变的情况下支持灵活切换底层模型服务,支持特定模型的定制化能力(参数传递)
- 支持 Structured Output,即将 AI 模型输出映射到 POJOs
- 支持矢量数据库存储与检索
- 支持函数调用 Function Calling
- 支持构建 AI Agent 所需要的工具调用和对话内存记忆能力
- 支持 RAG 开发模式,包括离线文档处理如 DocumentReader、Splitter、Embedding、VectorStore 等,支持 Retrieve 检索
以上原子能力可让您实现 AI 应用的快速开发,例如 “通过文档进行问答” 或 “通过文档进行聊天” 等。
Spring AI 官网:https://spring.io/projects/spring-ai#overview
Spring AI Alibaba 官网:https://java2ai.com
Spring AI Alibaba 仓库:https://github.com/alibaba/spring-ai-alibaba
Spring AI Alibaba 官方示例仓库:https://github.com/springaialibaba/spring-ai-alibaba-examples
Spring AI 1.0 GA 文章:https://java2ai.com/blog/spring-ai-100-ga-released
Spring AI 仓库:https://github.com/spring-projects/spring-ai
为什么选择spring ai alibaba
| 对比维度 | Spring AI Alibaba(阿里版 Spring AI) | Spring AI(官方版) | LangChain4J |
|---|---|---|---|
| Spring Boot 集成 | 原生支持(无缝适配 Spring 生态) | 原生支持(Spring 官方出品) | 社区适配(第三方适配 Spring Boot) |
| 文本模型 | 支持主流模型,可扩展 | 支持主流模型,可扩展 | 支持主流模型,可扩展 |
| 音视频 / 多模态 / 向量模型 | 支持多模态能力 | 支持多模态能力 | 支持多模态能力 |
| RAG(检索增强生成) | 模块化 RAG(开箱即用的 RAG 组件) | 模块化 RAG(官方提供 RAG 工具链) | 模块化 RAG(社区维护的 RAG 能力) |
| 向量数据库 | 支持主流库(含阿里云 ADB、OpenSearch 等) | 支持主流向量数据库 | 支持主流向量数据库 |
| MCP 支持 | 支持(含 Nacos MCP Registry) | 支持 | 支持 |
| 函数调用 | 支持(集成 20 + 官方工具) | 支持 | 支持 |
| 提示词模板 | 硬编码,无声明式注解 | 硬编码,无声明式注解 | 声明式注解(通过注解定义模板) |
| 提示词管理 | 支持 Nacos 配置中心(集中管理提示词) | 无 | 无 |
| Chat Memory(对话记忆) | 优化支持 JDBC、Redis、ElasticSearch | 支持 JDBC、Neo4j、Cassandra | 多种实现适配 |
| 可观测性 | 支持,可接入阿里云 ARMS(监控告警) | 支持 | 部分支持 |
| 工作流 Workflow | 支持,兼容 Dify、百炼 DSL | 无 | 无 |
| 多智能体 Multi-agent | 支持,官方提供通用智能体实现 | 无 | 无 |
| 模型评测 | 支持 | 支持 | 支持 |
| 社区活跃度 / 文档健全性 | 官方社区,活跃度高 | 官方社区,活跃度高 | 个人发起社区 |
| 开发提效组件 | 丰富(含调试、代码生成工具) | 无 | 无 |
| Example 仓库 | 丰富,活跃度高 | 较少 | 丰富,活跃度高 |
怎么确定 Spring Al Alibaba与Spring AI、SpringBoot 版本的兼容关系
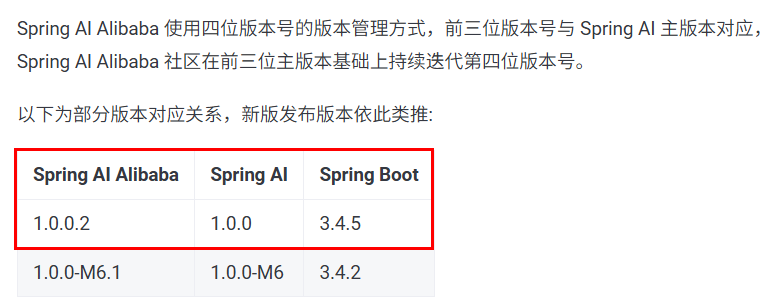
具体可以查看文档说明:常见问题解答-阿里云Spring AI Alibaba官网官网
快速开始
我们使用的是阿里云百炼平台+deepseek
https://bailian.console.aliyun.com/ 这个是阿里云百炼平台的地址
大模型调用三件套:
-
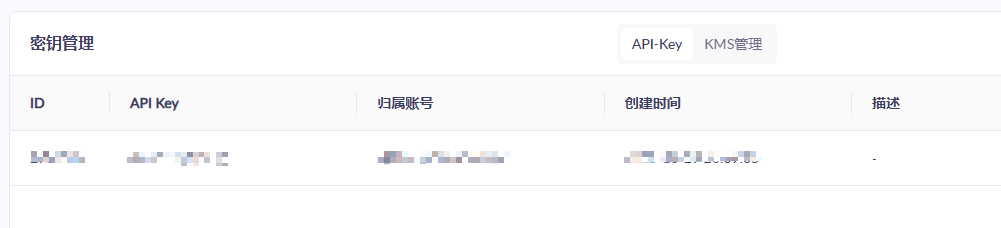
API key
创建自己的密钥
-
调用地址

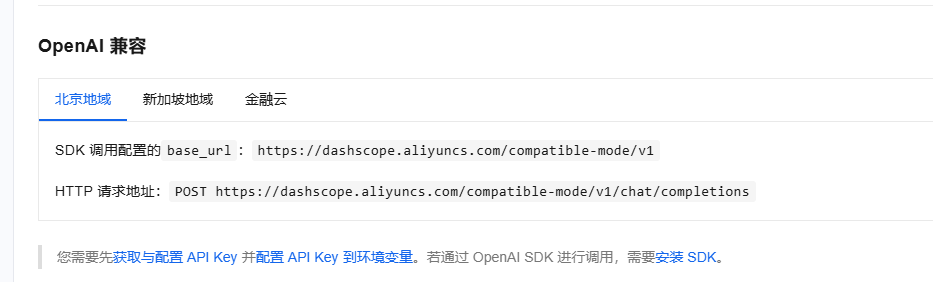
-
大模型名称
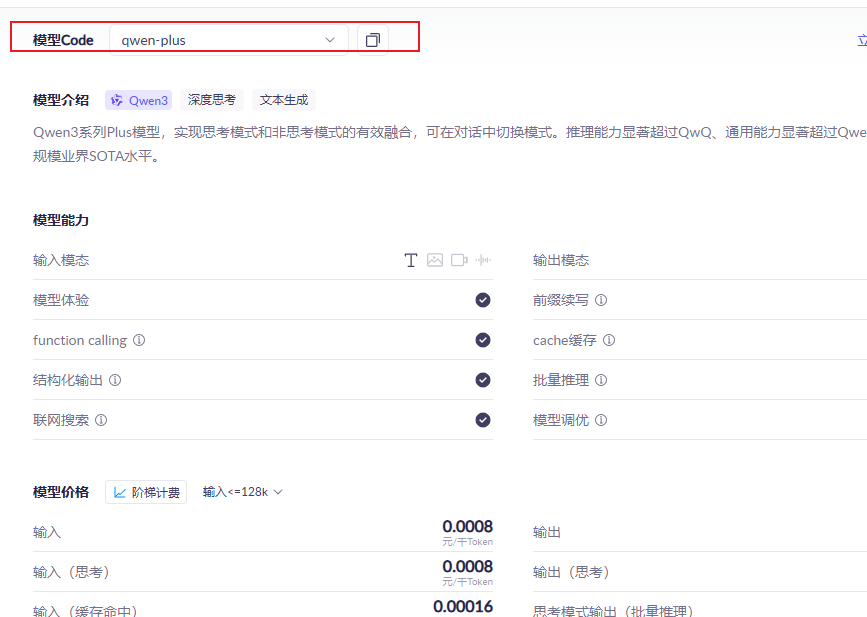
IDEA工具中建project父工程
使用 bom 管理依赖版本
出处:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









